Conoce GKE cost allocation y cómo usar sus datos junto con las funciones de asignación de costos de DoiT Cloud Intelligence™ para obtener una vista granular de tu gasto en GKE.

Conseguir suficiente visibilidad sobre el gasto en Kubernetes es un reto tan viejo como el propio Kubernetes.
La asignación dinámica de recursos y el carácter efímero de los contenedores complican atribuir costos a aplicaciones o servicios concretos. A esto se suma que los recursos se comparten entre varios componentes.
Aun así, lograr visibilidad de costos en Kubernetes es clave para gestionar bien tanto los recursos como el presupuesto.
Para resolver estos retos, Google Cloud lanzó GKE cost allocation a finales del año pasado, una función que permite ver un desglose detallado de los costos de los clusters.
En este post repasamos qué es GKE cost allocation y cómo aprovechar sus datos con las funciones de asignación de costos de DoiT Cloud Intelligence para obtener una vista granular de tu gasto en GKE.
En concreto, veremos cómo una empresa hipotética de gaming podría organizar sus costos de GKE para mapearlos a sus juegos, repartir los costos compartidos entre ellos y, finalmente, entender cómo se desglosan los costos de cada juego por entorno.
Qué es GKE cost allocation
GKE cost allocation es el método recomendado por Google Cloud para obtener información de facturación de los clusters. Frente a su antecesor, GKE usage metering, con GKE Cost Allocation se asignan los costos del cluster a los usuarios de forma mucho más sencilla y se pueden ver los costos de cluster y namespace junto con los de otros servicios de Google Cloud, algo que con usage metering no era posible. Además, Google Cloud planea que reemplace a GKE Usage Metering en el futuro.
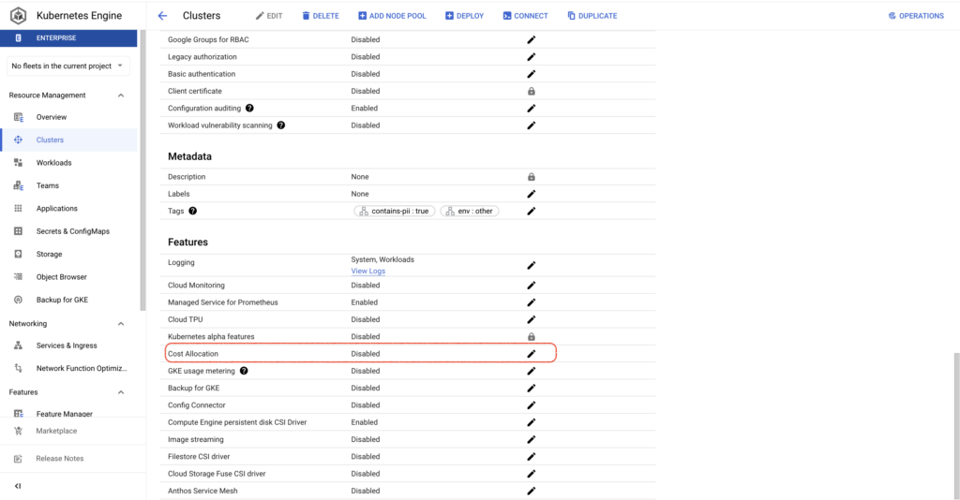
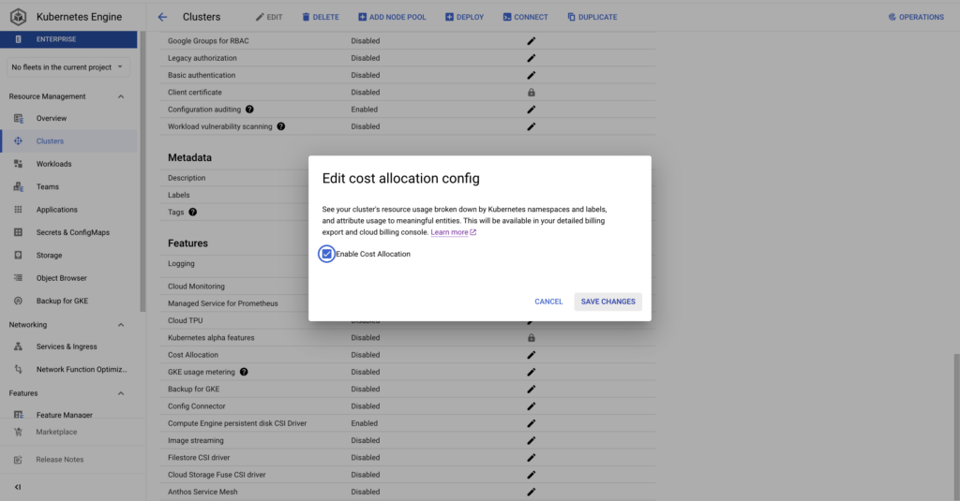
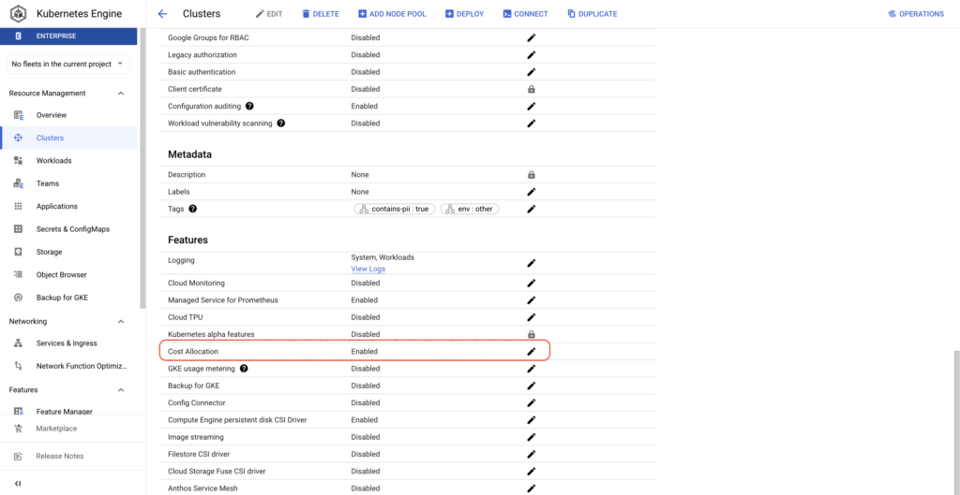
