Introduzione
Il recente annuncio di Google Cloud sull'attivazione di default dell'API Dataplex per tutti i clienti BigQuery a partire dal 4 marzo 2024 apre prospettive interessanti sul fronte delle funzionalità analitiche avanzate.
ATTENZIONE però: questa modifica porta con sé implicazioni di costo potenzialmente pesanti, soprattutto considerando la natura dell'API Dataplex stessa e di API complementari come Data Lineage e Data Catalog.
In questo articolo entreremo nel dettaglio della novità, dell'impatto sui costi e delle strategie per mitigarne gli effetti, così come illustrato da me e dal collega Google Data Practice Lead di DoiT, Sayle Matthews, durante il webinar del 29 febbraio e in questo post su LinkedIn.
Cosa cambia, nel dettaglio
In una mail inviata a metà febbraio dal Google Cloud Team a tutti gli utenti di Google BigQuery, dal titolo "[Action Advised] Review the updates to BigQuery to confirm if you need to take action on your projects", è stato comunicato che dal 4 marzo 2024 l'API Dataplex sarà abilitata automaticamente per tutti i progetti BigQuery attivi e attivata di default sui nuovi progetti Google Cloud.
La scelta si inserisce nel più ampio lancio di BigQuery Studio (link), pensato per offrire agli utenti funzionalità aggiuntive di piattaforma analitica in modo trasparente.
Di seguito i punti salienti della mail, che evidenzia anche le altre API che verranno automaticamente abilitate con le modifiche del 4 marzo:
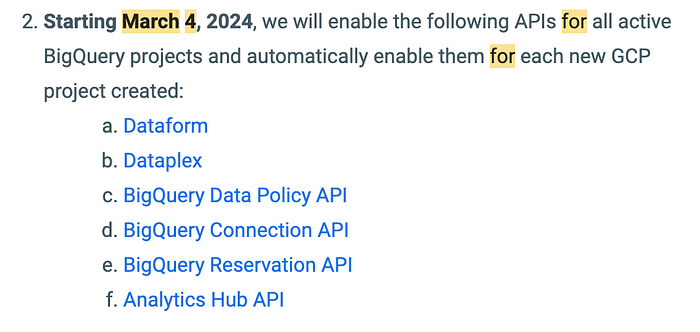
L'attivazione del servizio Dataplex e delle API a esso collegate, come Data Catalog e Data Lineage, è la principale fonte di preoccupazione tra le voci elencate.
Ai fini di questo articolo, vale la pena segnalare che, come riportato nel post LinkedIn di Sayle Matthews, nella settimana del 26 febbraio Google ha rilasciato un importante aggiornamento di Dataplex che ha risolto diverse criticità legate all'attivazione automatica di funzionalità a pagamento, riducendo per fortuna il numero di utenti potenzialmente impattati.
Le implicazioni di Dataplex sui costi GCP
Se da un lato Dataplex apre alle aziende clienti GCP funzionalità avanzate di data governance e gestione dei dati, dall'altro è fondamentale essere consapevoli delle possibili ricadute sui costi legate alla sua attivazione automatica dal 4 marzo.
Dataplex introduce funzionalità e processi sottotraccia che coinvolgono diversi servizi e API Google Cloud Data, ad esempio Google BigQuery, Cloud Dataflow e Cloud Pub/Sub: tutto ciò può tradursi in un aumento dei costi se non si gestisce questo cambiamento in modo efficace nei propri progetti GCP.
Come riportato nella pagina ufficiale dei prezzi, Dataplex prevede 4 SKU principali, con logiche di addebito differenti:
- Dataplex processing (standard e premium)
- Dataplex shuffle storage
- Chiamate API Data Catalog
- Storage di metadati Data Catalog
Tra questi, lo SKU di gran lunga più rilevante sui costi di Dataplex è quello di Processing, attualmente fatturato in DCU-ore (0,060 $ per DCU-ora per il Dataplex processing Standard e 0,089 $ per il Premium, con possibili variazioni in base alla regione).
