Einleitung
Die jüngste Ankündigung von Google Cloud, die Dataplex API ab dem 4. März 2024 für alle BigQuery-Kunden standardmäßig zu aktivieren, eröffnet spannende Möglichkeiten für erweiterte Analysefunktionen.
ABER: Diese Änderung birgt auch erhebliche Kostenrisiken! Vor allem angesichts der Funktionsweise der Dataplex API selbst sowie ergänzender APIs wie der Data Lineage API und der Data Catalog API.
In diesem Blogbeitrag schauen wir uns die Neuerung im Detail an, beleuchten die Kostenfolgen und zeigen Strategien, um diese Effekte abzufedern – so wie ich es gemeinsam mit meinem Kollegen Sayle Matthews, ebenfalls Google Data Practice Lead bei DoiT, in unserem Webinar am 29. Februar und in diesem LinkedIn-Beitrag bereits dargestellt habe.
Die Änderung im Detail
In einer E-Mail des Google Cloud Teams an alle Google-BigQuery-Nutzer Mitte Februar mit dem Betreff "[Action Advised] Review the updates to BigQuery to confirm if you need to take action on your projects" wurde bekannt gegeben, dass die Dataplex API ab dem 4. März 2024 automatisch für alle aktiven BigQuery-Projekte aktiviert und für neue Google-Cloud-Projekte standardmäßig eingeschaltet wird.
Dieser Schritt ist Teil des umfassenderen BigQuery-Studio-Launchs (Link) und soll Nutzern nahtlos zusätzliche Funktionen einer Analyseplattform bereitstellen.
Die wichtigsten Punkte dieser E-Mail sehen Sie unten – sie weist auch auf weitere APIs hin, die im Zuge der Änderungen am 4. März automatisch aktiviert werden:
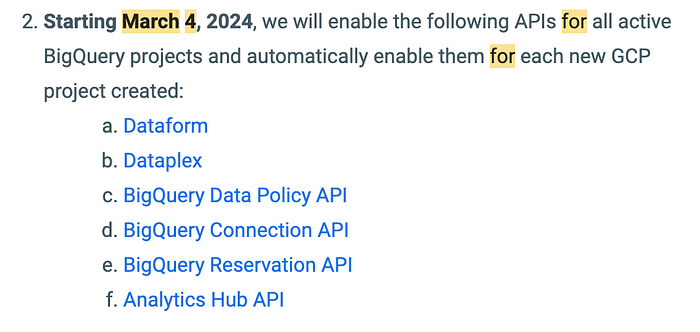
Die Aktivierung des Dataplex-Dienstes selbst sowie der zugehörigen APIs wie Data Catalog und Data Lineage gibt unter den oben genannten Punkten den größten Anlass zur Sorge.
Für diesen Blogbeitrag ist anzumerken, dass laut Sayle Matthews' LinkedIn-Beitrag in der Woche ab dem 26. Februar ein größeres neues Dataplex-Release von Google ausgerollt wurde, das einige dieser Bedenken rund um die automatische Aktivierung kostenpflichtiger Funktionen ausräumt. Glücklicherweise sind dadurch nun deutlich weniger Nutzer potenziell betroffen.
Auswirkungen von Dataplex auf die GCP-Kosten
Die Einführung von Dataplex eröffnet GCP-Kunden zwar das Potenzial für fortgeschrittene Daten-Governance- und Management-Funktionen, doch sollten Sie sich der möglichen Kostenfolgen der automatischen Aktivierung ab dem 4. März bewusst sein.
Dataplex bringt Funktionen und im Hintergrund laufende Prozesse mit sich, die mit verschiedenen Google-Cloud-Datendiensten und -APIs verzahnt sind – etwa Google BigQuery, Cloud Dataflow und Cloud Pub/Sub. Wenn Sie diese Änderung in Ihren GCP-Projekten nicht aktiv steuern, können daraus höhere Kosten entstehen!