También es mucho más sencillo activar GKE cost allocation que GKE usage metering: basta con un comando de gcloud o marcar una casilla en la Google Cloud Console por cada cluster. Una vez activado, se crea un dataset de BQ con métricas de CPU, consumo de memoria y discos de los workloads que corren en los clusters.
Así resulta fácil ver los costos de cluster y namespace, además de información sobre los recursos que tengan GKE Labels asociados.
Con GKE cost allocation activado en tus clusters, podrás responder preguntas como:
- ¿Qué tenant está generando qué parte de los costos del cluster?
- ¿Cómo se relacionan los costos fuera del cluster (CloudSQL, GCS, etc.) con los costos dentro del cluster?
- ¿Cuánto cuesta mi aplicación de backend?
Por último, una vez activado, la información granular de facturación de tus costos de cluster y namespace también se vuelca en DoiT Cloud Intelligence, lo que permite hacer asignaciones de costos más complejas con esos datos. Veamos un escenario de ejemplo en la siguiente sección.

Mapear los costos de GKE a tus agrupaciones de negocio
El primer paso para hacer una asignación de costos es definir las agrupaciones de negocio a las que quieres asignarlos. En DoiT Cloud Intelligence, esto se hace mediante Attributions. Las Attributions te permiten agrupar recursos cloud y organizar los costos según la lógica con la que quieras asignarlos.
Imaginemos que somos una empresa hipotética de gaming, con varios juegos disponibles para nuestros usuarios.
Quizá nos interese asignar recursos a los distintos juegos y también a los entornos en los que corren.
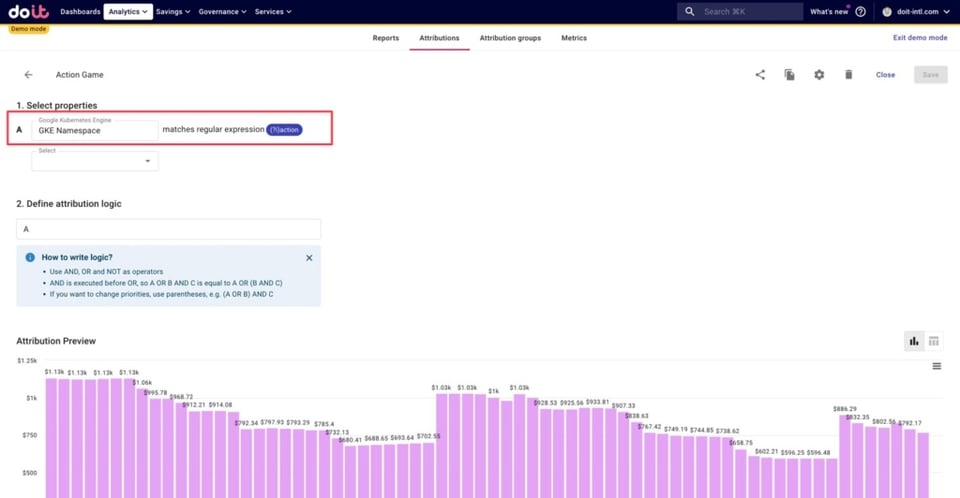
A continuación, definimos cualquier costo de GKE relacionado con uno de nuestros juegos —un juego de acción— como cualquier namespace que contenga la palabra "action". Usar regex aquí nos permite capturar los costos de recursos de cualquier namespace nuevo relacionado con ese juego que se cree en el futuro, sin tener que actualizar la Attribution manualmente.
