In questo articolo creeremo un servizio Cloud Run basato su un server Node.js che registra i chunk di dati in arrivo. Realizzeremo inoltre un client Node.js che invia chunk di dati al server.
Vedremo come effettuare lo streaming di dati da client a server tramite HTTP/1 con il chunked transfer encoding.
Se non vedete l'ora di provare, trovate tutti i file nel mio repository git qui.
Perché?
La prima cosa che probabilmente vi state chiedendo è il PERCHÉ.
In genere HTTP/2 è l'opzione preferibile in questo contesto. Offre vantaggi significativi in termini di prestazioni, riduzione della latenza e migliore utilizzo delle risorse. Tuttavia, sebbene Cloud Run supporti HTTP/2 end-to-end per migliorare le prestazioni, anche la vostra applicazione deve essere in grado di ricevere chiamate HTTP/2. Purtroppo questa funzionalità non è disponibile ovunque e può rappresentare un ostacolo per alcuni deployment:
- Si ha la necessità di supportare client più datati che non gestiscono HTTP/2 o presentano problemi noti con esso
- Se la vostra applicazione si appoggia a librerie o framework che richiedono espressamente il chunked encoding e non sono pienamente compatibili con HTTP/2, HTTP/1 potrebbe essere l'unica strada percorribile.
Useremo l'header Transfer-Encoding: chunked, una funzionalità di HTTP/1.1 che consente al client di inviare dati al server in chunk senza conoscere in anticipo la dimensione totale dei dati. I dati vengono suddivisi in chunk e inviati separatamente, e il server li ricostruisce a partire da questi chunk.
Questo approccio è particolarmente utile quando, all'inizio della trasmissione, il mittente non conosce la lunghezza del contenuto, come spesso accade per contenuti dinamici o in streaming.
Vale la pena ricordare che HTTP/2 e HTTP/3 gestiscono la trasmissione dei dati in modo diverso, sfruttando il binary framing e il multiplexing per consentire a più richieste e risposte di essere in transito contemporaneamente; ciò può portare a migliori prestazioni, ma potreste non avere la possibilità di modificare la vostra applicazione per accettare HTTP/2.
Tenete presente che il concetto di chunked transfer encoding non si applica direttamente in HTTP/2 e HTTP/3 come avviene in HTTP/1.1.
Direzioni dello streaming dei dati
Lo streaming di dati dal server al client e dal client al server sono due concetti distinti, ciascuno con i propri casi d'uso e le proprie tecniche.
1. Server-to-Client (Server-Sent Events): viene tipicamente utilizzato quando il server ha nuove informazioni da inviare al client.
Ad esempio, in un'applicazione real-time come una chat o un'app di aggiornamenti sportivi in diretta, il server potrebbe dover inviare nuovi messaggi o aggiornamenti al client non appena disponibili.
Per farlo si ricorre a una tecnica chiamata Server-Sent Events (SSE): il client apre una connessione verso il server e il server la mantiene aperta, inviando aggiornamenti lungo la connessione ogni volta che sono disponibili.
2. Client-to-Server (HTTP Streaming o Chunked Transfer Encoding): viene tipicamente utilizzato quando il client deve inviare al server una grande quantità di dati e vuole iniziare la trasmissione prima che tutti i dati siano pronti.
Ad esempio, nel caso del caricamento di un file, il client potrebbe voler iniziare l'upload di un file di grandi dimensioni prima che l'intero file sia stato letto in memoria.
Tutto ciò avviene tramite una funzionalità del protocollo HTTP chiamata chunked transfer encoding: il client invia i dati in chunk e il server elabora ogni chunk man mano che arriva.
In entrambi i casi, l'obiettivo è permettere l'invio e l'elaborazione dei dati in modo incrementale, senza dover attendere che tutti i dati siano pronti all'inizio della richiesta. Ne possono derivare prestazioni migliori e un minore consumo di memoria, soprattutto quando si gestiscono grandi volumi di dati.
Ricordate che la scelta tra streaming server-to-client e client-to-server dipende dai requisiti specifici della vostra applicazione. In questo articolo ci concentreremo esclusivamente sullo streaming Client-to-Server. Se invece volete approfondire lo stream server-to-client con gRPC, potete consultare questo articolo del Google Blog.
Configurazione del server
Per prima cosa, creiamo il server. Useremo Express, un noto framework Node.js. Il nostro server resterà in ascolto delle richieste POST sull'endpoint /upload e registrerà i chunk di dati in arrivo.
Create il file package.json
{
"name": "stream-test",
"version": "1.0.0",
"description": "",
"main": "client.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "node server.js"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"express": "^4.18.2"
}
}
Ed ecco il server.js del nostro server:
// server.js
const express = require('express');
const app = express();
app.use(express.raw({ type: '*/*', limit: '5mb' }));
app.post('/upload', (req, res) => {
req.on('data', chunk => {
console.log(`Received chunk: ${chunk}`);
});
req.on('end', () => {
res.send('Upload complete');
});
});
app.listen(3000, () => console.log('Server listening on port 3000'));
Possiamo containerizzare il server con Docker. Ecco un semplice Dockerfile:
# Dockerfile.server
FROM node:14
WORKDIR /usr/src/app
COPY package*.json ./
RUN npm install
COPY . .
