Découvrez l'allocation des coûts GKE et comment exploiter ses données avec les fonctionnalités d'allocation des coûts de DoiT Cloud Intelligence™ pour obtenir une vue granulaire de vos dépenses GKE.

Obtenir une visibilité suffisante sur ses dépenses Kubernetes est un défi aussi ancien que Kubernetes lui-même.
L'allocation dynamique des ressources et la durée de vie courte des conteneurs compliquent l'attribution des coûts à des applications ou services précis. À cela s'ajoute le partage des ressources entre différents composants.
Malgré tout, disposer d'une bonne visibilité sur les coûts dans Kubernetes est essentiel pour piloter efficacement ses ressources et ses dépenses.
Pour répondre à ces enjeux, Google Cloud a lancé fin 2022 l'allocation des coûts GKE, qui permet aux clients d'obtenir une ventilation détaillée des coûts de leurs clusters.
Dans cet article, nous revenons sur l'allocation des coûts GKE et la façon d'exploiter ses données avec les fonctionnalités d'allocation des coûts de DoiT Cloud Intelligence pour obtenir une vue granulaire de vos dépenses GKE.
Plus précisément, nous verrons comment une entreprise de jeux vidéo fictive pourrait organiser ses coûts GKE jeu par jeu, répartir les coûts partagés entre eux, puis comprendre la ventilation des coûts de chaque jeu par environnement.
Qu'est-ce que l'allocation des coûts GKE
L'allocation des coûts GKE est la méthode recommandée par Google Cloud pour récupérer les informations de facturation d'un cluster. Comparée à son prédécesseur, le comptage de l'utilisation GKE, elle facilite nettement l'attribution des coûts du cluster aux utilisateurs et permet de visualiser les coûts par cluster et par namespace aux côtés des autres coûts des services Google Cloud — ce qui n'était pas possible avec le comptage de l'utilisation. Google Cloud prévoit d'ailleurs de remplacer à terme le GKE Usage Metering par cette fonctionnalité.