La tabella seguente, tratta dalla pagina di pricing di Dataplex, mostra come viene fatturato il Dataplex processing nella pratica:
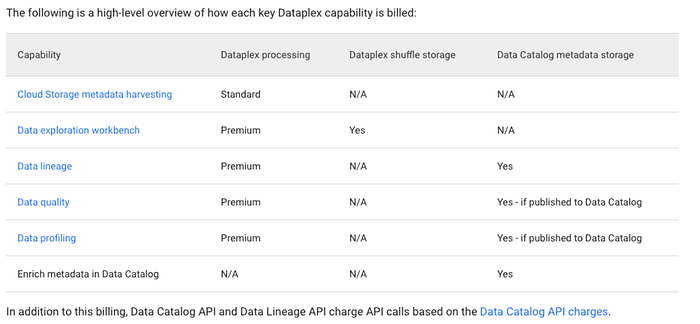
Come si vede, lo SKU di processing di Dataplex può svolgere parecchie funzioni sulle fonti dati GCP se lasciato libero di operare (e siamo ancora prima delle API associate a Data Lineage e Data Catalog). Ma come funziona davvero, in concreto, lo SKU Dataplex Processing?
La risposta passa dalla creazione di Dataplex Lake e Zone. In Dataplex un Lake è di fatto un dominio data mesh che raccoglie gli artefatti dati di una business unit (vedi sotto); i Lake possono a loro volta contenere Zone, Asset ed Entità per gestire i dati secondo le strutture aziendali e di dati all'interno di Google BigQuery, GCS e così via.

Quando si crea un Dataplex Lake (link), dopo aver indicato nome, regione ed eventuali politiche di etichettatura, occorre collegarlo a un Dataproc Metastore.
Si tratta di una voce che pesa parecchio sui costi complessivi di Dataplex processing: il Metastore viene infatti utilizzato da Dataplex per gestire l'elaborazione del workbench di esplorazione dei dati e incide anche sui costi Dataproc, attraverso il costo di esecuzione del Metastore stesso. Il Metastore è disponibile in tier diversi (Developer ed Enterprise per il v1, Enterprise ed Enterprise Plus per il v2), con risorse e prezzi differenti a seconda delle esigenze specifiche del proprio Dataproc Metastore, come dettagliato qui.
Una volta creato il Dataplex Lake, l'API Dataplex inizia a elaborare e a scansionare i dati secondo i processi di esplorazione descritti. È a questo punto che gli SKU di processing iniziano a comparire nei valori di Google Cloud Billing — ed è qui che i costi possono salire.
Va però sottolineato un punto chiave: mentre Dataplex con un Dataproc metastore esegue già di per sé alcuni processi onerosi, altri servizi sotto l'ombrello Dataplex come Data Lineage, Data Profiling, Data Catalog e Data Quality richiedono un'attivazione esplicita per generare costi. Questo articolo si concentrerà in particolare sulle API Lineage e Catalog, perché tipicamente sono quelle che comportano le maggiori implicazioni di costo per i nostri clienti.
L'API Data Lineage, come suggerisce il nome, scansiona tutti i processi dati definiti tramite Dataplex e traccia tutte le operazioni che hanno portato alla creazione degli asset, ad esempio job BigQuery, pipeline Dataflow, operazioni Pub/Sub o Dataproc che hanno modificato gli asset. A leggerla così può sembrare cosa da poco, ma queste operazioni possono generare un volume enorme di chiamate API, e questo si riflette direttamente sul pricing dell'API Data Lineage, come spiegato di seguito.
Anche l'API Data Catalog, come quella Data Lineage, è un'API separata che deve essere abilitata. Lavora a stretto contatto con Data Lineage per memorizzare i metadati relativi alle operazioni e si integra con la maggior parte dei servizi sotto l'ombrello Dataplex, generando chiamate API a partire dalle operazioni associate a Dataplex e in particolare all'API Data Lineage.
Lo screenshot seguente, tratto dalle pagine di pricing di Dataplex, dettaglia in particolare la suddivisione dei costi per Data Lineage e Data Catalog.