Laut der zentralen Dataplex-Preisseite rechnet Dataplex über vier Haupt-SKUs ab, die jeweils unterschiedlich abgerechnet werden:
- Dataplex Processing (Standard und Premium)
- Dataplex Shuffle Storage
- Data Catalog API-Aufrufe
- Data Catalog Metadaten-Speicher
Den größten Einfluss auf Ihre Dataplex-Kosten hat die Processing-SKU. Sie wird zum Zeitpunkt dieses Beitrags in DCU-Stunden abgerechnet (0,060 USD pro DCU-Stunde für Standard Dataplex Processing und 0,089 USD für Premium Dataplex Processing, wobei die Preise je nach Region variieren können).
Die folgende Tabelle aus der Dataplex-Preisseite zeigt im Detail, wie Dataplex Processing in der Praxis abgerechnet wird:
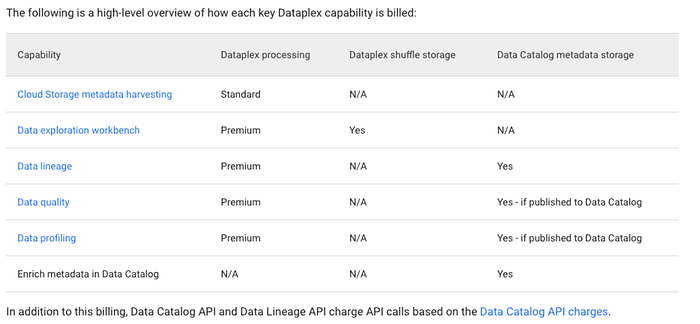
Wie oben dargestellt, kann die Dataplex Processing-SKU eine ganze Reihe von Funktionen auf Ihren GCP-Datenquellen ausführen, wenn man sie ungebremst laufen lässt (und das ist noch bevor wir auf die zugehörigen Data Lineage- und Data Catalog-APIs eingehen!). Aber wie funktioniert die Dataplex Processing-SKU eigentlich genau?
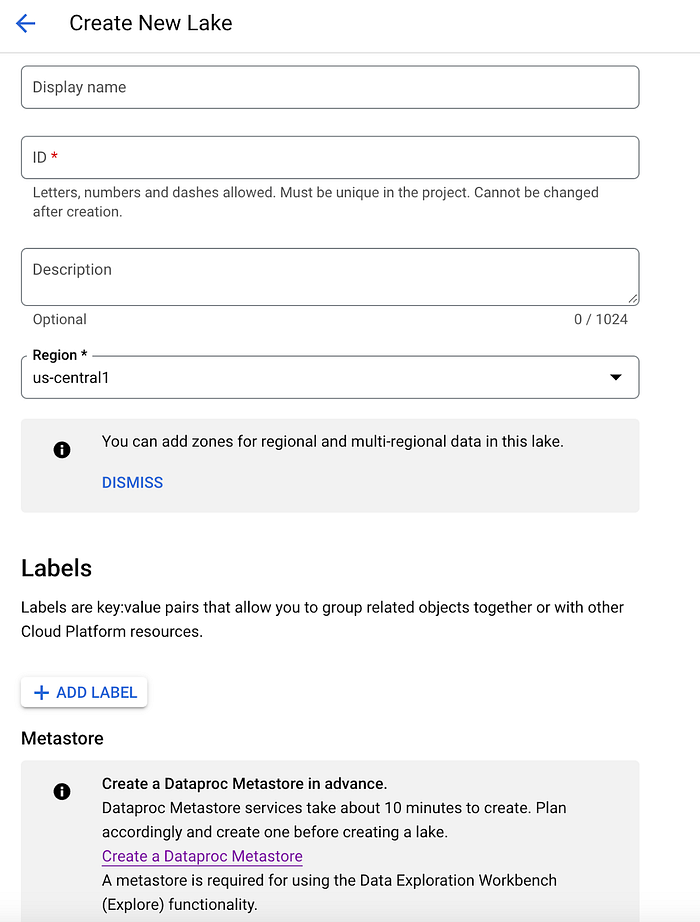
Die Antwort liegt im Anlegen von Dataplex Lakes und Zones. In Dataplex ist ein Lake im Grunde eine Data-Mesh-Domäne, die – wie unten gezeigt – die Daten-Artefakte einer Geschäftseinheit bündelt. Lakes können wiederum Zones, Assets und Entities enthalten, um Ihre Daten gemäß Ihren eigenen Geschäfts- und Datenstrukturen in Google BigQuery, GCS usw. zu verwalten.

