Introduction
L'annonce récente de Google Cloud concernant l'activation par défaut de l'API Dataplex pour tous les clients BigQuery à partir du 4 mars 2024 ouvre des perspectives intéressantes en matière d'analytique avancée.
MAIS ce changement entraîne aussi des conséquences potentiellement lourdes sur les coûts ! Notamment compte tenu de la nature même de l'API Dataplex et des API complémentaires telles que Data Lineage et Data Catalog.
Dans cet article, nous reviendrons en détail sur ce changement, son impact sur les coûts et les stratégies pour en atténuer les effets, tels que présentés à l'origine par moi-même et mon collègue Google Data Practice Lead chez DoiT, Sayle Matthews, lors de notre webinaire du 29 février et via ce post LinkedIn.
Comprendre ce changement
Dans un e-mail de l'équipe Google Cloud envoyé à tous les utilisateurs de Google BigQuery à la mi-février, intitulé "[Action Advised] Review the updates to BigQuery to confirm if you need to take action on your projects", on apprenait qu'à compter du 4 mars 2024, l'API Dataplex serait automatiquement activée pour tous les projets BigQuery actifs et activée par défaut pour les nouveaux projets Google Cloud.
Cette évolution s'inscrit dans le cadre plus large du lancement de BigQuery Studio (lien), dont l'objectif est d'offrir aux utilisateurs des capacités analytiques supplémentaires de manière fluide.
Voici les éléments clés de cet e-mail, qui mentionne également d'autres API qui seront automatiquement activées à la suite des changements à venir le 4 mars :
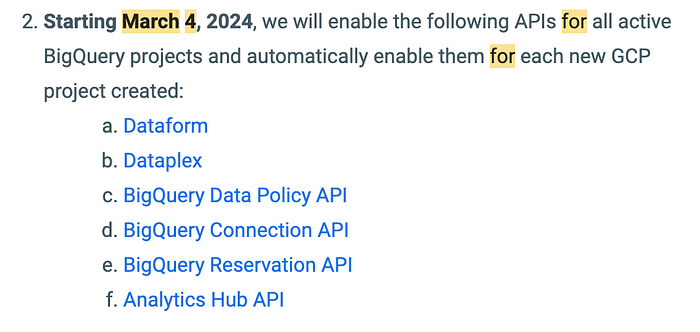
L'activation du service Dataplex en général, ainsi que des API associées telles que Data Catalog et Data Lineage, constitue le principal motif d'inquiétude parmi les éléments listés ci-dessus.
Pour les besoins de cet article, il convient de noter que, comme l'indique le post LinkedIn de Sayle Matthews, une nouvelle version majeure de Dataplex a été déployée par Google la semaine du 26 février, qui a corrigé plusieurs de ces problèmes liés à l'activation automatique de fonctionnalités payantes. Heureusement, ce changement concerne donc désormais moins d'utilisateurs potentiels.
Conséquences de Dataplex sur les coûts GCP
Si Dataplex apporte la promesse de fonctionnalités avancées de gouvernance et de gestion des données aux clients GCP, il est essentiel d'avoir conscience des conséquences potentielles sur les coûts liées à son activation automatique à partir du 4 mars.
Dataplex introduit des fonctionnalités et des processus cachés liés à divers services et API de données Google Cloud, comme Google BigQuery, Cloud Dataflow ou encore Cloud Pub/Sub, susceptibles d'entraîner une hausse des coûts si vous ne gérez pas efficacement ce changement au sein de vos projets GCP !
Comme indiqué sur la page tarifaire principale de Dataplex, le service facture via 4 SKU principaux, facturés différemment, à savoir :
- Le traitement Dataplex (standard et premium)
- Le stockage shuffle Dataplex
- Les appels de l'API Data Catalog
- Le stockage de métadonnées Data Catalog
Le plus significatif de ces SKU sur vos coûts Dataplex est le SKU de traitement (Processing), qui à l'heure où nous écrivons est facturé en DCU-heures (0,060 $ par DCU-heure pour le traitement Dataplex Standard et 0,089 $ pour le traitement Dataplex Premium, ces tarifs pouvant varier selon la région).