Además, definimos los clusters relacionados con entornos de producción, así como los de dev, staging y beta. Abajo se muestra un ejemplo de cómo definir los clusters de producción, usando regex para capturar todos los clusters cuyo nombre contenga la palabra "prod".
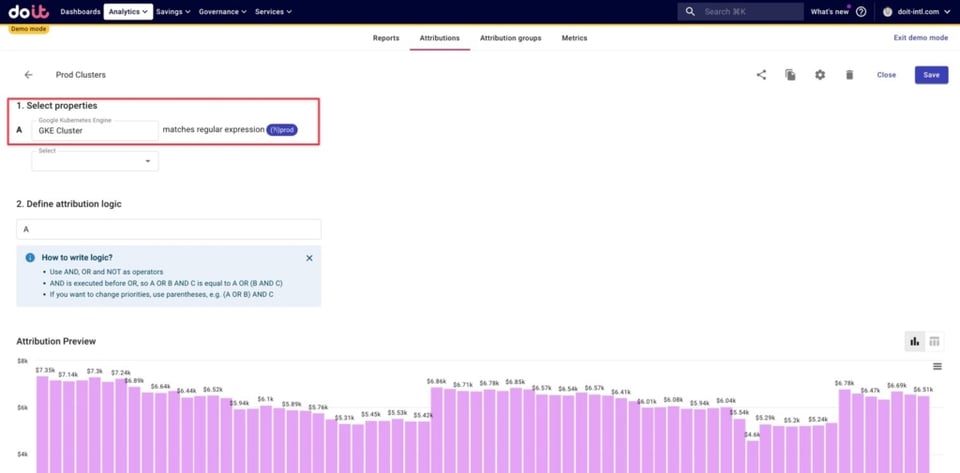
Organizar nuestras agrupaciones de negocio
El siguiente paso es organizar las Attributions relacionadas en Attribution Groups. Estos grupos nos permiten repartir costos compartidos entre un conjunto de Attributions y, además, desglosar un conjunto de Attributions por otro. En la siguiente sección haremos ambas cosas.
Abajo creamos un Attribution Group llamado "Games" con Attributions que representan:
- Cuatro juegos que opera nuestra empresa hipotética
- Costos compartidos dentro del cluster y costos no atribuidos, entre ellos:
- kube:system y kube:system-overhead: componentes/namespaces del sistema de K8s. (kube-system es el namespace, y Google genera además esta métrica adicional para expresar el overhead)
- kube:unallocated: recursos que no son solicitados ni por los workloads ni para overhead del sistema.
- goog-k8s-unknown: básicamente, un error de la asignación de costos que ocurre cuando se inicia una nueva VM de Compute o el cluster escala (no se pudo procesar el SKU)
- goog-k8s-unsupported-sku: un SKU existente, pero no soportado (por ejemplo, instancias E2)
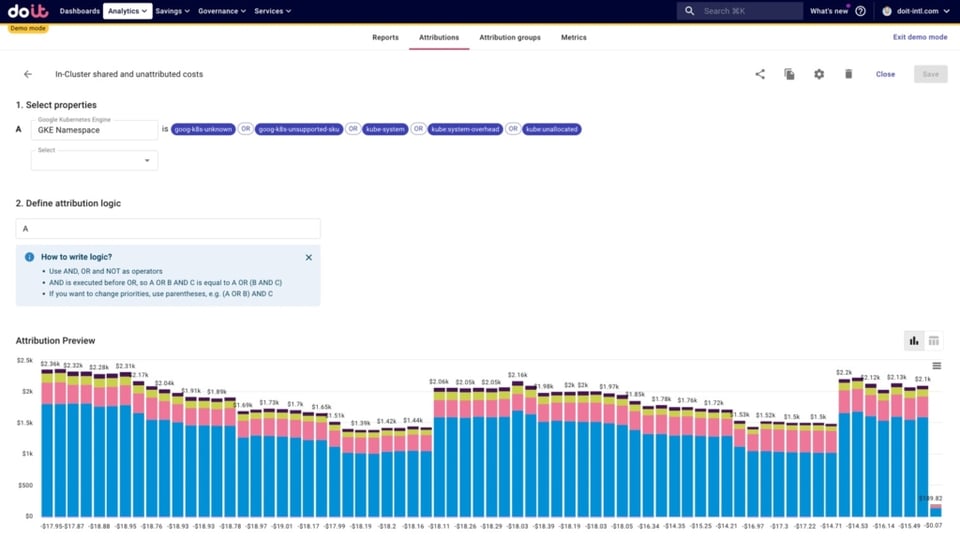
- Costos compartidos fuera del cluster: costos de recursos no Kubernetes que corren en Google Cloud por fuera de Kubernetes y que utilizan las apps desplegadas en el cluster
- bases de datos como Cloud SQL o BigQuery
- almacenamiento de objetos como Google Cloud Storage
- colas de mensajes como Pub/Sub, Kafka, etc.