Beim Anlegen eines Dataplex Lake (Link) müssen Sie nach Angabe von Name, Region und gewünschten Labeling-Richtlinien den Lake zusätzlich mit einem Dataproc Metastore verknüpfen.
Das ist ein wesentlicher Treiber der Gesamtkosten für Dataplex Processing: Dataplex nutzt den Metastore, um die Verarbeitung der Data-Exploration-Workbench zu steuern, und der Betrieb des Metastore wirkt sich zudem auf Ihre Dataproc-Kosten aus. Der Metastore ist außerdem in verschiedenen Tiers verfügbar (Developer- und Enterprise-Tier für Metastore v1 sowie Enterprise und Enterprise Plus für v2), die je nach Ihren Anforderungen unterschiedlich ausgestattet und bepreist sind – Details finden Sie hier.
Sobald Ihr Dataplex Lake erstellt ist, beginnt die Dataplex API mit der Verarbeitung und dem Scannen Ihrer Daten gemäß den zuvor beschriebenen Data-Exploration-Prozessen. Ab diesem Zeitpunkt erscheinen die Processing-SKUs in Ihrer Google-Cloud-Abrechnung – und genau hier können die Kosten in die Höhe schnellen!
Wichtig zu wissen: Dataplex selbst zusammen mit einem Dataproc Metastore stößt zwar bereits einige kostenintensive Prozesse an, weitere Dienste unter dem Dataplex-Dach – etwa Data Lineage, Data Profiling, Data Catalog und Data Quality – müssen aber erst aktiviert werden, damit Kosten anfallen. Dieser Beitrag konzentriert sich vor allem auf die Lineage- und Catalog-APIs, da hier typischerweise die größten Kostenfolgen für unsere Kunden entstehen.
Die Data Lineage API scannt – wie der Name schon andeutet – alle in Dataplex definierten Datenprozesse und verfolgt sämtliche Operationen nach, die zur Entstehung Ihrer Assets geführt haben. Beispiele sind BigQuery-Jobs, Dataflow-Pipelines oder Pub/Sub- bzw. Dataproc-Operationen, die Ihre Assets verändert haben. Was zunächst harmlos klingt, kann pro Operation zu einer enormen Anzahl an API-Aufrufen führen – und das schlägt direkt auf die Preisgestaltung der Data Lineage API durch, wie unten erläutert.
Die Data Catalog API ist – wie die Data Lineage API – ein weiterer separater Dienst, der erst aktiviert werden muss. Sie arbeitet direkt mit Data Lineage zusammen, um Metadaten zu Ihren Operationen zu speichern, und erzeugt darüber hinaus mit den meisten Diensten unter dem Dataplex-Dach API-Aufrufe aus Operationen rund um Dataplex und insbesondere die Data Lineage API.
Der folgende Screenshot von Googles Dataplex-Preisseiten zeigt die Aufschlüsselung Ihrer Data-Lineage- und Data-Catalog-Kosten im Detail.