Le tableau ci-dessous, issu de la page tarifaire de Dataplex, détaille la manière dont le traitement Dataplex est facturé en pratique :
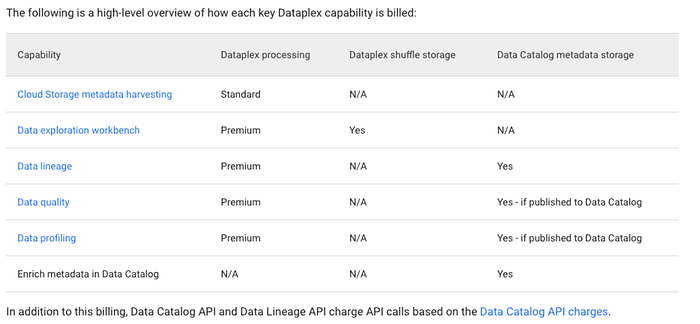
Comme illustré ci-dessus, le SKU de traitement Dataplex peut exécuter de nombreuses fonctions sur vos sources de données GCP s'il est laissé libre cours (et ce avant même d'aborder les API associées Data Lineage et Data Catalog !). Mais comment le SKU de traitement Dataplex fonctionne-t-il concrètement ?
La réponse réside dans la création de Dataplex Lakes et Zones. Dans Dataplex, un Lake correspond en pratique à un domaine de data mesh destiné à contenir les artefacts de données d'une unité métier, comme illustré ci-dessous. Les Lakes peuvent à leur tour contenir des Zones, des Assets et des Entities pour gérer vos données selon vos propres structures métier et de données dans Google BigQuery, GCS, etc.

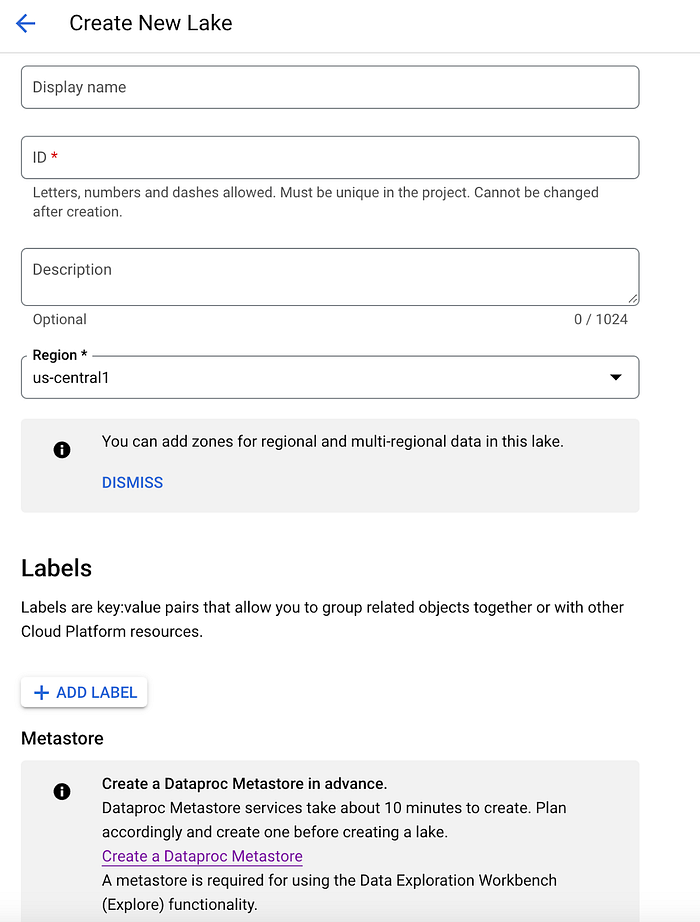
Lorsque vous créez un Dataplex Lake (lien), après avoir spécifié son nom, sa région et toute politique de labellisation à lui appliquer, vous devez également relier le Lake à un Dataproc Metastore.