Activer l'allocation des coûts GKE est nettement plus simple que le comptage de l'utilisation : il suffit d'une commande gcloud ou de cocher une case dans la Google Cloud Console pour chaque cluster. Une fois activé, un dataset BQ est créé, contenant des métriques sur le CPU, la consommation mémoire et les disques pour les workloads exécutés dans les clusters.
Vous accédez ainsi facilement aux coûts par cluster et par namespace, ainsi qu'aux informations sur les ressources auxquelles des GKE Labels sont associés.
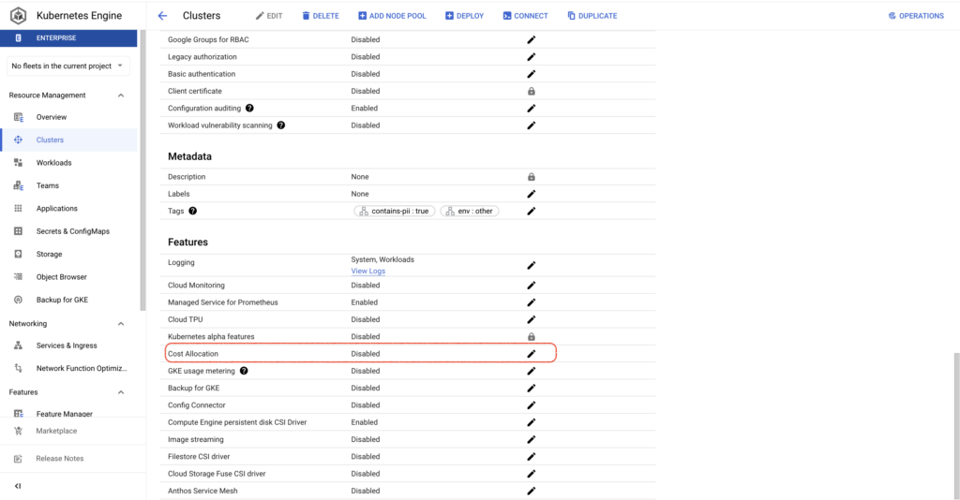
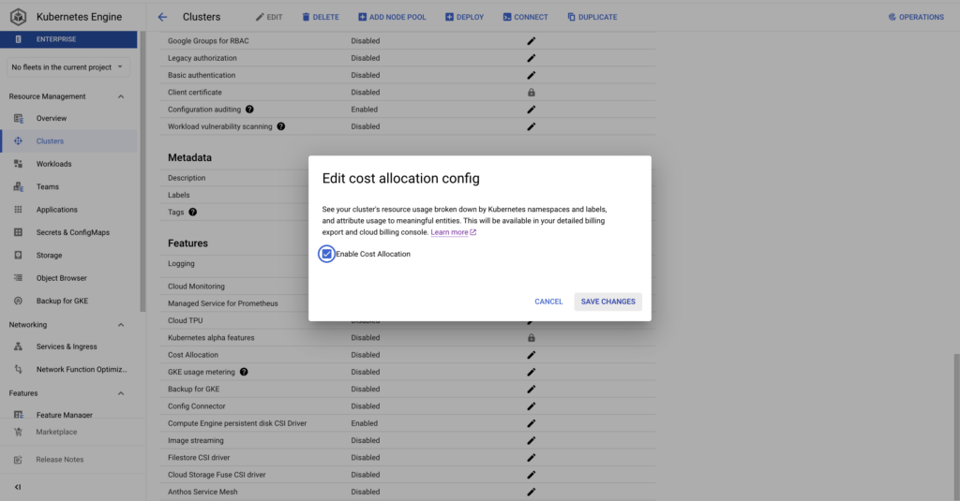
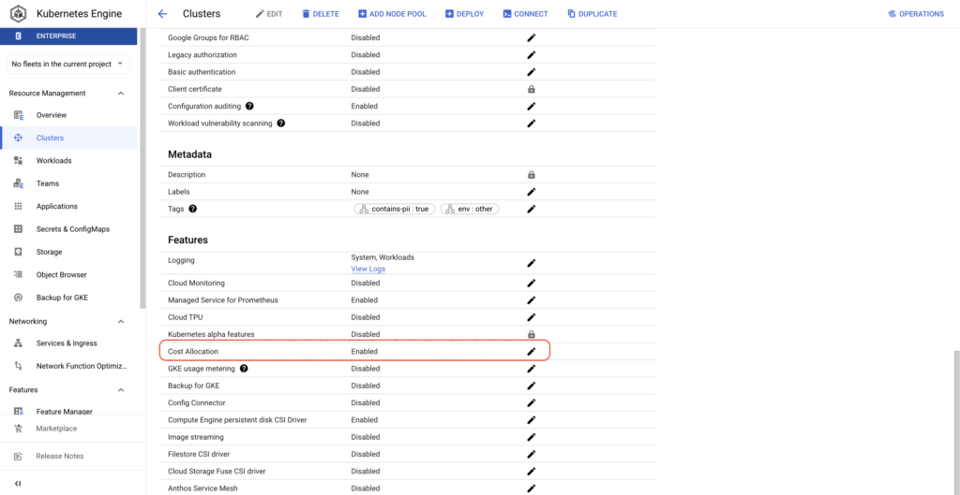
Une fois l'allocation des coûts GKE activée sur vos clusters, vous pourrez répondre à des questions telles que :
- Quelle part des coûts de mon cluster revient à chaque tenant ?
- Comment mes coûts hors cluster (CloudSQL, GCS, etc.) se positionnent-ils par rapport à mes coûts intra-cluster ?
- Combien me coûte mon application backend ?
Enfin, une fois la fonctionnalité activée, les informations de facturation granulaires sur les coûts de votre cluster et de vos namespaces remontent également dans DoiT Cloud Intelligence, ce qui ouvre la voie à des allocations de coûts plus complexes. Voyons un cas concret dans la section suivante.

Associer les coûts GKE à vos regroupements métier
La première étape d'une allocation de coûts consiste à définir les regroupements métier auxquels vous souhaitez rattacher vos coûts. Dans DoiT Cloud Intelligence, cela passe par les Attributions. Les Attributions vous permettent de regrouper les ressources cloud et d'organiser vos coûts selon votre logique d'allocation.
Imaginons que nous soyons une entreprise de jeux vidéo fictive proposant plusieurs jeux à ses utilisateurs.
Nous pourrions vouloir rattacher les ressources aux différents jeux, ainsi qu'aux différents environnements sur lesquels ils tournent.
Ci-dessous, nous avons défini les coûts GKE liés à l'un de nos jeux — un jeu d'action — comme tout namespace contenant le mot action. Le recours à une regex nous permet de capturer les coûts des ressources de tous les nouveaux namespaces liés à ce jeu d'action qui seront créés à l'avenir, sans avoir à mettre l'Attribution à jour manuellement.