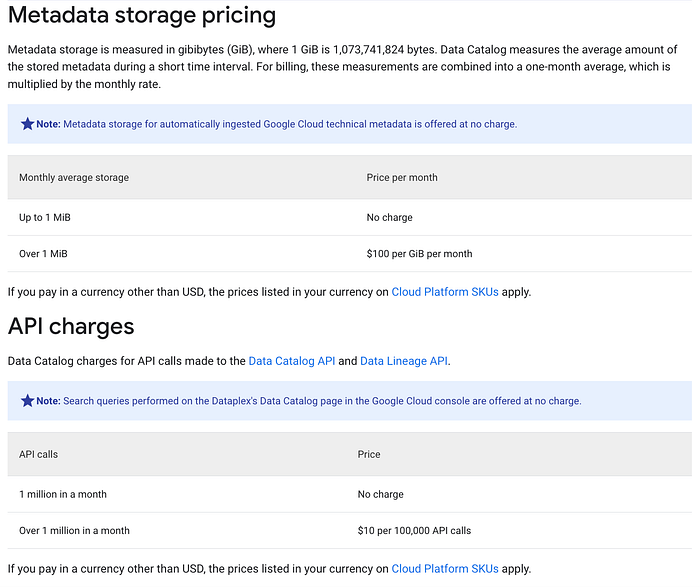
Wie erwähnt, werden beide APIs auf Basis von API-Aufrufen abgerechnet. Je nach Skalierung der von Ihnen genutzten Datendienste in Google Cloud können diese Aufrufe schnell in die Millionen gehen – und damit zu einem signifikanten Kostenposten werden, sobald beide APIs aktiv sind.
Zudem nutzt auch Data Catalog den Dataproc Metastore zur Speicherung von Metadaten. Wie bei Dataplex hängen die Kosten dabei von der eingesetzten Metastore-Version sowie natürlich vom Volumen der gespeicherten Metadaten ab.
Die Gesamtkosten von Dataplex abschätzen
Eine der häufigsten Fragen unserer Kunden zu diesen Dataplex-Änderungen lautet: "Wie können wir abschätzen, was uns all diese Dataplex-Komponenten kosten werden?" Die kurze Antwort: Es gibt leider keinen einfachen Weg, das vorab zu beziffern.
Unsere Engineers haben in direkten Gesprächen mit Google herausgefunden, dass sich ein bestimmter Prozess nicht eindeutig einem konkreten Dataplex-API-Aufruf zuordnen lässt. Eine Schätzung dieses Kostenanteils ist daher praktisch unmöglich.
Auch die Processing-Kosten lassen sich nur schwer prognostizieren. Dokumentiert ist immerhin, dass diese linear proportional zur Datenmenge in Ihren Dataplex Lakes anfallen.
Auch wenn das nicht die schnelle, klare Antwort ist, die Sie sich vielleicht erhoffen: Mit einem sauberen Management Ihrer Dataplex-APIs und -Dienste lassen sich ALLE diese Kostenkomponenten zuverlässig in den Griff bekommen!
Maßnahmen gegen diese zusätzlichen Kosten – Ihre Optionen
Dataplex und zugehörige APIs vollständig deaktivieren
Wer die fortgeschrittenen Dataplex-Funktionen aktuell nicht einsetzt oder keine unmittelbaren Pläne für die Daten-Governance-Features hat, kann erwägen, Dataplex und seine APIs vollständig zu deaktivieren.
Am einfachsten geht das über die Google Cloud Console: Über die passend benannte Konsolenseite "APIs und Dienste" lassen sich beliebige APIs ein- und ausschalten.
