Dans cet article, nous allons créer un service Cloud Run à l'aide d'un serveur Node.js qui journalise les fragments de données entrants. Nous créerons également un client Node.js qui envoie des fragments de données au serveur.
Nous verrons comment streamer des données du client vers le serveur en HTTP/1 grâce au chunked transfer encoding.
Si vous êtes pressé, vous pouvez consulter mon dépôt git contenant tous les fichiers ici.
Pourquoi ?
La première question qui vient à l'esprit est sans doute : POURQUOI ?
En général, HTTP/2 reste l'option à privilégier. Il offre des gains de performance significatifs, une latence réduite et une meilleure utilisation des ressources. Mais si Cloud Run propose le HTTP/2 de bout en bout pour de meilleures performances, encore faut-il que votre application soit capable de recevoir des appels HTTP/2. Or, cette capacité n'est pas universellement disponible, ce qui peut représenter un obstacle pour certains déploiements :
- Vous devez prendre en charge des clients plus anciens qui ne supportent pas HTTP/2 ou présentent des problèmes connus avec ce protocole
- Si votre application repose sur des bibliothèques ou frameworks qui exigent spécifiquement le chunked encoding et ne sont pas pleinement compatibles avec HTTP/2, HTTP/1 peut être la seule option viable.
Nous allons utiliser l'en-tête Transfer-Encoding: chunked, une fonctionnalité de HTTP/1.1 qui permet au client d'envoyer des données par fragments au serveur sans connaître la taille totale à l'avance. Les données sont découpées en fragments envoyés séparément, puis le serveur les reconstitue à partir de ces fragments.
C'est particulièrement utile lorsque l'expéditeur ignore la longueur du contenu au moment d'amorcer la transmission, ce qui est souvent le cas pour du contenu dynamique ou en streaming.
À noter que HTTP/2 et HTTP/3 gèrent la transmission différemment, en s'appuyant sur un framing binaire et le multiplexage pour permettre à plusieurs requêtes et réponses de circuler simultanément, ce qui peut se traduire par des gains de performance. Toutefois, il n'est pas toujours possible de modifier votre application pour qu'elle accepte HTTP/2.
Gardez à l'esprit que le concept de chunked transfer encoding ne s'applique pas directement en HTTP/2 et HTTP/3 comme c'est le cas en HTTP/1.1.
Sens du streaming de données
Streamer des données du serveur vers le client et du client vers le serveur sont deux concepts distincts, chacun avec ses propres cas d'usage et techniques.
1. Du serveur vers le client (Server-Sent Events) : on l'utilise généralement lorsque le serveur dispose de nouvelles informations à pousser vers le client.
Par exemple, dans une application en temps réel comme un chat ou un service de mises à jour sportives en direct, le serveur peut avoir besoin d'envoyer de nouveaux messages ou de nouvelles mises à jour au client dès qu'ils sont disponibles.
Cela passe par une technique appelée Server-Sent Events (SSE) : le client ouvre une connexion vers le serveur, qui maintient cette connexion ouverte et y pousse les mises à jour au fil de l'eau.
2. Du client vers le serveur (HTTP Streaming ou Chunked Transfer Encoding) : on l'utilise généralement lorsque le client a une grande quantité de données à envoyer au serveur et souhaite démarrer la transmission avant que toutes les données ne soient prêtes.
Par exemple, dans un scénario de téléversement de fichier, le client peut vouloir commencer à envoyer un fichier volumineux avant qu'il ne soit entièrement chargé en mémoire.
Cela s'appuie sur une fonctionnalité du protocole HTTP appelée chunked transfer encoding : le client envoie les données par fragments et le serveur traite chaque fragment au fur et à mesure de sa réception.
Dans les deux cas, l'objectif est de permettre l'envoi et le traitement progressif des données, plutôt que d'exiger que toutes les données soient prêtes au début de la requête. Cela peut se traduire par de meilleures performances et une consommation mémoire plus faible, en particulier face à de grandes quantités de données.
Le choix entre streaming serveur-vers-client et client-vers-serveur dépend des besoins propres à votre application. Dans cet article, nous nous concentrons uniquement sur le streaming client vers serveur. Pour explorer le streaming serveur vers client avec gRPC, consultez cet article du blog Google.
Configuration du serveur
Commençons par créer le serveur. Nous utiliserons Express, un framework Node.js populaire. Notre serveur écoutera les requêtes POST sur l'endpoint /upload et journalisera tous les fragments de données entrants.
Créez le fichier package.json :
{
"name": "stream-test",
"version": "1.0.0",
"description": "",
"main": "client.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "node server.js"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"express": "^4.18.2"
}
}
Et voici le server.js de notre serveur :
// server.js
const express = require('express');
const app = express();
app.use(express.raw({ type: '*/*', limit: '5mb' }));
app.post('/upload', (req, res) => {
req.on('data', chunk => {
console.log(`Received chunk: ${chunk}`);
});
req.on('end', () => {
res.send('Upload complete');
});
});
app.listen(3000, () => console.log('Server listening on port 3000'));
Nous pouvons conteneuriser ce serveur avec Docker. Voici un Dockerfile simple :
# Dockerfile.server
FROM node:14
WORKDIR /usr/src/app
COPY package*.json ./
RUN npm install
COPY . .