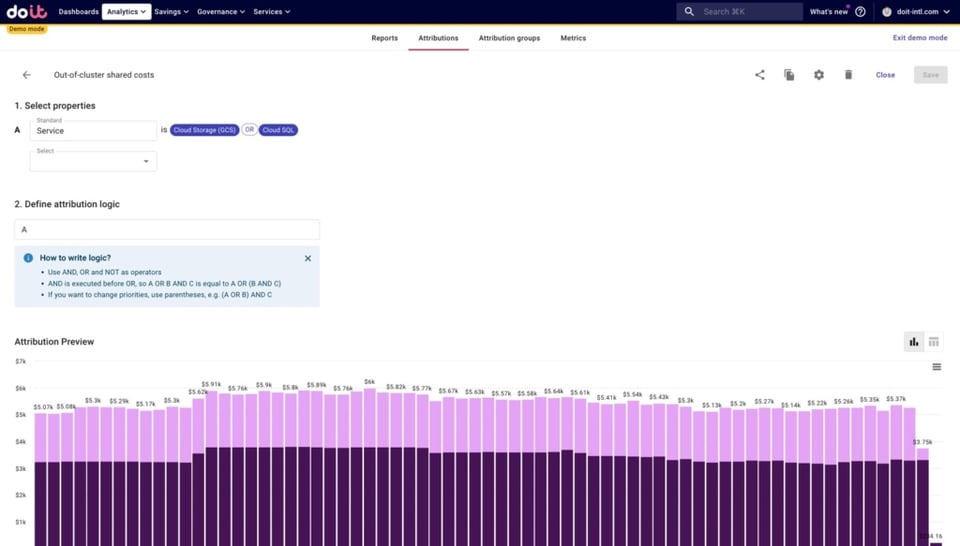
- Cualquier cosa que no quede capturada en las Attributions anteriores
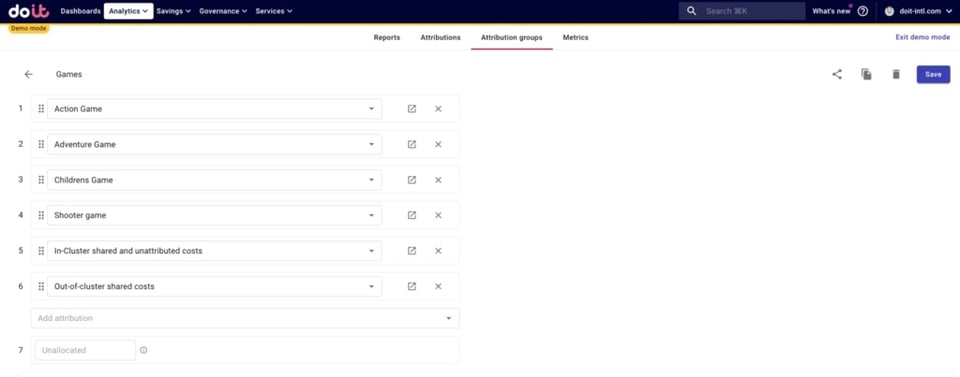
Incluimos las Attributions que no son de juegos porque son costos compartidos que en la siguiente sección querremos repartir entre los juegos.
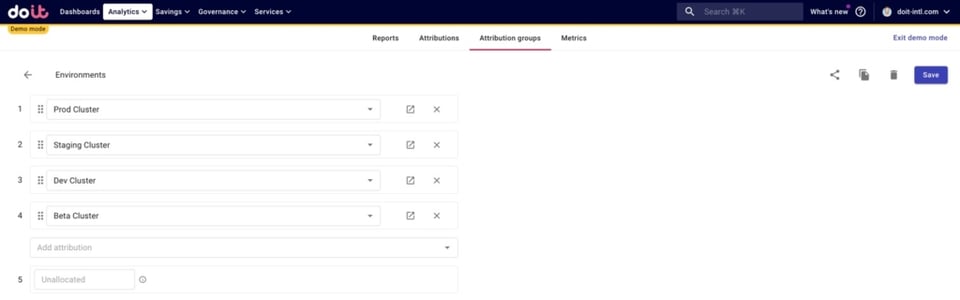
De forma similar, creamos un Attribution Group con todos nuestros entornos.