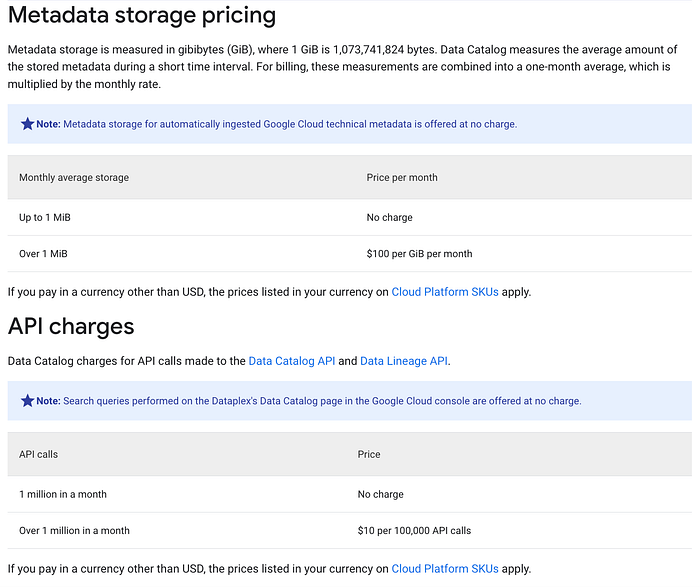
Come accennato, entrambe le API sono fatturate in base alle chiamate API e, a seconda della scalabilità dei vari servizi Data utilizzati in Google Cloud, si possono raggiungere facilmente milioni di chiamate, trasformandole in una voce di costo tutt'altro che trascurabile.
Inoltre, anche Data Catalog utilizza il Dataproc metastore per memorizzare i metadati: di conseguenza, in modo analogo a quanto avviene per Dataplex, i costi salgono in funzione della versione del Dataproc metastore in uso e, naturalmente, del volume di metadati archiviati.
Stimare l'impatto complessivo di Dataplex sui costi
Una delle domande che i clienti ci pongono più spesso su queste modifiche di Dataplex è: "Come possiamo stimare quanto ci costeranno tutti questi elementi di Dataplex?". La risposta breve, purtroppo, è che non esiste un modo semplice per farlo.
Confrontandoci direttamente con Google su questo punto, i nostri Engineers hanno verificato che non è possibile collegare un determinato processo a una specifica chiamata API Dataplex: di fatto, stimare questa componente di costo è quasi impossibile.
Anche per la componente Processing una stima è difficile, sebbene sia documentato che questi costi siano linearmente proporzionali al volume di dati associati ai propri Dataplex Lake.
Non è la risposta semplice e rassicurante che si vorrebbe, ma la buona notizia è che TUTTE queste componenti di costo possono essere mitigate con una buona gestione delle API e dei servizi Dataplex.
Come mitigare l'impatto di questi costi aggiuntivi: le opzioni a disposizione
Disabilitare completamente Dataplex e le API associate
Chi oggi non sfrutta le funzionalità avanzate di Dataplex e non ha piani imminenti per implementarne le specifiche funzioni di data governance può valutare di disabilitare del tutto Dataplex e le sue API.
Il modo più semplice è la Google Cloud Console: tramite la sua interfaccia è possibile abilitare e disabilitare qualsiasi API dalla pagina denominata, non a caso, "APIs and Services".
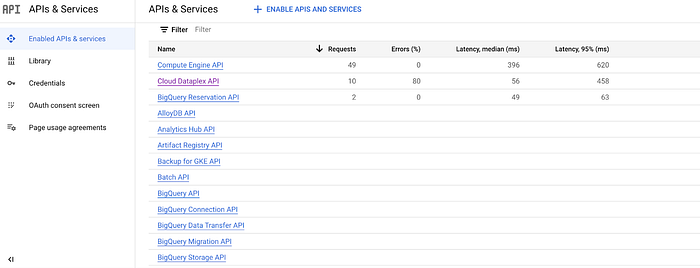
Aprendo questa pagina nella Google Cloud Console, dovreste vedere una schermata simile a quella sopra con l'elenco di tutte le API e i servizi abilitati. Da qui basta cercare l'API specifica da disabilitare (Cloud Dataplex, Data Catalog o Data Lineage) e cliccare su "Disable API", come nello screenshot, disattivando così l'API e tutti i costi e le operazioni che essa comporterebbe.
In alternativa, durante il webinar diversi clienti ci hanno chiesto se questa operazione possa essere eseguita in modo programmatico tramite script da riga di comando. La risposta è sì: lo script seguente può essere eseguito su un'API specifica all'interno dei propri progetti Google Cloud per disabilitarla in modo programmatico:
gcloud services disable API_SERVICE_NAME — project PROJECT_ID
Lo script non funziona automaticamente se l'API è stata utilizzata negli ultimi 30 giorni: in questi casi è necessario aggiungere l'opzione –force dopo l'API Service Name per disabilitare correttamente le API Dataplex.