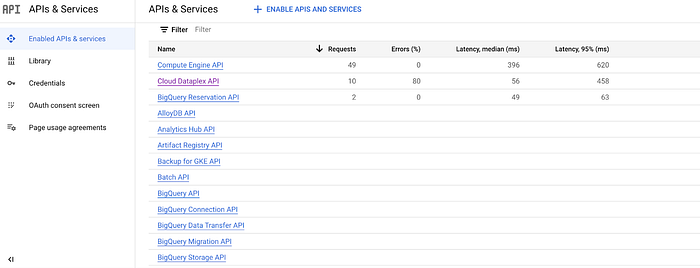
Wenn Sie diese Seite in der Google Cloud Console aufrufen, sehen Sie eine Übersicht ähnlich der oben gezeigten mit allen aktivierten APIs und Diensten. Von dort aus können Sie nach der gewünschten API suchen – etwa Cloud Dataplex, Data Catalog oder Data Lineage – und mit einem Klick auf "API deaktivieren" (siehe Screenshot unten) die API samt aller damit verbundenen Kosten und Operationen abschalten.
In unserem zugehörigen Webinar fragten uns mehrere Kunden, ob sich dieser Prozess auch programmatisch über Kommandozeilen-Skripte erledigen lässt. Die Antwort lautet: Ja. Das folgende Skript lässt sich auf eine bestimmte API in Ihren Google-Cloud-Projekten anwenden, um diese programmatisch zu deaktivieren:
gcloud services disable API_SERVICE_NAME — project PROJECT_ID
Das obige Skript funktioniert nicht automatisch, wenn die API in den letzten 30 Tagen genutzt wurde. In diesem Fall müssen Sie zusätzlich die Option --force nach dem API-Service-Namen anhängen, um die Dataplex-APIs erfolgreich zu deaktivieren.
Ein ähnliches Skript lässt sich auch über Ihre gesamte GCP-Organisation hinweg ausführen, falls Sie diesen Prozess für mehrere Projekte in Ihrer GCP-Organisation durchlaufen müssen. Ein Beispiel:
API_TO_DISABLE=API_SERVICE_NAME
for PROJECT_ID in $(gcloud projects list –filter='parent.id=ORG_ID' — format='value(projectId)')
do
echo "Processing $PROJECT_ID"
# Disable the API for the project
echo "Disabling $API_TO_DISABLE in $PROJECT_ID"
gcloud services disable $API_TO_DISABLE — project $PROJECT_ID
done
Praktischerweise hat Google in der ursprünglichen E-Mail vom 16. Februar zudem einen Formular-Link bereitgestellt, mit dem die ab dem 4. März 2024 zur Aktivierung vorgesehenen APIs in Ihren Projekten automatisch unterdrückt werden. Falls Sie oder eine berechtigte Person in Ihrer Organisation diesem Link bereits gefolgt sind, sollten alle relevanten APIs in diesem Fall bereits deaktiviert sein.
Im Rahmen dieses Blogbeitrags möchten wir betonen: Sie sollten APIs und Dienste in Google Cloud nur dann deaktivieren, wenn Sie sicher sind, dass diese von keinem Ihrer Geschäftsprozesse genutzt werden. Daher sollten die obigen Skripte ausschließlich auf spezifische Dataplex-bezogene APIs angewendet werden – und nur dann, wenn Sie sicher sind, dass Sie selbst keine Dataplex Data Lineage- oder Data Catalog-Prozesse einsetzen.
Selektive Aktivierung von Dataplex-Funktionen
Wer die Balance zwischen erweiterter Daten-Governance und Wirtschaftlichkeit wahren und Dataplex dennoch nutzen möchte, fährt mit einer selektiven Aktivierung einzelner Dataplex-Funktionen am besten.
Durch eine sorgfältige Bewertung der für die jeweiligen Projekte tatsächlich benötigten Dataplex-Funktionen und -APIs lassen sich gezielt nur jene Features einschalten, die zu den eigenen Anforderungen passen. Wir empfehlen Google-Cloud-Nutzern dringend, sich genau zu überlegen, wofür sie Dataplex einsetzen wollen, und – falls die Entscheidung dafür fällt – mit den aktivierten Funktionen und APIs vorsichtig umzugehen.