Lo hacemos así porque, una vez repartidos los costos compartidos entre los juegos, querremos saber cuánto se está gastando en cada entorno por cada juego.
Repartir los costos compartidos dentro y fuera del cluster
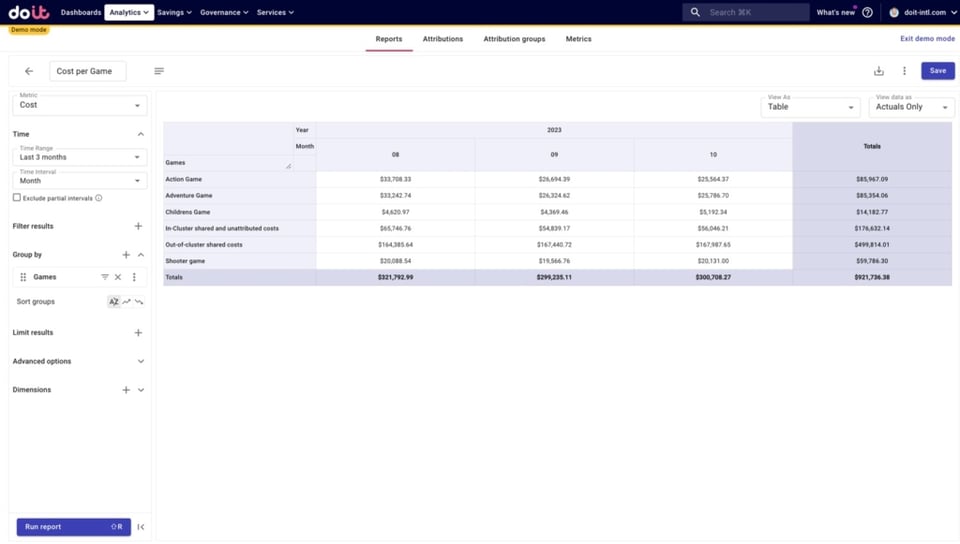
Primero, ejecutamos un reporte para examinar nuestro Attribution Group con los costos de los juegos y los compartidos.
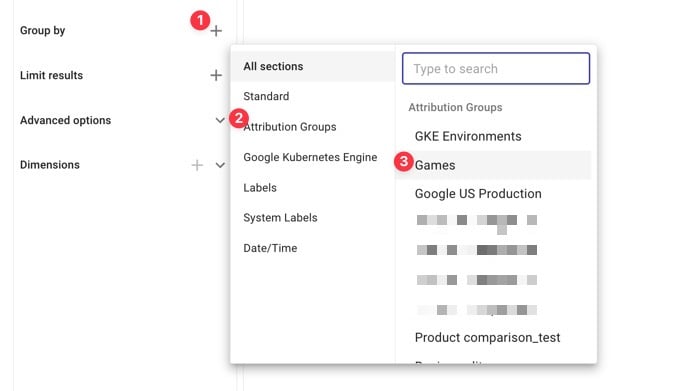
Para hacerlo, seguimos estos pasos:
Después repartimos nuestros dos costos compartidos —Costos compartidos dentro del cluster y no atribuidos y Costos compartidos fuera del cluster— entre los juegos.
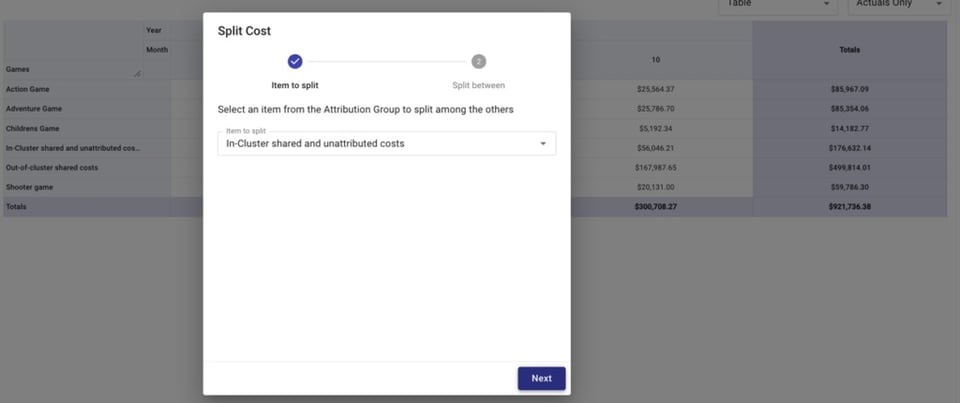
Podemos repartir estos costos en partes iguales, de forma proporcional al gasto relativo de cada juego frente al total, o por un monto personalizado.