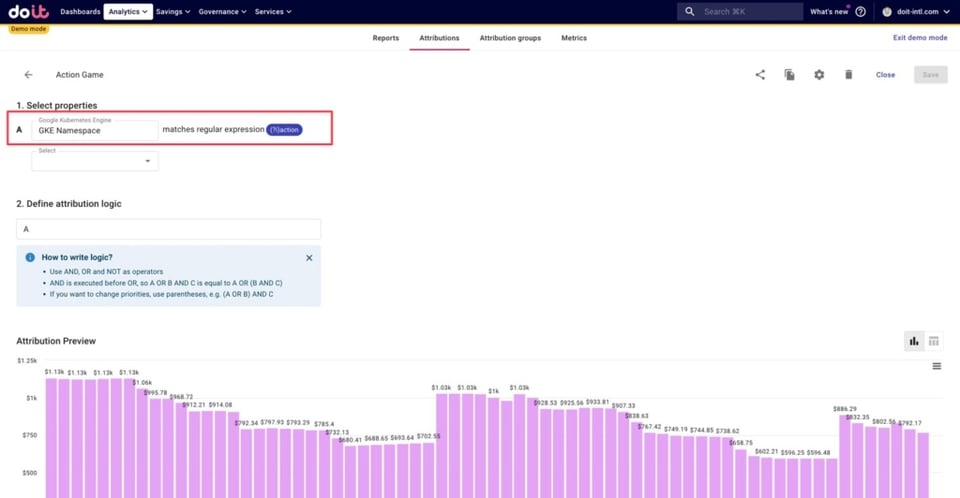
Nous avons également défini des clusters liés aux environnements de production, ainsi qu'aux environnements dev, staging et bêta. Voici un exemple de définition pour les clusters de production, en utilisant une regex pour capturer tous les clusters dont le nom contient le mot prod.
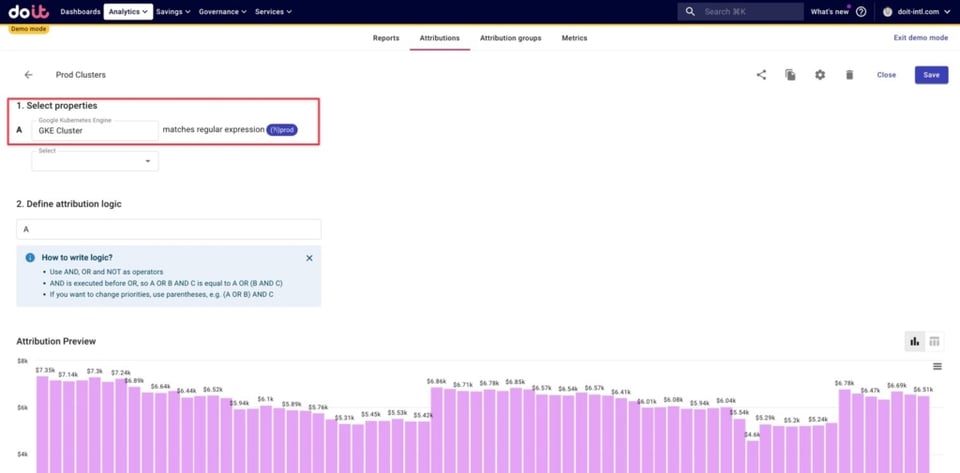
Organiser nos regroupements métier
Nous allons maintenant organiser les Attributions associées en Attribution Groups. Ces groupes permettent de répartir des coûts partagés entre un ensemble d'Attributions, mais aussi de ventiler un ensemble d'Attributions par un autre. Nous ferons les deux dans la section suivante.
Ci-dessous, nous avons créé un Attribution Group Games contenant des Attributions représentant :
- Quatre jeux exploités par notre entreprise fictive
- Les coûts intra-cluster partagés et non attribués, notamment :
- kube:system et kube:system-overhead : composants/namespaces système K8s. (kube-system est le namespace, et Google produit ensuite cette métrique additionnelle pour exprimer l'overhead)
- kube:unallocated : ressources qui ne sont demandées ni par les workloads, ni au titre de l'overhead système.
- goog-k8s-unknown : il s'agit en pratique d'une erreur de l'allocation des coûts, lorsqu'une nouvelle VM Compute démarre ou que le cluster scale up (impossible de traiter le SKU)
- goog-k8s-unsupported-sku — SKU existant mais non pris en charge (par ex. les instances E2)
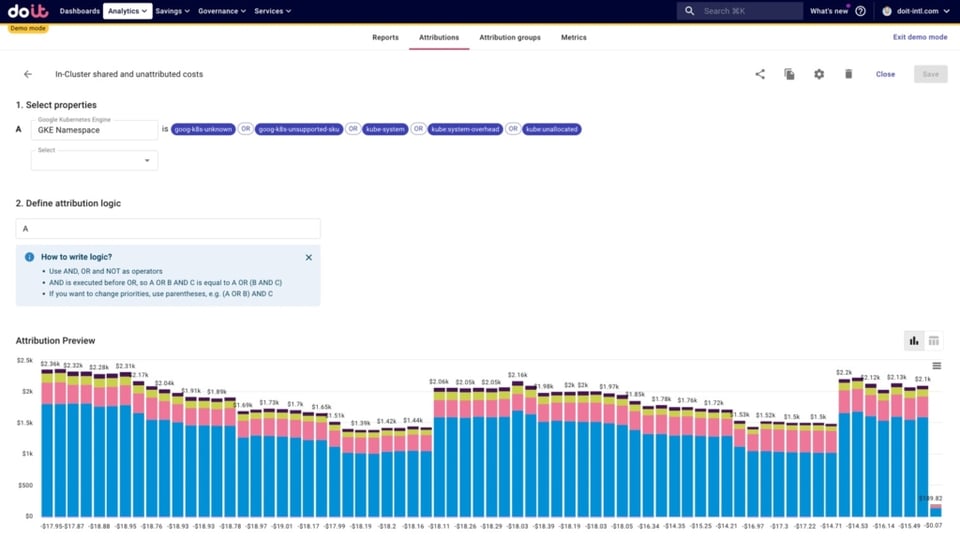
- Les coûts partagés hors cluster : coûts des ressources non Kubernetes, qui s'exécutent dans Google Cloud en dehors de Kubernetes et qui sont utilisées par les applications déployées sur le cluster
- bases de données comme Cloud SQL ou BigQuery
- stockage objet comme Google Cloud Storage
- files de messages comme Pub/Sub, Kafka, etc.