Se invece la procedura va applicata su più progetti all'interno dell'Organization GCP, si può utilizzare uno script analogo, come nell'esempio seguente:
API_TO_DISABLE=API_SERVICE_NAME
for PROJECT_ID in $(gcloud projects list –filter=’parent.id=ORG_ID’ — format=’value(projectId)’)
do
echo "Processing $PROJECT_ID"
# Disable the API for the project
echo "Disabling $API_TO_DISABLE in $PROJECT_ID"
gcloud services disable $API_TO_DISABLE — project $PROJECT_ID
done
Da segnalare che, nella mail originale del 16 febbraio, Google ha messo a disposizione un Form che blocca automaticamente l'attivazione delle API previste dal 4 marzo 2024 nei propri progetti: se voi o qualcuno con i permessi necessari nella vostra organizzazione avete già compilato quel form, le API in questione dovrebbero risultare già disabilitate.
Vogliamo però sottolineare che è bene disabilitare API e servizi in Google Cloud solo dopo aver verificato che non siano utilizzati da alcun processo aziendale: per questo raccomandiamo di eseguire gli script sopra unicamente sulle API specifiche legate a Dataplex e solo dopo essersi assicurati di non utilizzare in proprio i processi tipo Dataplex Data Lineage o Data Catalog.
Attivare le funzionalità Dataplex in modo selettivo
Per chi vuole bilanciare data governance avanzata ed efficienza dei costi continuando a usare Dataplex, attivare in modo selettivo solo alcune funzionalità è una strategia prudente.
Valutando con attenzione le funzionalità e le API Dataplex realmente necessarie ai propri progetti, si possono abilitare solo quelle in linea con i propri requisiti. Invitiamo gli utenti Google Cloud a riflettere bene sull'uso che intendono fare di Dataplex e, se decidono di adottarlo, a procedere con cautela nella scelta delle funzionalità e delle API da abilitare.
Consigliamo inoltre, agli utenti Google Cloud che desiderano utilizzare il servizio Dataplex, di creare un unico progetto GCP "admin" che ospiti tutte le funzionalità Dataplex, così da minimizzare costi e complessità a seguito di questa modifica. In questo modo si limita l'impatto delle chiamate API, dei costi di Processing e di Metadata Storage che potrebbero altrimenti derivare dall'attivazione di Dataplex e delle sue funzionalità su più progetti all'interno della Google Cloud Organization.
Garantire monitoraggio e ottimizzazione costanti
Monitorare costantemente i costi legati a Dataplex è fondamentale. Google Cloud mette a disposizione strumenti dettagliati di fatturazione e cost management per tenere sotto controllo le spese: tra questi, Google Cloud Billing, Cloud Monitoring e Cloud Logging, che permettono di tracciare la spesa diretta per SKU, l'utilizzo tramite dashboard di facile lettura e le singole voci di logging relative al servizio Dataplex e alle API menzionate.
Esaminare con regolarità report e output di questi servizi consente di individuare picchi di costo inattesi e di intervenire tempestivamente per ottimizzare l'utilizzo.
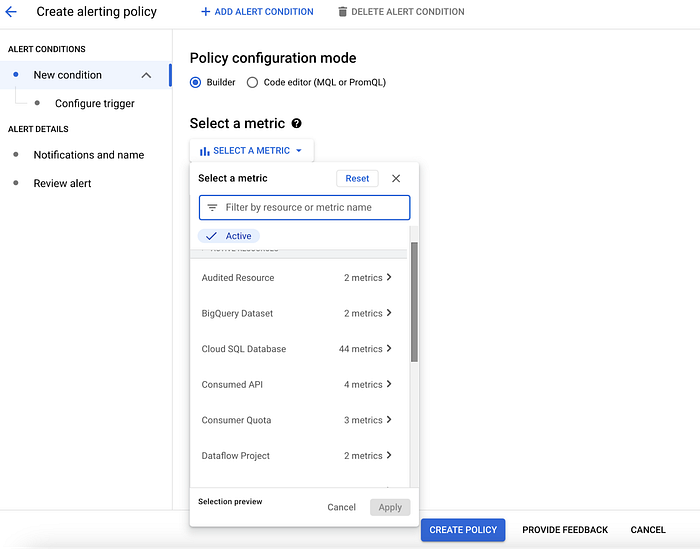
Si possono inoltre impostare degli Alert tramite Cloud Monitoring Policy, come mostrato nello screenshot, per monitorare in modo proattivo eventuali superamenti delle metriche di utilizzo che si vogliono tenere sotto controllo, come quelle relative al servizio Dataplex e alle risorse a esso collegate.