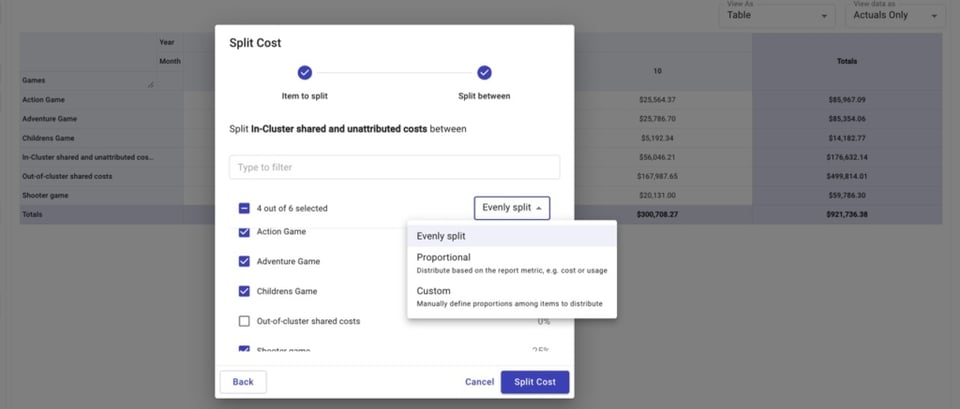
Hecho esto, para cada juego podemos ver:
- El costo de operar ese juego
- Su parte de los costos compartidos dentro del cluster / no atribuidos
- Su parte de los costos compartidos fuera del cluster
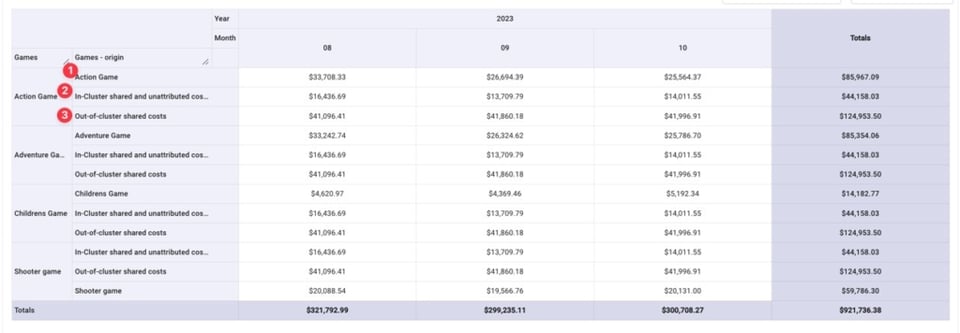
Para simplificar, vamos a agregar las tres líneas en un único costo por juego.
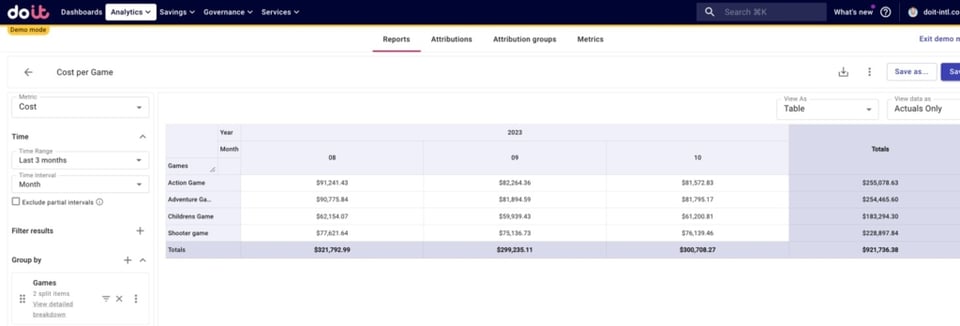
Desglosar los costos de cada juego por entorno
Ya estamos listos para ver cómo se desglosan los costos totales de cada juego por entorno, agregando nuestro Attribution Group "GKE Environments" al desglose.