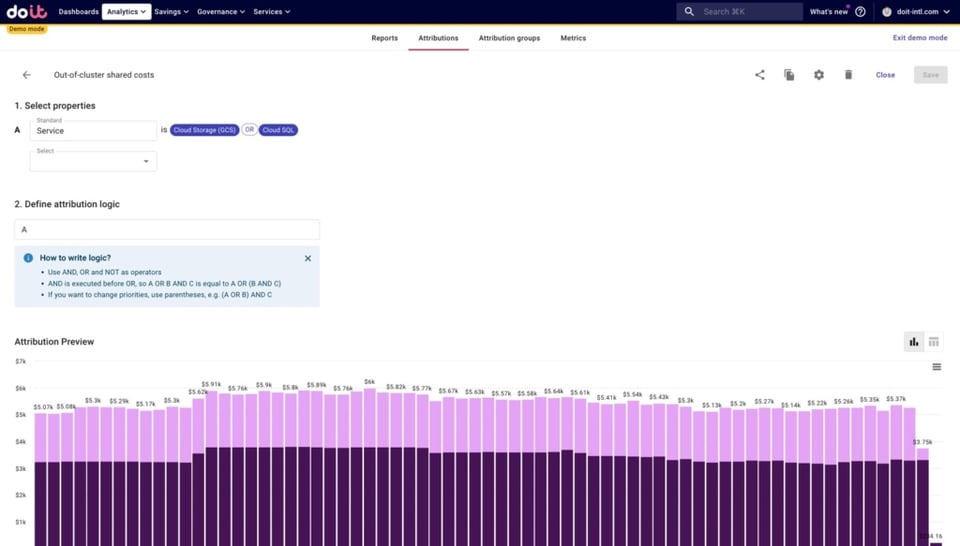
- Tout ce qui n'est pas couvert par les Attributions ci-dessus
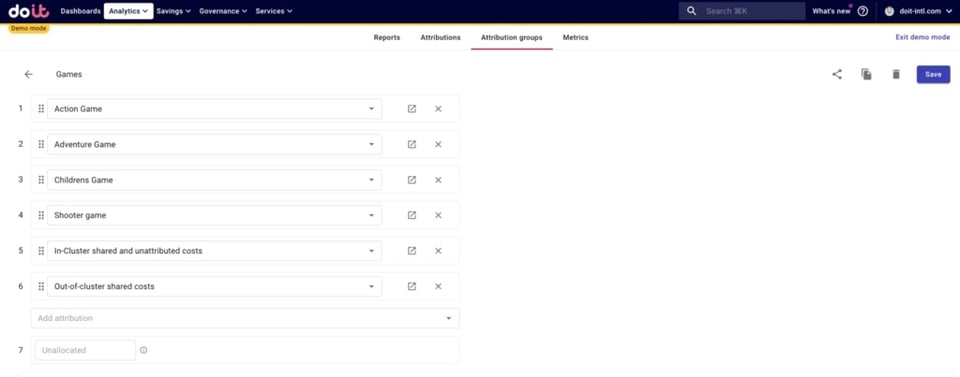
Nous incluons les Attributions non liées aux jeux car ce sont des coûts partagés que nous voudrons répartir entre les jeux dans la section suivante.
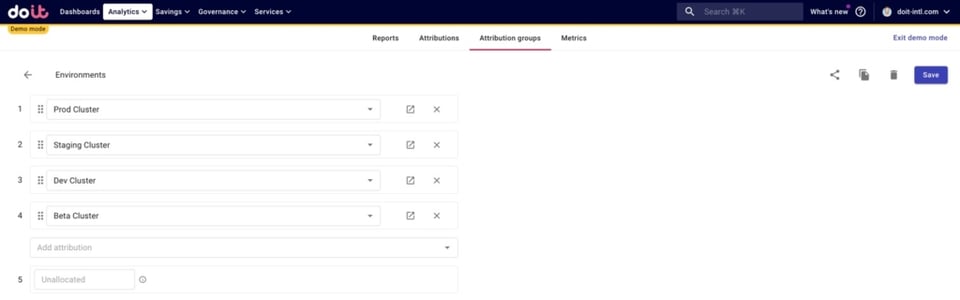
Nous avons également créé un Attribution Group regroupant l'ensemble de nos environnements.
