
L'Infrastructure as Code (IaC), c'est compliqué. Vous devez souvent déployer une infrastructure (aujourd'hui le plus souvent avec Terraform) et vous commencez à écrire du code taillé pour votre cas d'usage.
En général, le temps manque et l'on finit par coder en dur toutes les valeurs par défaut, en concentrant l'ensemble du travail dans un ou deux gros fichiers. Beaucoup se disent : je vais déjà faire en sorte que ça tourne, je verrai plus tard comment améliorer tout ça quand j'aurai un peu de temps.
Terraformer l'infrastructure, cette fois-ci de la bonne façon.
Le temps passe, et une nouvelle tâche vous arrive. À ce stade, vous avez déjà oublié ce que vous aviez exactement bricolé pour que ça tourne. Ou bien quelqu'un d'autre doit se plonger dans votre code pour comprendre ce qu'il fait, afin de l'adapter à la fois à l'ancien périmètre et à la nouvelle tâche.
S'y ajoute la peur tenace de casser ce qui fonctionne, simplement parce qu'on cherche à faire mieux.
J'ai parcouru cette route à de nombreuses reprises, sans trouver le moyen de rendre Terraform plus accessible et plus facile à déboguer. Jusqu'à ce que je tombe sur cet article de Yevgeniy Birkman : 5 lessons learned from writing over 300,000 lines of infrastructure code.
Il m'a vraiment ouvert les yeux : comment rendre Terraform plus robuste, plus propre, plus accessible et, surtout, comment gagner la confiance nécessaire pour apporter les changements ou améliorations indispensables.
J'aimerais maintenant partager quelques conseils et retours d'expérience personnels sur le refactoring Terraform. Ce qui suit est une synthèse des slides que vous trouverez à la fin de cet article.
Terraform monolithique
Lorsqu'on travaille dans un gros fichier TF, la moindre erreur peut tout casser. Terraform devient aussi beaucoup plus difficile à déboguer, et retrouver l'endroit ou la section sur laquelle intervenir vire au parcours du combattant. Ce schéma finit par entraîner duplication de code et cycles de développement plus lents.
Vue à 10 000 pieds
Pouvoir trouver rapidement ce que l'on cherche, en plein développement ou lors du débogage d'un incident critique, est essentiel quand on travaille avec Terraform.
Le plan Terraform consolide tous les fichiers en une seule exécution : autant en tirer parti en créant des fichiers plus petits, bien plus lisibles. En général, ces petits fichiers s'agrègent en un module plus réutilisable et plus composable.
Anatomie d'un module
Les 300 000 lignes de code d'infrastructure ont été un excellent point de départ, et je suis allé un cran plus loin en créant un squelette que je réutilise sur chaque module. Ce squelette apporte une meilleure lisibilité et balise le développement d'un module.
Aucune valeur n'est codée en dur : chaque valeur en dur devient une variable par défaut, et chaque attribut du module est une variable (certaines obligatoires, d'autres avec valeur par défaut). Chaque module doit suivre la structure suivante :
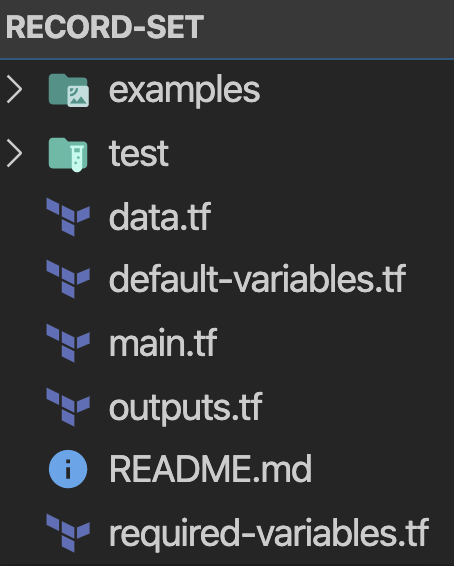
L'idée : placer chaque élément à sa place. Si le fichier main.tf dépasse 30 lignes, scindez-le en fichiers logiques (ec2.tf, autoscaling.tf, etc.).
Bonne pratique : utiliser le dossier examples pour le développement du module, qui sert ensuite d'exemple d'utilisation. Lorsque je démarre un nouveau module, j'utilise le snippet suivant pour générer ce squelette :
➜ export module_name="sample"➜ mkdir -p $module_name/examples $module_name/test➜ cd $module_name && touch \ main.tf \ versions.tf \ default-variables.tf \ required-variables.tf \ outputs.tf \ data.tfStructure des modules en 3 niveaux
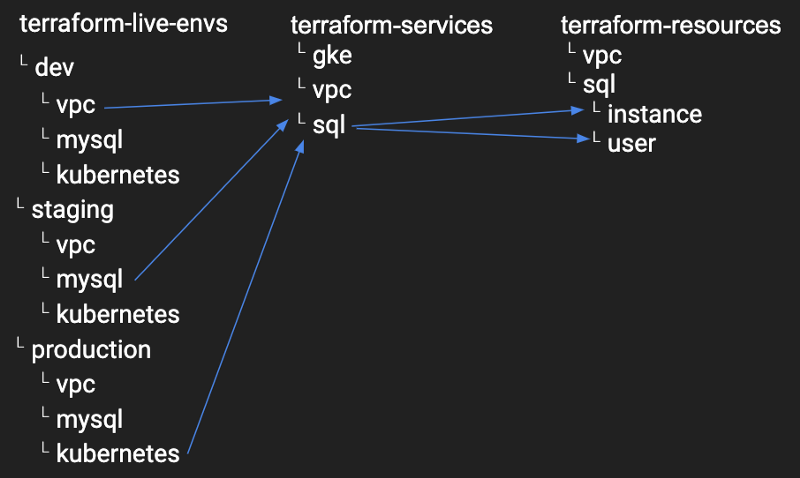
Constituez et enrichissez votre propre bibliothèque de briques élémentaires (terraform-resources).

Assemblez ensuite des services à partir de ces briques (terraform-services).

Déployez enfin des environnements de bout en bout à partir des services (terraform-live-envs).

L'objectif : isoler chaque environnement (dev, staging, production), puis prendre chaque composant et le décomposer en modules de service génériques. Décomposez ensuite chaque module de service générique en modules de ressources : chaque module ne doit faire qu'une seule chose, et rester aussi découplé que possible.
Prenons l'exemple suivant.
Vous avez une instance mySQL déployée sur Google Cloud SQL (terraform-live-envs), bâtie sur un service générique nommé sql qui contient deux modules de ressources (instance et user).
Refactoriser le code Terraform
Créez un nouveau bucket destiné à stocker le nouvel état Terraform. Réécrivez ensuite votre code selon la structure à 3 niveaux (illustrée plus haut et détaillée dans les slides). Importez chacune des ressources dans votre code Terraform live-envs.
Terraform affichera alors le plan d'exécution de l'opération d'import :
[1] les valeurs présentes dans la version déployée mais absentes de votre code seront marquées d'un signe moins, signalant leur suppression.
[2] les valeurs absentes de la version déployée mais présentes dans votre code seront marquées d'un signe plus, signalant leur ajout.
L'objectif : arriver à un point où aucun changement n'apparaît dans le plan.
Slides
Les slides ci-dessous proposent une brève introduction à Terraform, ainsi que mes recommandations pour refactoriser des modules Terraform existants : 