Google-Cloud-Nutzern, die Dataplex einsetzen möchten, raten wir außerdem dazu, ein einziges "Admin"-GCP-Projekt einzurichten, in dem die gesamte Dataplex-Funktionalität läuft. So minimieren Sie Kosten und Komplexität nach dieser Änderung. Damit lassen sich die Auswirkungen der vielen API-Aufrufe sowie der Processing- und Metadata-Storage-Gebühren begrenzen, die andernfalls beim Einsatz von Dataplex und seinen Funktionen über mehrere Projekte Ihrer Google-Cloud-Organisation hinweg entstehen können.
Kontinuierliches Monitoring und Optimierung
Eine kontinuierliche Überwachung Ihrer Dataplex-bezogenen Kosten ist unerlässlich. Google Cloud bietet detaillierte Tools für Abrechnung und Kostenmanagement, mit denen Nutzer ihre Ausgaben im Blick behalten. Beispiele dafür sind Google Cloud Billing, Cloud Monitoring und Cloud Logging. Damit lassen sich direkte Ausgaben nach SKU verfolgen, die Nutzung über übersichtliche Dashboards einsehen und einzelne Logging-Einträge rund um Dataplex und die genannten APIs auswerten.
Durch regelmäßige Auswertung dieser Berichte und Service-Ausgaben lassen sich unerwartete Kostenspitzen frühzeitig erkennen und zeitnah Optimierungen anstoßen.
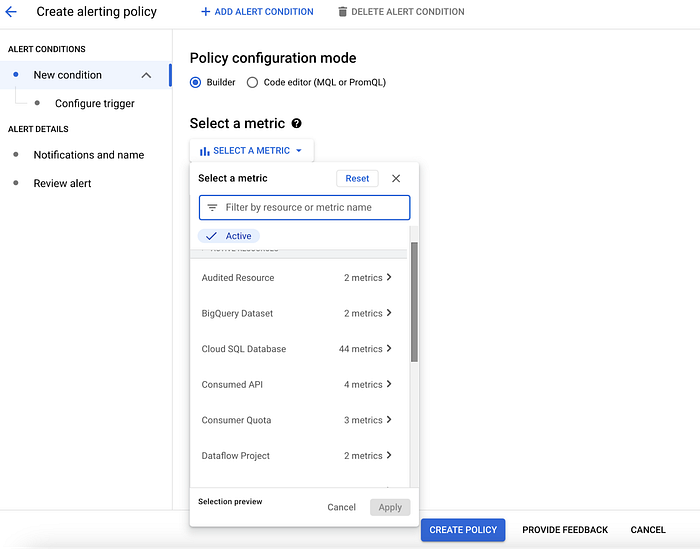
Nutzer können zudem über Cloud Monitoring Policies Alerts einrichten – wie im Screenshot gezeigt –, um proaktiv Schwellenwertüberschreitungen bei den von ihnen ausgewählten Nutzungsmetriken zu verfolgen, beispielsweise rund um den Dataplex-Dienst und die damit verbundenen Ressourcen.
Fazit
Die anstehende Standardaktivierung der Dataplex API in Google-BigQuery-Projekten bringt für Google-Cloud-Kunden sowohl Chancen als auch Herausforderungen mit sich.
Wer die Auswirkungen versteht und proaktive Strategien zum Kostenmanagement umsetzt, kann die wachsenden Möglichkeiten von BigQuery und Dataplex weiter ausschöpfen – und gleichzeitig wirtschaftlich arbeiten.
Die in diesem Beitrag empfohlenen Maßnahmen, ergänzt durch die Erkenntnisse der Branchenexperten von DoiT, helfen Google-BigQuery-Nutzern dabei, diese Änderung erfolgreich zu meistern und ihre Google-Cloud-Nutzung sowie -Ausgaben im Anschluss zu optimieren.
Zum Abschluss noch ein paar Worte zu uns bei DoiT International. Unsere Kunden bei Analysen und langfristiger Planung nach weitreichenden Änderungen wie dieser zu unterstützen, gehört zu unseren zentralen Aufgaben.