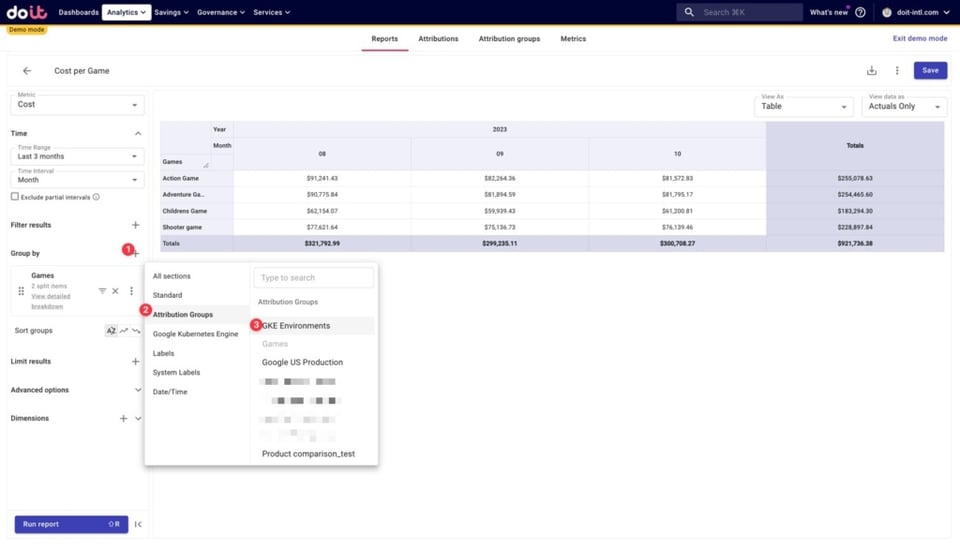
Abajo se ve cómo se desglosan los costos de cada juego según las Attributions de entornos que creamos antes, junto con los costos no asignados. Estos costos no asignados son recursos que no quedan capturados en ninguna de las Attributions de los Attribution Groups que estamos usando aquí.
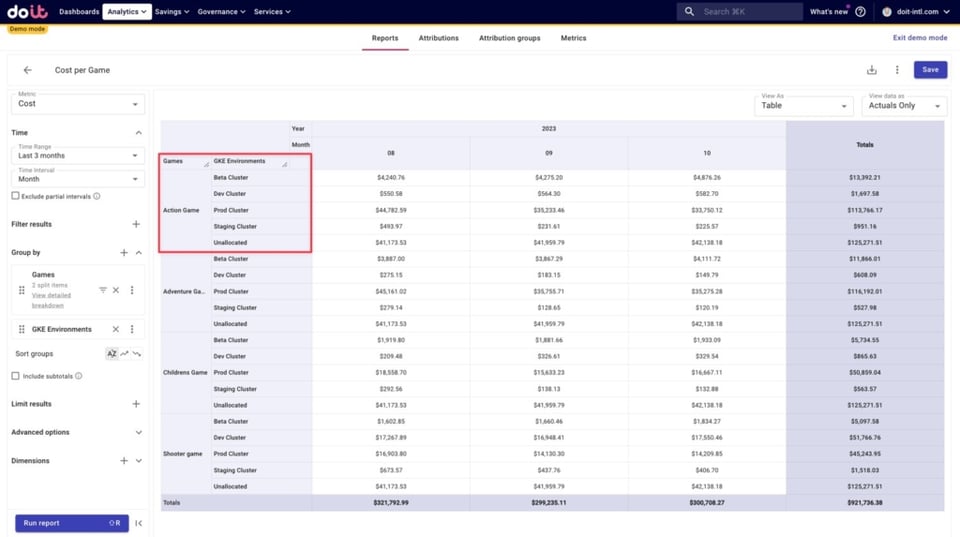
Podemos profundizar en los costos no asignados para ver qué los provoca y, a partir de ahí, modificar las Attributions existentes para incluir esos recursos.
Filtremos solo los costos no asignados del Attribution Group "GKE Environments" y agreguemos "Service" al desglose.
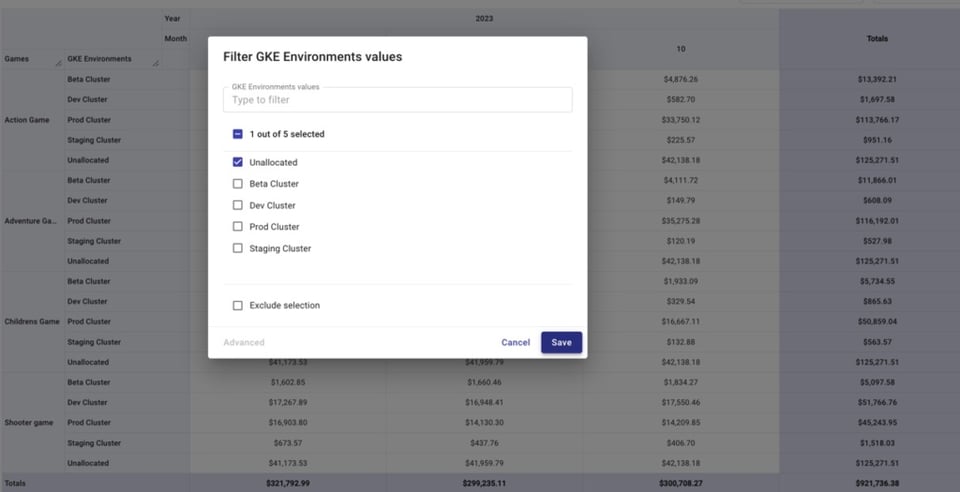
Esto te ayuda a identificar recursos sin labels que pertenecen a servicios cuyos recursos sí pueden etiquetarse, o proyectos que no están incluidos en alguna Attribution en la que deberían estarlo.