L'objectif : une fois les coûts partagés répartis entre nos jeux, savoir combien nous dépensons par environnement pour chaque jeu.
Répartir les coûts partagés intra-cluster et hors cluster
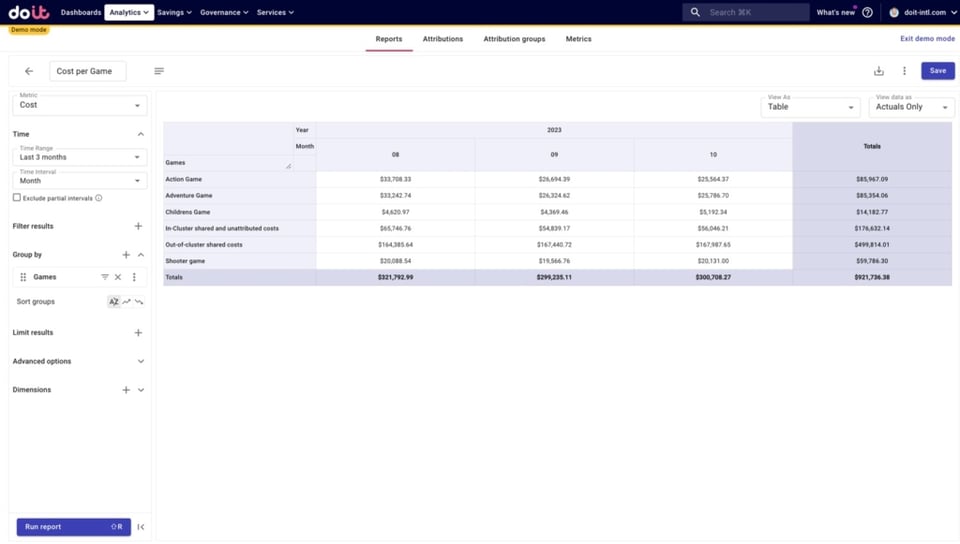
Tout d'abord, nous allons exécuter un rapport pour examiner notre Attribution Group qui contient nos jeux et les coûts partagés.
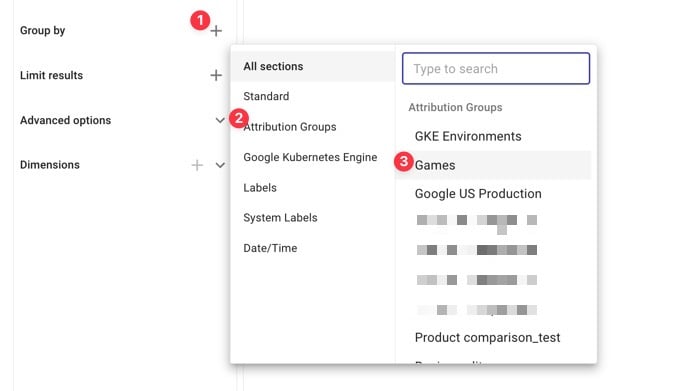
Pour cela, suivons les étapes ci-dessous :
Nous allons ensuite répartir nos deux types de coûts partagés — coûts partagés intra-cluster et non attribués et coûts partagés hors cluster — entre les jeux.
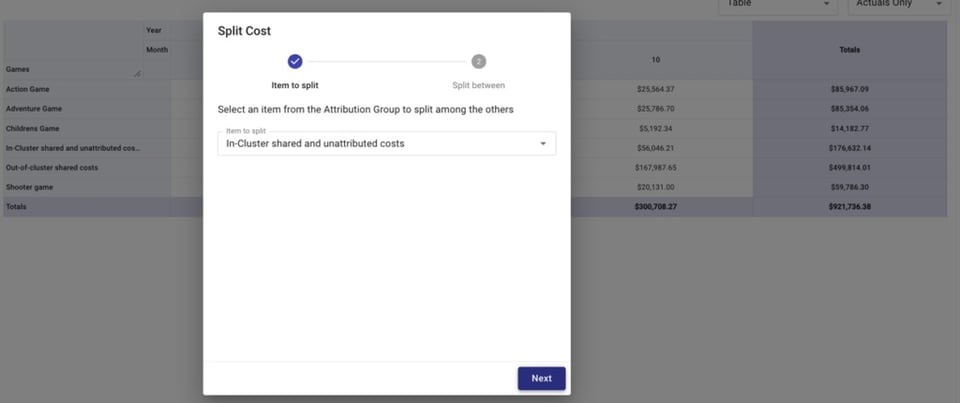
Nous pouvons choisir de répartir ces coûts à parts égales, proportionnellement à la dépense relative de chaque jeu rapportée à la dépense totale, ou selon un montant personnalisé.