C'est un facteur majeur du coût global du traitement Dataplex, car le Metastore est utilisé par Dataplex pour gérer le traitement du workbench d'exploration de données et impacte aussi vos coûts Dataproc via le coût d'exécution du Metastore. Celui-ci est également disponible en différents niveaux (Developer et Enterprise pour Metastore v1, Enterprise et Enterprise Plus pour la v2), avec des ressources et des tarifs différents selon les besoins spécifiques de votre Dataproc Metastore, comme détaillé ici.
Une fois votre Dataplex Lake créé, l'API Dataplex commencera à traiter et à scanner vos données selon les processus d'exploration mentionnés précédemment. À ce stade, les SKU de traitement vont apparaître dans votre facturation Google Cloud, et c'est là que les coûts peuvent grimper !
Un point clé toutefois : si Dataplex en lui-même, avec un Dataproc Metastore, exécute déjà certains processus coûteux, les autres services proposés sous l'ombrelle Dataplex tels que Data Lineage, Data Profiling, Data Catalog et Data Quality doivent être activés pour engendrer des coûts. Cet article couvrira en particulier les API Lineage et Catalog, car ce sont elles qui ont généralement les plus fortes conséquences financières pour nos clients.
Concernant l'API Data Lineage, comme son nom l'indique, elle sert à scanner tous les processus de données définis via Dataplex et trace toutes les opérations ayant conduit à la création de vos assets : par exemple des jobs BigQuery, des pipelines Dataflow ou encore des opérations Pub/Sub ou Dataproc ayant entraîné une modification de vos assets. Si cela peut sembler anodin de prime abord, les exemples mentionnés peuvent générer un volume considérable d'appels d'API pour chaque opération, ce qui se répercute directement sur la tarification de l'API Data Lineage, comme expliqué ci-dessous.
L'API Data Catalog, à l'instar de l'API Data Lineage, est une autre API distincte qui doit être activée. Elle fonctionne directement avec Data Lineage pour stocker les métadonnées liées à vos opérations et fonctionne également avec la plupart des services de l'ombrelle Dataplex pour générer des appels d'API à partir de vos opérations associées à Dataplex et plus particulièrement à l'API Data Lineage.
La capture d'écran ci-dessous, issue des pages tarifaires Dataplex de Google, détaille la répartition de vos coûts Data Lineage et Data Catalog en particulier.
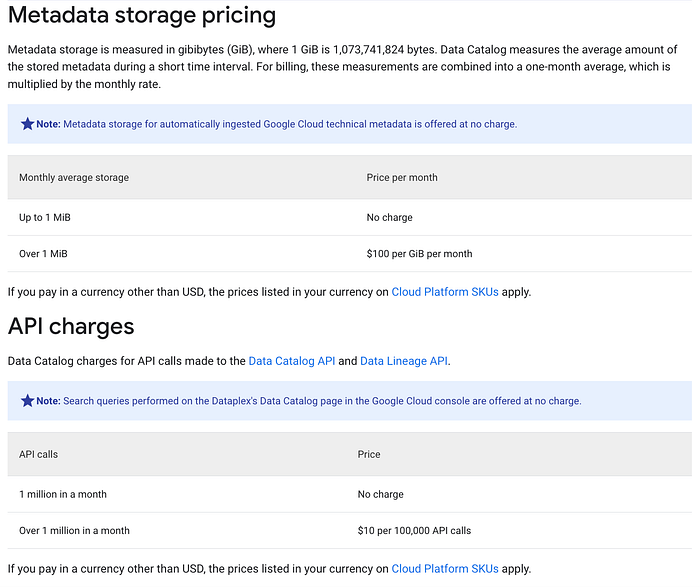
Comme indiqué, ces deux API sont facturées sur la base des appels d'API et, en fonction de la scalabilité de vos différents services de données utilisés dans Google Cloud, ceux-ci peuvent facilement grimper à plusieurs millions d'appels, ce qui en fait un poste significatif lorsque les deux API sont activées.
