In diesem Beitrag bauen wir einen Cloud Run-Service mit einem Node.js-Server, der eingehende Datenchunks protokolliert. Dazu kommt ein Node.js-Client, der Datenchunks an den Server schickt.
Wir sehen uns an, wie sich Daten per HTTP/1 mit Chunked Transfer Encoding vom Client zum Server streamen lassen.
Wer es eilig hat: Alle Dateien liegen in meinem Git-Repo.
Warum?
Die erste Frage, die sich aufdrängt, ist: WARUM überhaupt?
In aller Regel ist HTTP/2 hier die bessere Wahl. Es bringt deutliche Performance-Vorteile, geringere Latenzen und eine effizientere Ressourcennutzung. Cloud Run unterstützt zwar End-to-End-HTTP/2 für mehr Performance, doch Ihre Anwendung muss HTTP/2-Aufrufe ebenfalls verarbeiten können. Genau das ist nicht überall gegeben und kann bei manchen Deployments zur Hürde werden:
- Ältere Clients müssen unterstützt werden, die HTTP/2 nicht beherrschen oder bekannte Probleme damit haben.
- Setzt Ihre Anwendung auf Bibliotheken oder Frameworks, die zwingend Chunked Encoding verlangen und nicht vollständig HTTP/2-kompatibel sind, bleibt unter Umständen nur HTTP/1.
Wir nutzen den Header Transfer-Encoding: chunked – ein Feature von HTTP/1.1, mit dem der Client Daten in Chunks an den Server senden kann, ohne die Gesamtgröße vorab zu kennen. Die Daten werden in Stücke zerlegt und einzeln übertragen; der Server setzt sie anschließend wieder zusammen.
Das ist besonders praktisch, wenn die Länge der Inhalte zu Beginn der Übertragung noch nicht feststeht – typisch für dynamische oder gestreamte Inhalte.
Wichtig zu wissen: HTTP/2 und HTTP/3 übertragen Daten anders – mit Binary Framing und Multiplexing können mehrere Requests und Responses parallel laufen, was zu Performance-Verbesserungen führen kann. Allerdings lässt sich Ihre Anwendung möglicherweise nicht ohne Weiteres auf HTTP/2 umstellen.
Beachten Sie: Das Konzept des Chunked Transfer Encoding lässt sich in HTTP/2 und HTTP/3 nicht eins zu eins übertragen wie in HTTP/1.1.
Streaming-Richtungen
Streaming vom Server zum Client und Streaming vom Client zum Server sind zwei unterschiedliche Konzepte – jedes mit eigenen Anwendungsfällen und Techniken.
1. Server zu Client (Server-Sent Events): Kommt typischerweise zum Einsatz, wenn der Server neue Informationen an den Client pushen muss.
Beispiel: In einer Echtzeitanwendung wie einem Chat oder einem Live-Sport-Ticker muss der Server neue Nachrichten oder Updates sofort an den Client weitergeben, sobald sie verfügbar sind.
Umgesetzt wird das mit Server-Sent Events (SSE): Der Client öffnet eine Verbindung zum Server, dieser hält sie offen und schickt Updates über diese Verbindung, sobald welche vorliegen.
2. Client zu Server (HTTP-Streaming bzw. Chunked Transfer Encoding): Kommt typischerweise zum Einsatz, wenn der Client große Datenmengen an den Server senden möchte und mit der Übertragung beginnen will, bevor alle Daten bereitstehen.
Beispiel: Bei einem File-Upload möchte der Client den Upload einer großen Datei starten, bevor sie vollständig in den Speicher geladen wurde.
Umgesetzt wird das über das HTTP-Feature Chunked Transfer Encoding: Der Client sendet die Daten in Chunks und der Server verarbeitet jeden Chunk, sobald er eintrifft.
In beiden Fällen ist das Ziel, Daten Stück für Stück zu senden und zu verarbeiten, statt alles bereits zu Beginn der Anfrage bereitzuhalten. Das verbessert die Performance und senkt den Speicherverbrauch – gerade bei großen Datenmengen.
Welche Richtung die richtige ist, hängt von den konkreten Anforderungen Ihrer Anwendung ab. In diesem Beitrag konzentrieren wir uns ausschließlich auf Client-zu-Server-Streaming. Wer sich für Server-zu-Client-Streaming mit gRPC interessiert, wird in diesem Beitrag im Google Blog fündig.
Server-Setup
Zuerst der Server. Wir setzen auf Express, ein verbreitetes Node.js-Framework. Unser Server lauscht auf POST-Requests am Endpoint /upload und protokolliert alle eingehenden Datenchunks.
Legen Sie die Datei package.json an:
{
"name": "stream-test",
"version": "1.0.0",
"description": "",
"main": "client.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "node server.js"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"express": "^4.18.2"
}
}
Und so sieht die server.js aus:
// server.js
const express = require('express');
const app = express();
app.use(express.raw({ type: '*/*', limit: '5mb' }));
app.post('/upload', (req, res) => {
req.on('data', chunk => {
console.log(`Received chunk: ${chunk}`);
});
req.on('end', () => {
res.send('Upload complete');
});
});
app.listen(3000, () => console.log('Server listening on port 3000'));
Den Server packen wir mit Docker in einen Container. Hier ein einfaches Dockerfile:
# Dockerfile.server
FROM node:14
WORKDIR /usr/src/app
COPY package*.json ./
RUN npm install
COPY . .