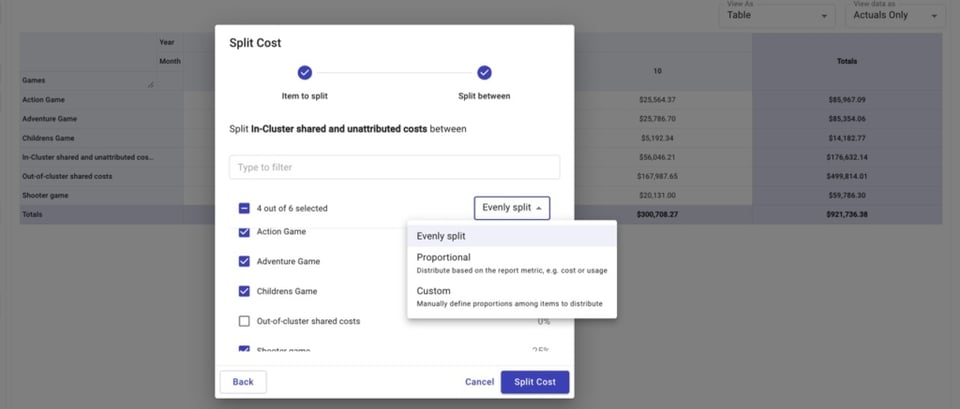
Une fois la répartition effectuée, nous voyons pour chaque jeu :
- Le coût d'exploitation de ce jeu
- Sa part de coûts partagés intra-cluster / non attribués
- Sa part de coûts partagés hors cluster
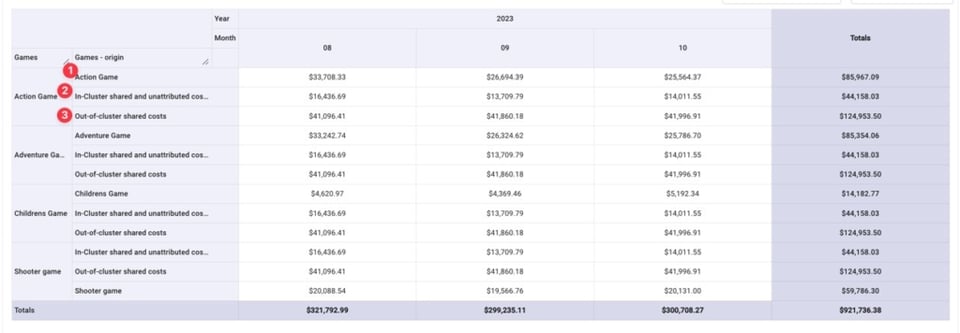
Pour simplifier, nous allons agréger ces trois lignes sous le coût de chaque jeu.
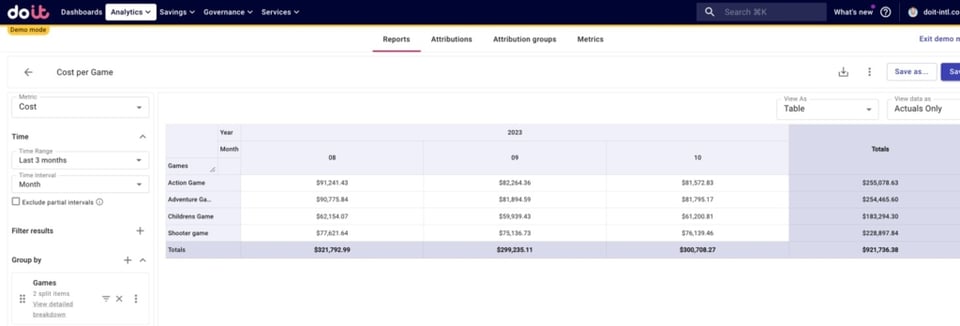
Ventiler les coûts par jeu et par environnement
Nous sommes maintenant prêts à déterminer comment le coût total de chaque jeu se ventile par environnement, en ajoutant notre Attribution Group GKE Environments à notre ventilation.
