
Infrastructure as Code (IaC) ist anspruchsvoll. Häufig müssen Sie Infrastruktur aufsetzen – heute meist mit Terraform – und schreiben Code, der genau zu Ihrem Anwendungsfall passt.
In der Regel ist die Zeit knapp, und am Ende stehen sämtliche Default-Werte hartcodiert in ein oder zwei großen Dateien, die Ihre gesamte Arbeit enthalten. Viele denken sich dabei: "Ich bringe es jetzt erst einmal zum Laufen und kümmere mich später um Verbesserungen, wenn ich wieder Luft habe."
Infrastruktur terraformen – diesmal richtig.
Mit der Zeit kommt die nächste Aufgabe. Inzwischen haben Sie längst vergessen, was Sie genau getan haben, um es "erst einmal zum Laufen zu bringen". Oder eine Kollegin muss sich in Ihren Code einarbeiten, um zu verstehen, was er tut – damit er nun sowohl die alte als auch die neue Anforderung abdeckt.
Hinzu kommt die nackte Angst, etwas Funktionierendes kaputtzumachen, nur weil man es "besser machen" will.
Diesen Weg bin ich selbst schon oft gegangen, ohne einen Hebel zu finden, mit dem sich Terraform handhabbarer und einfacher debuggen lässt. Bis ich diesen Blogbeitrag von Yevgeniy Birkman gelesen habe: " 5 lessons learned from writing over 300,000 lines of infrastructure code".
Er hat mir wirklich die Augen geöffnet, wie sich Terraform robuster, sauberer und zugänglicher gestalten lässt – und vor allem, wie man das nötige Vertrauen aufbaut, um anstehende Änderungen oder Verbesserungen anzugehen.
An dieser Stelle möchte ich einige eigene Tipps und Erfahrungen zum Refactoring von Terraform teilen. Das Folgende ist eine Zusammenfassung der Slides, die Sie am Ende dieses Artikels finden.
Monolithisches Terraform
In einer großen TF-Datei kann ein einziger kleiner Fehler alles zerlegen. Außerdem wird das Debuggen deutlich aufwendiger, und allein die Stelle zu finden, an der Sie ansetzen müssen, kostet unnötig viel Zeit. Auf Dauer führt dieses Muster zu Code-Duplizierung und langsameren Entwicklungszyklen.
Der 10.000-ft-View-Ansatz
Beim Arbeiten mit Terraform ist es entscheidend, beim Entwickeln oder beim Debuggen eines kritischen Problems schnell genau die Stelle zu finden, die man sucht.
Der Terraform-Plan fasst alle Dateien zu einer Ausführung zusammen – das lässt sich gezielt nutzen, indem Sie kleinere Dateien mit deutlich besserer Übersicht anlegen. Im Idealfall fügen sich diese kleineren Dateien zu einem wiederverwendbaren, kombinierbaren Modul zusammen.
Anatomie eines Moduls
Die "300.000 Zeilen Infrastruktur-Code" waren ein hervorragender Ausgangspunkt. Ich bin noch einen Schritt weiter gegangen und habe ein Scaffold erstellt, das ich für jedes Modul verwende. Es sorgt für mehr Übersicht und gibt klare Leitlinien für die Modulentwicklung.
Es gibt keine hartcodierten Werte – jeder hartcodierte Wert wird zu einer Default-Variable, und jedes Modul-Attribut ist eine Variable (einige Pflicht, andere mit Default). Jedes Modul sollte folgende Struktur haben:
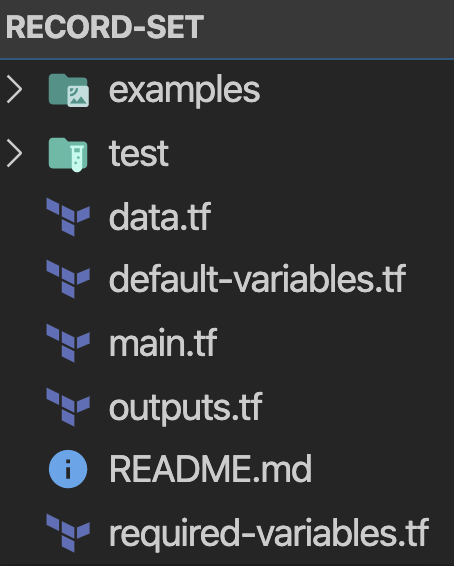
Die Idee: Elemente gehören dorthin, wo sie hingehören. Wird die main.tf länger als 30 Zeilen, teilen Sie sie in logische Dateien auf – z. B. ec2.tf, autoscaling.tf usw.
Bewährt hat sich ein Ordner "examples", der sowohl der Entwicklung des Moduls dient als auch später als Verwendungsbeispiel. Wenn ich ein neues Modul beginne, lege ich das Scaffold mit folgendem Snippet an:
➜ export module_name="sample"➜ mkdir -p $module_name/examples $module_name/test➜ cd $module_name && touch \ main.tf \ versions.tf \ default-variables.tf \ required-variables.tf \ outputs.tf \ data.tf3-Tier-Modulstruktur
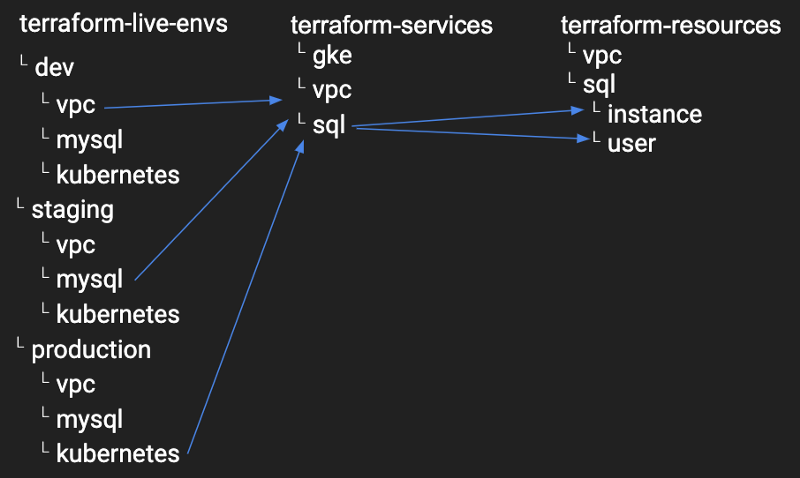
Bauen Sie sich eine eigene Bibliothek aus elementaren Bausteinen auf und erweitern Sie sie kontinuierlich (terraform-resources).