Conclusione
L'imminente attivazione di default dell'API Dataplex nei progetti Google BigQuery porta con sé sia opportunità sia sfide per i clienti Google Cloud.
Comprendendone le implicazioni e adottando strategie proattive di gestione dei costi, si potrà continuare a sfruttare la potenza di BigQuery e le funzionalità in continua evoluzione di Dataplex, mantenendo al tempo stesso operazioni efficienti dal punto di vista economico.
I consigli forniti in questo articolo, insieme agli spunti degli esperti di settore di DoiT, possono aiutare gli utenti di Google BigQuery ad affrontare con successo questo cambiamento e a ottimizzare utilizzo e spesa Google Cloud.
Per chiudere l'articolo, vorrei aggiungere alcune considerazioni finali su DoiT International. Affiancare i nostri clienti nelle analisi e nella pianificazione a lungo termine in seguito a cambiamenti di forte impatto come questo è una delle attività centrali della nostra azienda.
Se ancora non siete clienti DoiT, vi invitiamo a darci un'occhiata sulle nostre pagine qui: in DoiT abbiamo un team altamente qualificato ed esperto, aiutiamo costantemente i nostri clienti a sfruttare al meglio le risorse Google Cloud (oltre che AWS e Azure) e produciamo regolarmente blog e webinar come questo per accompagnarli nei cambiamenti man mano che si presentano.
Grazie per aver letto questo articolo: ci auguriamo che, insieme agli altri nostri contenuti e all'esperienza del nostro team, possa aiutarvi ad affrontare al meglio questa modifica alle funzionalità di BigQuery e Dataplex nel prossimo futuro.
FAQ aggiuntive
Oltre all'articolo LinkedIn del nostro Sayle Matthews qui, che fa luce sulle implicazioni più ampie della modifica a BigQuery dal 4 marzo in poi, io e Sayle abbiamo tenuto un Webinar dedicato giovedì 29 febbraio 2024 (link qui), durante il quale abbiamo ricevuto numerose domande aggiuntive. Riportiamo di seguito una selezione delle nostre risposte (potete ascoltarle tutte direttamente nel link al Webinar):
D1: Qual è il modo migliore (e meno doloroso) per "scansionare" queste API abilitate su oltre 100 progetti GCP?
Risposta: Si veda lo script fornito nel corpo dell'articolo. Vogliamo ribadire però che disabilitare le API tutte in una volta può essere rischioso: meglio procedere in modo selettivo, agendo solo sulle API che si è certi di non utilizzare, in funzione delle esigenze della propria organizzazione.
D2: Sapete a che ora del 4 marzo dovremo disabilitare queste API?
Risposta: Google non specifica un orario preciso in cui le modifiche entreranno in vigore: invitiamo quindi gli utenti Google Cloud a disabilitare le API non necessarie il prima possibile, a partire dal 4 marzo, per ridurre eventuali impatti imprevisti sulle bollette Google Cloud. Molti clienti non saranno toccati dal cambiamento, ma vogliamo evitare che qualcuno si trovi spiacevoli sorprese in fattura.
D3: Se non utilizzo nessuno dei servizi che Google sta abilitando automaticamente, disabilitare le API dopo il 4 manterrebbe i costi invariati? (considerando che usiamo principalmente BigQuery)
Risposta: Esatto: dopo la modifica dell'altro giorno, fortunatamente, tutto funziona in modalità "opt-in". Suggeriamo comunque di assicurarsi di aver disattivato le API Data Lineage, Data Catalog e Data Discovery, così da evitare che uno di questi processi inizi a generare costi automaticamente.
D4: Possiamo usare la console DoiT Support per visualizzare e tracciare questi costi Dataplex?
Risposta: Sì: applicando un filtro sul servizio "Dataplex" verranno elencati tutti. Quando i nostri Engineers fanno troubleshooting di solito filtriamo per Service su Dataplex e poi raggruppiamo per SKU e progetto. In questo modo nella DoiT Console si vedono i costi per progetto e per SKU.