
L'Infrastructure as Code (IaC) non è semplice. Spesso si parte a scrivere codice su misura per il proprio caso d'uso, mettendo in piedi l'infrastruttura (oggi quasi sempre con Terraform).
Di solito il tempo a disposizione è poco e si finisce per inserire in modo statico tutti i valori di default, concentrando l'intero lavoro in uno o due file enormi. In molti pensano: "Per ora lo faccio funzionare, poi quando avrò un po' di tempo in più vedrò come migliorarlo".
Terraforming dell'infrastruttura, questa volta fatto bene.
Passa il tempo e arriva un altro task. A quel punto si è già dimenticato cosa esattamente si era fatto per "farlo funzionare al volo". Oppure tocca a qualcun altro mettere il naso nel codice per capire cosa fa, in modo da adattarlo sia al lavoro precedente sia al nuovo task.
E poi c'è il timore enorme, quasi paralizzante, di rompere qualcosa che funziona solo per la voglia di "migliorarlo".
Mi sono ritrovato su questa strada parecchie volte, senza riuscire a trovare un modo per rendere Terraform un po' più amichevole e più facile da debuggare. Finché non ho letto questo articolo di Yevgeniy Birkman: "5 lessons learned from writing over 300,000 lines of infrastructure code".
Mi ha davvero aperto gli occhi su come rendere Terraform più solido, pulito e amichevole e, soprattutto, su come acquisire la sicurezza necessaria per apportare le modifiche o i miglioramenti del caso.
Vorrei ora condividere alcuni consigli ed esperienze personali sul refactoring di Terraform. Quanto segue è un riepilogo delle slide che trovate in fondo all'articolo.
Terraform monolitico
Quando si lavora dentro un file TF di grandi dimensioni, basta un piccolo errore per mandare tutto in tilt. Terraform diventa anche molto più difficile da debuggare e individuare il punto o la sezione su cui intervenire si trasforma in un'attività dispendiosissima. Un pattern che porta inevitabilmente a duplicazione di codice e a cicli di sviluppo più lenti.
Approccio a vista d'insieme
Riuscire a trovare in fretta ciò che serve durante lo sviluppo o il debug di un problema critico è essenziale quando si lavora con Terraform.
Il piano di Terraform consolida tutti i file in un'unica esecuzione e possiamo sfruttarlo a nostro vantaggio creando file più piccoli, con una visibilità decisamente migliore. Di norma, questi file più piccoli si compongono in moduli più riutilizzabili e componibili.
Anatomia di un modulo
Le "300000 righe di infrastructure code" sono state un ottimo punto di partenza e ho fatto un passo in più, creando uno scaffold che utilizzo in ogni modulo. Questo scaffold offre maggiore visibilità e linee guida per lo sviluppo di un modulo.
Non ci sono valori hard-coded: ogni valore hard-coded diventa una variabile di default e ogni attributo del modulo è una variabile (alcune obbligatorie, altre con valore di default). Ogni modulo dovrebbe avere la seguente struttura:
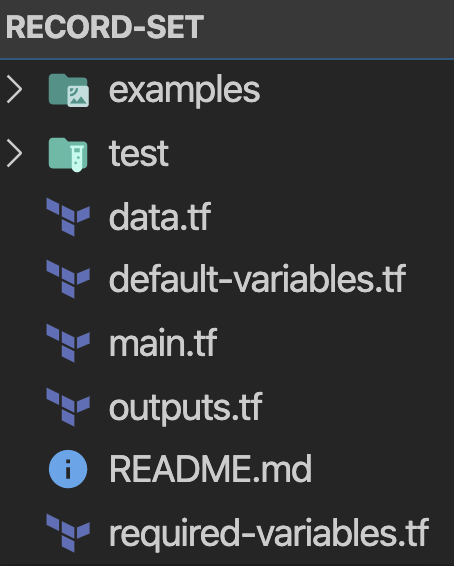
L'idea è mettere ogni elemento al posto giusto. Se il file main.tf supera le 30 righe, suddividetelo in file logici, ad esempio ec2.tf, autoscaling.tf, ecc.
Una buona pratica è usare la cartella 'examples' per lo sviluppo del modulo e, allo stesso tempo, come esempio d'uso a cui fare riferimento in futuro. Quando inizio un nuovo modulo, uso il seguente snippet per creare lo scaffold:
➜ export module_name="sample"➜ mkdir -p $module_name/examples $module_name/test➜ cd $module_name && touch \ main.tf \ versions.tf \ default-variables.tf \ required-variables.tf \ outputs.tf \ data.tfStruttura dei moduli a 3 livelli
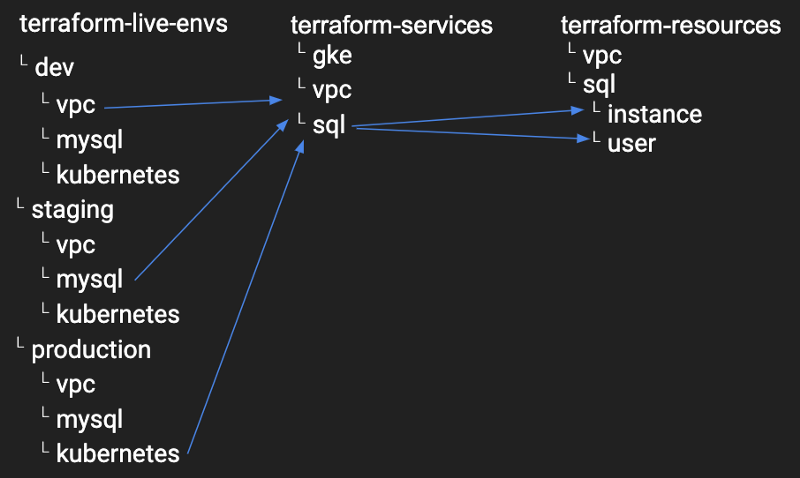
Crea ed estendi la tua libreria di blocchi primitivi (terraform-resources)

Poi costruisci i servizi a partire da questi blocchi primitivi (terraform-services)

Infine, distribuisci ambienti end-to-end a partire dai servizi (terraform-live-envs)

L'obiettivo è isolare ciascun ambiente (live) — dev, staging, production — per poi prendere ogni componente di quell'ambiente e suddividerlo in moduli di servizio generici. A loro volta, ogni modulo di servizio generico va spezzato in moduli di risorsa: ciascun modulo dovrebbe fare una cosa sola ed essere il più possibile disaccoppiato.
Vediamolo con un esempio:
Avete un'istanza mySQL deployata su Google Cloud SQL (terraform-live-envs) costruita sopra un servizio generico chiamato "sql" che contiene due moduli risorsa (instance e user).
Refactoring del codice Terraform
Crea un nuovo bucket in cui verrà memorizzato il nuovo state di Terraform. Quindi riscrivi il nuovo codice nei moduli a 3 livelli (come illustrato sopra e dettagliato nelle slide). Importa ciascuna risorsa nel codice Terraform live-envs.
Terraform mostrerà quindi il piano di esecuzione per l'operazione di import:
[1] i valori presenti nella versione deployata ma non nel codice saranno contrassegnati con il segno meno per la rimozione.
[2] i valori non presenti nella versione deployata ma presenti nel codice saranno contrassegnati con il segno più per l'aggiunta.
L'obiettivo è arrivare al punto in cui il piano non riporta più alcuna modifica.
Slide
Le slide seguenti contengono una breve introduzione a Terraform e i miei consigli su come fare refactoring dei moduli Terraform esistenti: 