CMD [ "node", "server.js" ]
Serveur Cloud Run
Créons maintenant les images de conteneurs, poussons-les vers notre Artifact Registry sur GCP et déployons-les sur notre service Cloud Run. Vous devrez peut-être créer votre dépôt AR au préalable :
REPOSITORY=us-central1-docker.pkg.dev/<GCP_PROJECT>/<REPO>
docker build -t $REPOSITORY/stream-server:1.0 -f Dockerfile.server .
Déployez votre serveur :
gcloud run deploy stream-server --image $REPOSITORY/stream-server:1.0
Vous devriez voir des logs similaires une fois le service déployé :

Maintenant que notre serveur tourne sur Cloud Run, récupérons l'URL Cloud Run :
export SERVER_URL=$(gcloud run services describe stream-server --region us-central1 --format 'value(status.url)')
Configuration du client
Créons maintenant le client. Notre client enverra des fragments de données au serveur dès son démarrage. Pensez à remplacer <SERVER_URL> dans le champ hostname par l'URL réelle du serveur.
Voici le client.js de notre client :
// client.js
const https = require('https');
const options = {
hostname: '<SERVER_URL>',
port: 443,
path: '/upload',
method: 'POST',
headers: {
'Transfer-Encoding': 'chunked'
}
};
const req = https.request(options, (res) => {
res.on('data', (chunk) => {
console.log(`Response: ${chunk}`);
});
});
// write chunks of data to the request
req.write('chunk1');
req.write('chunk2');
req.write('chunk3');
req.end();
Nous pouvons également conteneuriser ce client avec Docker. Voici un Dockerfile simple :
# Dockerfile.client
FROM node:14
WORKDIR /usr/src/app
COPY package*.json ./
RUN npm install
COPY . .
CMD [ "node", "client.js" ]
Construisons maintenant l'image du client et exécutons le code :
docker build -t stream-client:1.0 -f Dockerfile.client .
docker run --rm stream-client:1.0
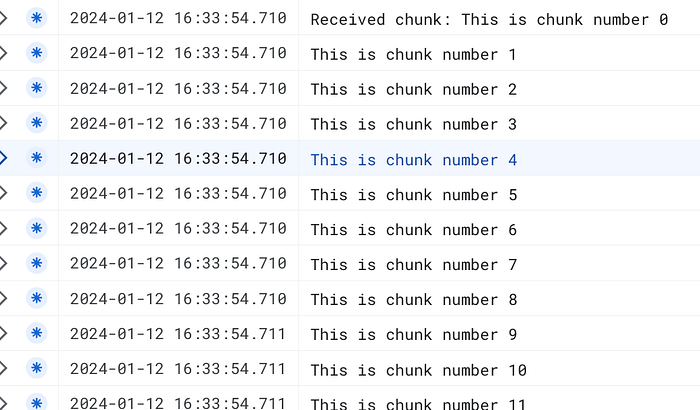
Vérifions que tout fonctionne en consultant les logs Cloud Run côté serveur :

Un instant : les fragments ne semblent pas être journalisés séparément. Le problème, c'est que le protocole HTTP ne garantit pas que chaque appel à req.write() donne lieu à un événement data distinct côté serveur.
Les fragments envoyés sont petits et expédiés en succession rapide ; ils sont donc probablement reçus par le serveur dans un seul événement data.
Pour confirmer que le streaming fonctionne, vous pouvez envoyer une quantité de données plus importante qui ne tiendra pas dans un seul paquet TCP. Cela forcera le découpage en plusieurs fragments, ce qui devrait alors déclencher plusieurs événements data côté serveur.
Corrigeons notre fichier client.js en y ajoutant une boucle for pour écrire les données, reconstruisons le conteneur et testons à nouveau.
// client.js
const https = require('https');
const options = {
hostname: 'stream-server-kdfodunfwq-uc.a.run.app',
port: 443,
path: '/upload',
method: 'POST',
headers: {
'Transfer-Encoding': 'chunked'
}
};
const req = https.request(options, (res) => {
res.on('data', (chunk) => {
console.log(`Response: ${chunk}`);
});
});
// write a large amount of data to the request
for (let i = 0; i < 1e6; i++) {
req.write(`This is chunk number ${i}\n`);
}
req.end();
docker build -t stream-client:2.0 -f Dockerfile.client .
docker run --rm stream-client:2.0
Cette fois, ça fonctionne, parfait !
Dans cet article, nous avons vu comment streamer des données entre deux instances Cloud Run avec Node.js. Cette configuration permet d'envoyer des données par fragments du client vers le serveur, ce dernier journalisant chaque fragment à mesure qu'il arrive.
Gardez à l'esprit que le protocole HTTP ne garantit pas que chaque appel à req.write() entraîne un événement data distinct côté serveur. Les fragments que nous envoyions au départ étaient assez petits et expédiés en succession rapide ; ils étaient donc reçus par le serveur dans un seul événement data.
Nous avons pu confirmer que le streaming fonctionnait en envoyant une quantité de données plus importante qui ne tenait pas dans un seul paquet TCP. Cela a forcé le découpage en plusieurs fragments, déclenchant à son tour plusieurs événements data côté serveur.
Encore une fois, HTTP/2 reste généralement préférable. Utilisez-le si possible.
J'espère que cet article vous a été utile ! Si vous avez des questions, n'hésitez pas à laisser un commentaire ci-dessous.