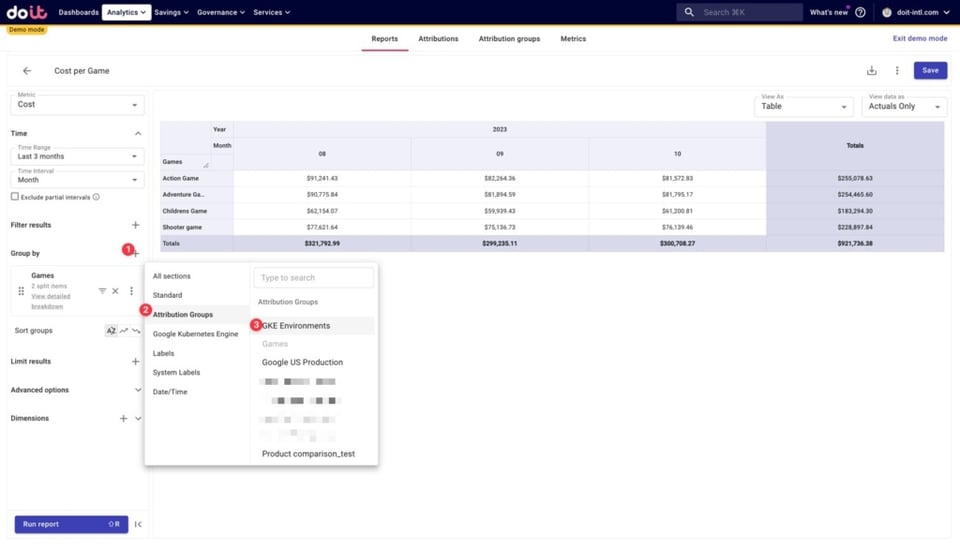
Ci-dessous, nous voyons comment les coûts de chaque jeu se répartissent entre les Attributions d'environnements créées précédemment, ainsi que les coûts non alloués. Ces coûts non alloués correspondent à des ressources qui ne sont capturées par aucune des Attributions des Attribution Groups utilisés ici.
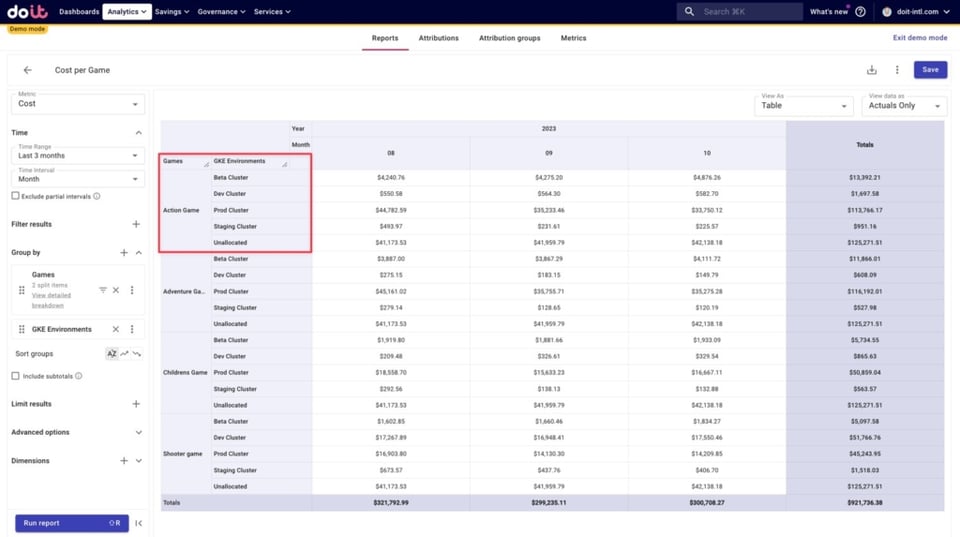
Nous pouvons creuser dans les coûts non alloués pour comprendre ce qui les génère et, à partir de là, modifier éventuellement les Attributions existantes pour y inclure ces ressources.
Filtrons uniquement les coûts non alloués dans l'Attribution Group GKE Environments ci-dessous, puis ajoutons Service à notre ventilation.
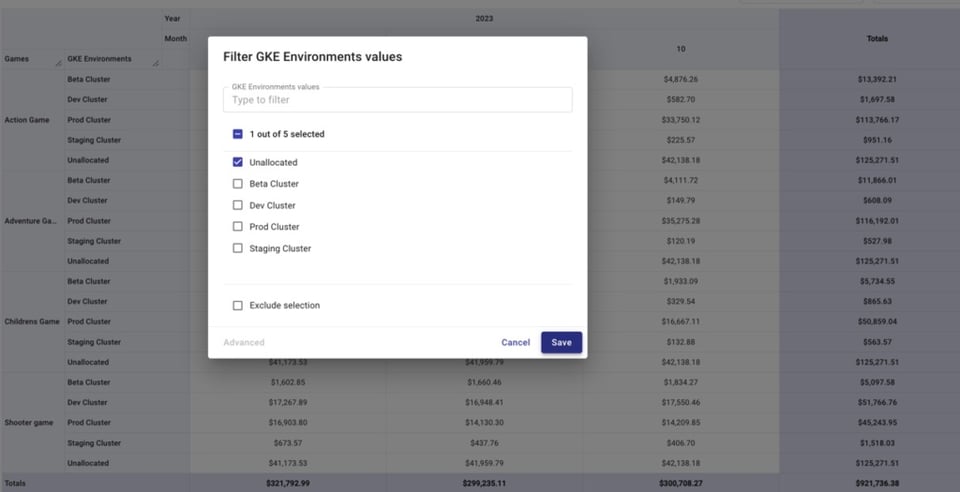
Cela vous aide à repérer les ressources non labellisées lorsqu'elles appartiennent à des services dont les ressources peuvent l'être, ou les projets qui devraient être inclus dans une Attribution mais ne le sont pas.