De plus, Data Catalog utilise également le Dataproc Metastore pour stocker les métadonnées, ce qui, comme pour Dataplex, coûtera plus cher selon la version du Dataproc Metastore que vous utilisez, ainsi que le volume de métadonnées stockées bien entendu.
Estimer l'impact global de Dataplex sur les coûts
L'une des principales questions que nos clients nous posent au sujet de ces changements Dataplex est : comment estimer ce que tous ces éléments Dataplex vont nous coûter ? Malheureusement, la réponse rapide est qu'il n'existe aucun moyen simple d'effectuer cette estimation.
En échangeant directement avec Google sur ce sujet, nos Engineers ont constaté qu'il n'est pas possible de relier un processus donné à un appel d'API Dataplex spécifique, ce qui rend l'estimation de cet aspect de vos coûts pratiquement impossible.
Pour ce qui est du coût de traitement, il est également difficile à estimer, même s'il est documenté que ces coûts sont linéairement proportionnels au volume de données associées à vos Dataplex Lakes.
Ce n'est sans doute pas la réponse simple et rassurante que l'on aurait souhaitée, mais nous pouvons assurément atténuer TOUS ces postes de coûts grâce à une bonne gestion de vos API et services Dataplex !
Atténuer l'impact de ces coûts supplémentaires : vos options
Désactiver Dataplex et ses API associées dans leur ensemble
Les utilisateurs qui n'exploitent pas actuellement les fonctionnalités avancées de Dataplex ou n'ont pas de projet immédiat pour mettre en œuvre ses fonctionnalités spécifiques de gouvernance des données peuvent envisager de désactiver Dataplex et ses API dans leur ensemble.
Un moyen simple d'y parvenir consiste à passer par la Google Cloud Console : grâce à son interface intuitive, vous pouvez activer ou désactiver n'importe laquelle de vos API via la page APIs and Services, bien nommée.
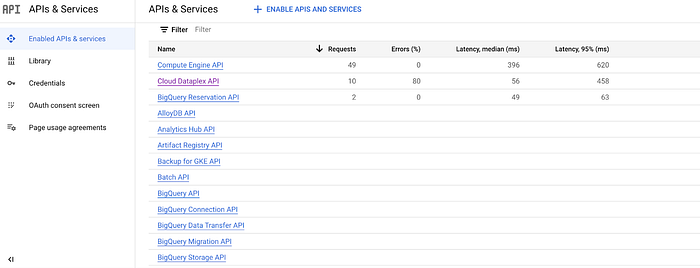
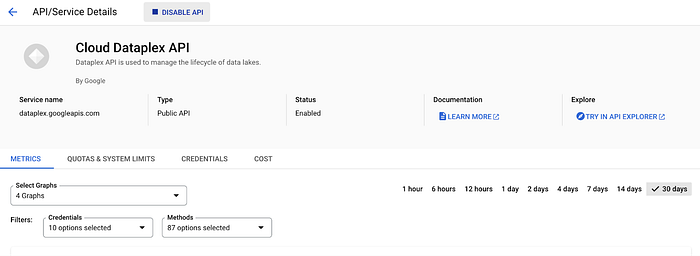
Lorsque vous accédez à cette page dans la Google Cloud Console, vous devriez voir une page semblable à celle ci-dessus, qui affiche toutes vos API et services activés. À partir de là, vous pouvez simplement rechercher l'API spécifique que vous souhaitez désactiver, à savoir les API Cloud Dataplex, Data Catalog ou Data Lineage, puis cliquer sur Disable API comme illustré dans la capture d'écran ci-dessous, désactivant ainsi l'API et tous les coûts ou opérations qu'elle aurait pu déclencher.