CMD [ "node", "server.js" ]
Server Cloud Run
Bene, ora creiamo le immagini dei container, le pubblichiamo nel nostro Artifact Registry su GCP e le distribuiamo al nostro servizio Cloud Run. Potrebbe essere necessario creare prima il repository AR:
REPOSITORY=us-central1-docker.pkg.dev/<GCP_PROJECT>/<REPO>
docker build -t $REPOSITORY/stream-server:1.0 -f Dockerfile.server .
Eseguite il deploy del server
gcloud run deploy stream-server --image $REPOSITORY/stream-server:1.0
Una volta distribuito il servizio, dovreste vedere log simili a questi

Ora che il server è in esecuzione su Cloud Run, dobbiamo recuperare l'URL di Cloud Run:
export SERVER_URL=$(gcloud run services describe stream-server --region us-central1 --format 'value(status.url)')
Configurazione del client
Creiamo ora il client. All'avvio invierà chunk di dati al server. Ricordatevi di sostituire <SERVER_URL> nel campo hostname con l'URL effettivo del server.
Ecco il client.js:
// client.js
const https = require('https');
const options = {
hostname: '<SERVER_URL>',
port: 443,
path: '/upload',
method: 'POST',
headers: {
'Transfer-Encoding': 'chunked'
}
};
const req = https.request(options, (res) => {
res.on('data', (chunk) => {
console.log(`Response: ${chunk}`);
});
});
// write chunks of data to the request
req.write('chunk1');
req.write('chunk2');
req.write('chunk3');
req.end();
Anche il client può essere containerizzato con Docker. Ecco un semplice Dockerfile:
# Dockerfile.client
FROM node:14
WORKDIR /usr/src/app
COPY package*.json ./
RUN npm install
COPY . .
CMD [ "node", "client.js" ]
Ora costruiamo l'immagine del client ed eseguiamo il codice
docker build -t stream-client:1.0 -f Dockerfile.client .
docker run --rm stream-client:1.0
Verifichiamo che tutto funzioni controllando ora i log di Cloud Run lato server:

Un attimo: sembra che i chunk non vengano registrati separatamente. Il problema è che il protocollo HTTP non garantisce che ogni chiamata a req.write() generi un evento 'data' distinto sul server.
I chunk inviati sono piccoli e si susseguono molto rapidamente, quindi è probabile che il server li riceva all'interno di un unico evento 'data'.
Per verificare che lo streaming funzioni davvero, potete inviare una quantità di dati maggiore, tale da non poter essere contenuta in un singolo pacchetto TCP. In questo modo i dati saranno per forza suddivisi in più chunk, generando di conseguenza più eventi 'data' sul server.
Sistemiamo il file client.js aggiungendo un "ciclo for" per scrivere i dati, ricostruiamo il container e proviamo di nuovo.
// client.js
const https = require('https');
const options = {
hostname: 'stream-server-kdfodunfwq-uc.a.run.app',
port: 443,
path: '/upload',
method: 'POST',
headers: {
'Transfer-Encoding': 'chunked'
}
};
const req = https.request(options, (res) => {
res.on('data', (chunk) => {
console.log(`Response: ${chunk}`);
});
});
// write a large amount of data to the request
for (let i = 0; i < 1e6; i++) {
req.write(`This is chunk number ${i}\n`);
}
req.end();
docker build -t stream-client:2.0 -f Dockerfile.client .
docker run --rm stream-client:2.0
Ora sembra funzionare, ottimo!
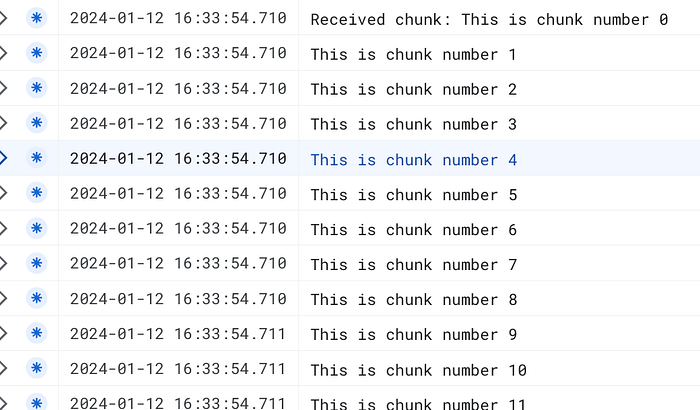
In questo articolo abbiamo visto come effettuare lo streaming di dati tra due istanze Cloud Run con Node.js. Questa configurazione ci permette di inviare dati in chunk dal client al server, con il server che registra ogni chunk man mano che arriva.
Tenete presente che il protocollo HTTP non garantisce che ogni chiamata a req.write() generi un evento 'data' separato sul server. I chunk inviati inizialmente erano piuttosto piccoli e si susseguivano molto rapidamente, perciò venivano ricevuti dal server in un unico evento 'data'.
Abbiamo potuto confermare il corretto funzionamento dello streaming inviando una quantità di dati maggiore, tale da non poter essere contenuta in un singolo pacchetto TCP. Questo ha forzato la suddivisione dei dati in più chunk, generando di conseguenza più eventi 'data' sul server.
Ribadiamolo: HTTP/2 resta in genere la soluzione preferibile. Quando potete, usatelo.
Spero che questo articolo vi sia stato utile. Per qualsiasi domanda, non esitate a lasciare un commento qui sotto.