Ci-dessous, on constate que certains coûts GCE, GCS et Cloud SQL ne sont pas inclus dans nos Attribution Groups.
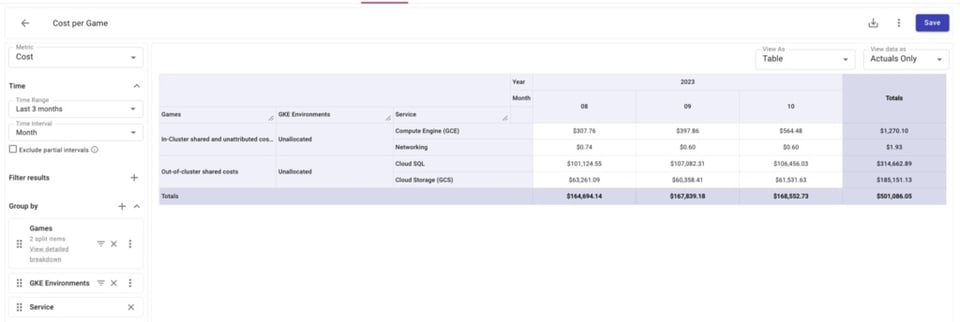
En zoomant sur les ressources non allouées de Compute Engine, nous identifions précisément lesquelles ne sont pas incluses. Forts de ces informations, nous pourrons revoir nos Attributions pour y intégrer ces ressources.
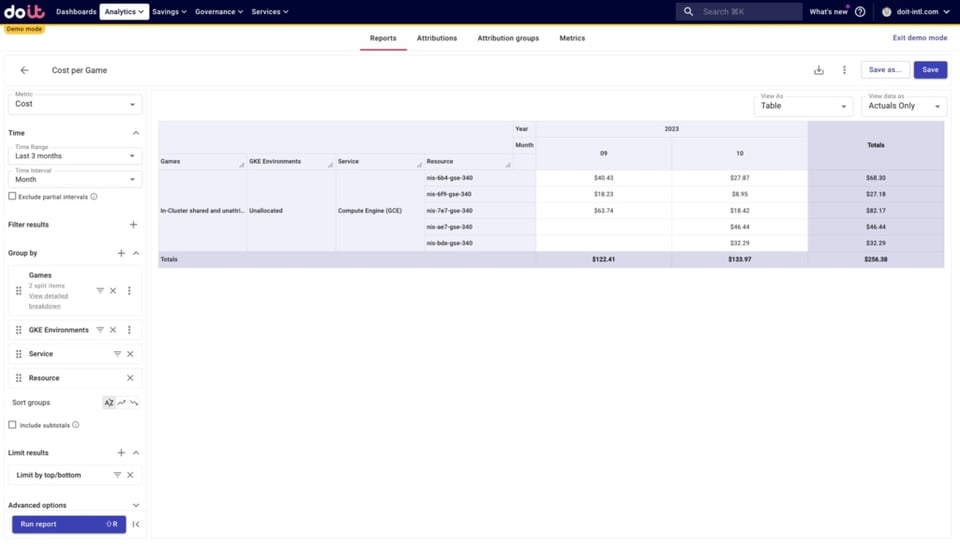
Voilà comment réduire les coûts non alloués et gagner en visibilité sur vos dépenses GKE.
Conclusion
Habituellement, pour mesurer l'impact de vos workloads Kubernetes sur votre facture cloud globale, il fallait se tourner vers des outils tels que Cast AI ou Kubecost.
Ces produits sont plus complets que l'allocation des coûts GKE, mais Google Cloud se distingue parmi les hyperscalers par le fait qu'une bonne partie des fonctionnalités de visibilité sur les coûts est nativement intégrée et facile à activer sur vos clusters.
Vous pouvez ensuite exploiter les données fournies par l'allocation des coûts GKE, comme nous venons de le faire, pour gagner en transparence sur la ventilation de vos coûts et répondre à des questions plus précises sur votre facture cloud.
Si vous êtes client DoiT et que l'allocation des coûts GKE est déjà activée, commencez dès aujourd'hui à explorer vos données dans DoiT Cloud Intelligence. Si vous n'êtes pas encore client mais souhaitez en savoir plus sur nos produits et nos services de conseil autour de K8s et au-delà, contactez-nous.