Abajo vemos que hay algunos costos de GCE, GCS y Cloud SQL que no están incluidos en nuestros Attribution Groups.
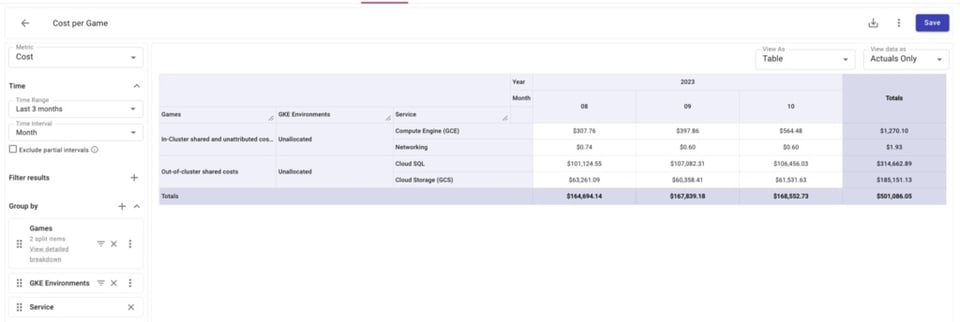
Y al hacer zoom en los recursos no asignados de Compute Engine, podemos identificar exactamente cuáles no están incluidos. Con esa información, quizá nos convenga revisar nuestras Attributions para incorporarlos.
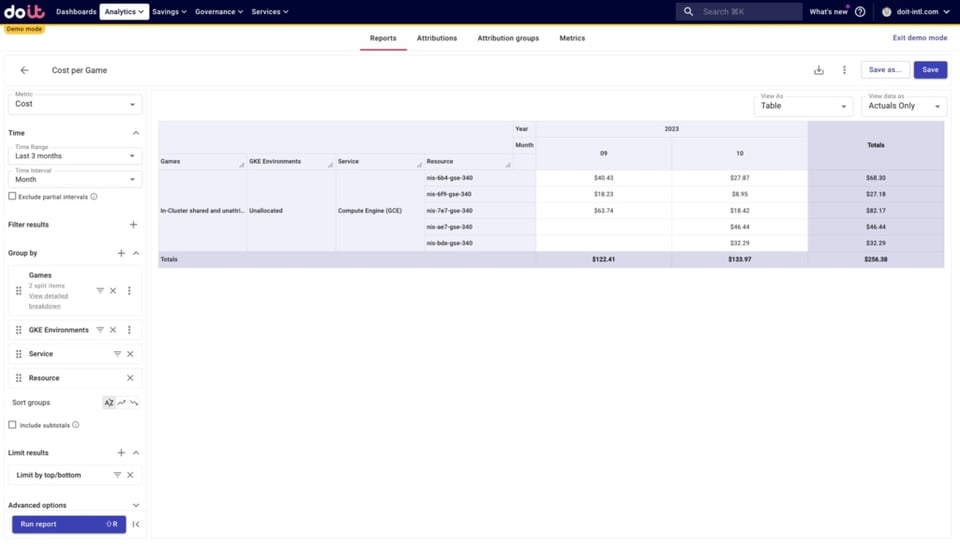
Así es como puedes reducir los costos no asignados y ganar visibilidad sobre tu gasto en GKE.
Conclusión
Por lo general, si querías entender cómo impactan tus workloads de Kubernetes en la factura total de la nube, tenías que recurrir a herramientas como Cast AI o Kubecost.
Aunque estos productos son más robustos que GKE cost allocation, Google Cloud destaca entre los hyperscalers porque trae buena parte de la funcionalidad de visibilidad de costos integrada y fácil de habilitar en los clusters.
Después puedes usar los datos de GKE cost allocation, como hicimos arriba, para tener mayor transparencia sobre cómo se desglosan tus costos y responder preguntas más específicas sobre tu factura de la nube.
Si ya eres cliente de DoiT y tienes GKE cost allocation activado, empieza a explorar tus datos en DoiT Cloud Intelligence hoy mismo. Y si aún no eres cliente, pero te interesa conocer más sobre nuestros productos y servicios de consultoría en torno a K8s y más allá, contáctanos.