CMD [ "node", "server.js" ]
Cloud Run Server
Jetzt bauen wir die Container-Images, pushen sie in unsere Artifact Registry in GCP und deployen sie in unseren Cloud Run-Service. Das AR-Repository müssen Sie eventuell vorher anlegen:
REPOSITORY=us-central1-docker.pkg.dev/<GCP_PROJECT>/<REPO>
docker build -t $REPOSITORY/stream-server:1.0 -f Dockerfile.server .
Server deployen:
gcloud run deploy stream-server --image $REPOSITORY/stream-server:1.0
Nach dem Deployment sollten Sie ähnliche Logs sehen:

Der Server läuft jetzt auf Cloud Run – als Nächstes brauchen wir die Cloud Run-URL:
export SERVER_URL=$(gcloud run services describe stream-server --region us-central1 --format 'value(status.url)')
Client-Setup
Nun zum Client. Beim Start sendet er Datenchunks an den Server. Denken Sie daran, <SERVER_URL> im Feld hostname durch die tatsächliche Server-URL zu ersetzen.
Hier die client.js:
// client.js
const https = require('https');
const options = {
hostname: '<SERVER_URL>',
port: 443,
path: '/upload',
method: 'POST',
headers: {
'Transfer-Encoding': 'chunked'
}
};
const req = https.request(options, (res) => {
res.on('data', (chunk) => {
console.log(`Response: ${chunk}`);
});
});
// write chunks of data to the request
req.write('chunk1');
req.write('chunk2');
req.write('chunk3');
req.end();
Auch den Client packen wir mit Docker in einen Container. Hier das passende Dockerfile:
# Dockerfile.client
FROM node:14
WORKDIR /usr/src/app
COPY package*.json ./
RUN npm install
COPY . .
CMD [ "node", "client.js" ]
Jetzt bauen wir das Client-Image und führen den Code aus:
docker build -t stream-client:1.0 -f Dockerfile.client .
docker run --rm stream-client:1.0
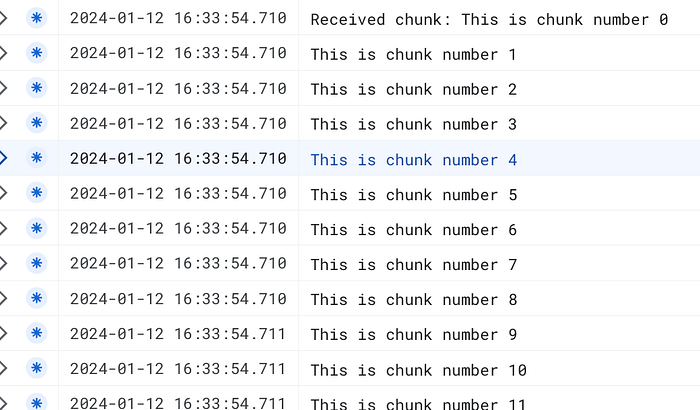
Prüfen wir, ob alles läuft – ein Blick in die Cloud Run-Logs auf der Serverseite:

Moment mal – die Chunks landen offenbar nicht getrennt im Log. Der Grund: Das HTTP-Protokoll garantiert nicht, dass jeder Aufruf von req.write() auf der Serverseite ein separates "data"-Event auslöst.
Die gesendeten Chunks sind klein und folgen schnell aufeinander, sodass der Server sie höchstwahrscheinlich in einem einzigen "data"-Event empfängt.
Um zu bestätigen, dass das Streaming tatsächlich funktioniert, können Sie eine größere Datenmenge senden, die nicht in ein einziges TCP-Paket passt. Damit erzwingen Sie eine Aufteilung in mehrere Chunks und entsprechend mehrere "data"-Events auf der Serverseite.
Wir passen die client.js an: Eine "for"-Schleife schreibt die Daten, anschließend bauen wir den Container neu und testen erneut.
// client.js
const https = require('https');
const options = {
hostname: 'stream-server-kdfodunfwq-uc.a.run.app',
port: 443,
path: '/upload',
method: 'POST',
headers: {
'Transfer-Encoding': 'chunked'
}
};
const req = https.request(options, (res) => {
res.on('data', (chunk) => {
console.log(`Response: ${chunk}`);
});
});
// write a large amount of data to the request
for (let i = 0; i < 1e6; i++) {
req.write(`This is chunk number ${i}\n`);
}
req.end();
docker build -t stream-client:2.0 -f Dockerfile.client .
docker run --rm stream-client:2.0
Sieht gut aus – jetzt funktioniert es!
In diesem Beitrag haben wir gesehen, wie sich Daten zwischen zwei Cloud Run-Instanzen mit Node.js streamen lassen. Mit diesem Setup schicken wir Daten in Chunks vom Client an den Server, der jeden eingehenden Chunk protokolliert.
Denken Sie daran: Das HTTP-Protokoll garantiert nicht, dass jeder Aufruf von req.write() auf der Serverseite ein separates "data"-Event auslöst. Die zunächst gesendeten Chunks waren recht klein und folgten schnell aufeinander, sodass sie der Server in einem einzigen "data"-Event empfangen hat.
Bestätigen konnten wir das Streaming, indem wir eine größere Datenmenge gesendet haben, die nicht in ein einziges TCP-Paket passt. Dadurch wurden die Daten zwangsläufig in mehrere Chunks aufgeteilt, was wiederum mehrere "data"-Events auf der Serverseite ausgelöst hat.
Noch einmal: HTTP/2 ist generell vorzuziehen. Setzen Sie es ein, wann immer es möglich ist.
Ich hoffe, dieser Beitrag war hilfreich! Bei Fragen hinterlassen Sie gerne einen Kommentar.