Falls Sie noch kein DoiT-Kunde sind, schauen Sie als Leser dieses Beitrags gerne auf unseren Seiten vorbei – Sie finden uns hier. Bei DoiT haben wir ein außerordentlich versiertes und erfahrenes Team, helfen unseren Kunden dabei, das Beste aus ihren Google-Cloud-Ressourcen (sowie AWS und Azure) herauszuholen, und veröffentlichen kontinuierlich Blogs und Webinare wie dieses, um sie bestmöglich durch solche Änderungen zu begleiten.
Vielen Dank fürs Lesen – wir hoffen, dass dieser Beitrag, unsere weiteren Inhalte und unser erfahrenes Team Ihnen dabei helfen, die anstehenden Änderungen rund um BigQuery und Dataplex erfolgreich zu meistern!
Zusätzliche FAQs
Neben dem LinkedIn-Artikel von Sayle Matthews, ebenfalls von DoiT, hier, der die weiterreichenden Folgen dieser BigQuery-Änderung ab dem 4. März beleuchtet, haben Sayle und ich am Donnerstag, dem 29. Februar 2024, ein Webinar zum gleichen Thema veranstaltet (verlinkt hier). Dort wurden uns weitere Fragen zu diesem Thema gestellt. Eine Auswahl unserer Antworten finden Sie unten als Referenz für unsere Leser (alle Antworten in voller Länge hören Sie über den Webinar-Link selbst):
F1: Was wäre der beste (am wenigsten aufwendige) Weg, um über mehr als 100 GCP-Projekte hinweg nach diesen aktivierten APIs zu "scannen"?
Antwort: Siehe das oben im Hauptteil bereitgestellte Skript. Wir möchten an dieser Stelle aber nochmals betonen: APIs in einem Rutsch zu deaktivieren, kann riskant sein. Deaktivieren Sie daher gezielt nur jene APIs, von denen Sie sicher wissen, dass sie für die Anforderungen Ihrer Organisation nicht benötigt werden.
F2: Wissen Sie, zu welcher Uhrzeit am 4. März wir diese APIs deaktivieren müssen?
Antwort: Google nennt zwar keine konkrete Tageszeit, ab der die Änderungen greifen. Wir empfehlen Google-Cloud-Nutzern jedoch, nicht benötigte APIs so früh wie möglich am 4. März oder direkt danach zu deaktivieren, um unvorhergesehene Auswirkungen auf ihre Google-Cloud-Rechnungen zu reduzieren. Viele Kunden werden von dieser Änderung zwar nicht betroffen sein, dennoch möchten wir, dass niemand böse Überraschungen auf der Rechnung erlebt.
F3: Wenn ich keinen der Dienste nutze, die Google hier automatisch aktiviert: Bleiben die Kosten unverändert, wenn ich die APIs nach dem 4. deaktiviere? (Wir nutzen hauptsächlich BigQuery)
Antwort: Das ist korrekt – nach der Änderung neulich gilt zum Glück durchgehend ein "Opt-in"-Modell. Wir empfehlen Ihnen dennoch, sicherzustellen, dass Sie die Data-Lineage-, Data-Catalog- und Data-Discovery-APIs zuvor abgeschaltet haben, damit keiner dieser Prozesse automatisch Kosten verursacht.
F4: Können wir die DoiT-Support-Console nutzen, um diese Dataplex-Kosten einzusehen bzw. nachzuverfolgen?
Antwort: Ja – wenn Sie nach dem Service "Dataplex" filtern, werden alle entsprechenden Posten aufgelistet. Wenn unsere Engineers Probleme analysieren, filtern wir in der Regel nach dem Service Dataplex und gruppieren anschließend nach SKU und Projekt. So sehen Sie die Kosten pro Projekt und SKU in der DoiT Console.