Aus diesen Bausteinen setzen Sie anschließend Services zusammen (terraform-services).

Aus diesen Services lassen sich End-to-End-Umgebungen ausrollen (terraform-live-envs).

Ziel ist es, jede (Live-)Umgebung (Dev, Staging, Production) zu isolieren, jede einzelne Komponente daraus herauszulösen und in generische Service-Module zu zerlegen. Jedes generische Service-Modul zerlegen Sie wiederum in Resource-Module, damit jedes Modul genau eine Aufgabe erfüllt und so entkoppelt wie möglich bleibt.
Schauen wir uns das an einem Beispiel an:
Sie betreiben eine MySQL-Instanz auf Google Cloud SQL (terraform-live-envs), die auf einem generischen Service namens "sql" aufsetzt, der wiederum zwei Resource-Module enthält (instance & user).
Terraform-Code refactoren
Legen Sie einen neuen Bucket an, in dem der neue Terraform-State abgelegt wird. Schreiben Sie anschließend Ihren neuen Code in die 3-Tier-Module um (wie oben dargestellt und in den Slides ausführlich beschrieben). Importieren Sie jede Ressource in Ihren live-envs-Terraform-Code.
Terraform zeigt Ihnen daraufhin den Execution-Plan für den Import:
[1] Werte, die in der deployten Version vorhanden sind, in Ihrem Code aber nicht, werden mit einem Minuszeichen zur Entfernung markiert.
[2] Werte, die in der deployten Version fehlen, in Ihrem Code aber existieren, werden mit einem Pluszeichen zum Hinzufügen markiert.
Ihr Ziel: einen Stand erreichen, an dem der Plan keinerlei Änderungen mehr anzeigt.
Slides
Die folgenden Slides enthalten eine kurze Einführung in Terraform sowie meine Vorschläge zum Refactoring bestehender Terraform-Module: 