Plusieurs de nos clients lors du webinaire associé nous ont demandé si ce processus pouvait être réalisé de manière programmatique via des scripts en ligne de commande. La réponse est oui : l'extrait de script ci-dessous peut être exécuté sur une API spécifique au sein de vos projets Google Cloud pour la désactiver de manière programmatique :
gcloud services disable API_SERVICE_NAME — project PROJECT_ID
Le script ci-dessus ne fonctionnera pas automatiquement si l'API a été utilisée au cours des 30 derniers jours. Il vous faudra donc ajouter l'option –force après le nom du service API pour désactiver les API Dataplex avec succès.
Un script similaire peut également être exécuté à l'échelle de votre organisation GCP, si vous devez exécuter ce processus sur plusieurs projets de votre organisation GCP. En voici un exemple :
API_TO_DISABLE=API_SERVICE_NAME
for PROJECT_ID in $(gcloud projects list –filter=’parent.id=ORG_ID’ — format=’value(projectId)’)
do
echo "Processing $PROJECT_ID"
# Disable the API for the project
echo "Disabling $API_TO_DISABLE in $PROJECT_ID"
gcloud services disable $API_TO_DISABLE — project $PROJECT_ID
done
Bon à savoir : dans son e-mail initial du 16 février, Google fournissait également un lien vers un formulaire qui empêche automatiquement l'activation des API prévues pour le 4 mars 2024 dans vos projets. Si vous-même ou toute personne disposant des accès appropriés dans votre organisation avez déjà suivi ce lien, alors toutes les API concernées devraient déjà être désactivées dans votre cas.
Pour les besoins de cet article, nous tenons toutefois à insister sur le fait que vous ne devez désactiver des API et des services dans Google Cloud que si vous êtes certain qu'ils ne sont utilisés par aucun de vos processus métier. C'est pourquoi nous recommandons de n'exécuter les scripts ci-dessus que sur les API spécifiquement liées à Dataplex, et uniquement si vous êtes certain de ne pas utiliser vous-mêmes les processus de type Data Lineage ou Data Catalog de Dataplex.
Activer les fonctionnalités Dataplex de manière sélective
Pour les utilisateurs qui souhaitent maintenir l'équilibre entre une gouvernance des données renforcée et la maîtrise des coûts via Dataplex, l'activation sélective de fonctionnalités spécifiques de Dataplex peut s'avérer une stratégie judicieuse.
En évaluant soigneusement les fonctionnalités et API Dataplex nécessaires à leurs projets, les utilisateurs peuvent n'activer que celles qui correspondent à leurs besoins. Nous invitons les utilisateurs Google Cloud à réfléchir attentivement à l'usage qu'ils souhaitent faire de Dataplex et, s'ils décident de l'utiliser, à avancer prudemment quant aux fonctionnalités et API activées.
Nous conseillons également aux utilisateurs Google Cloud souhaitant utiliser le service Dataplex de créer un unique projet GCP admin dans lequel toute la fonctionnalité Dataplex sera hébergée et exécutée, afin de minimiser les coûts et la complexité pour votre entreprise à la suite de ce changement. Cela permet de limiter l'impact des divers appels d'API, des frais de traitement et de stockage de métadonnées qui pourraient survenir à la suite de l'activation de Dataplex et de ses fonctionnalités sur plusieurs projets de votre organisation Google Cloud.
Mettre en place une surveillance et une optimisation continues
Une surveillance continue de vos coûts liés à Dataplex est essentielle. Google Cloud propose des outils détaillés de facturation et de gestion des coûts qui aident les utilisateurs à suivre leurs dépenses. Parmi ces services figurent Google Cloud Billing, Cloud Monitoring et Cloud Logging, qui vous permettent de suivre vos dépenses directes par SKU, votre utilisation via des dashboards faciles à lire, et les entrées de log individuelles relatives au service Dataplex et aux API mentionnées.
L'examen régulier de ces rapports et sorties de service permet aux utilisateurs Google Cloud d'identifier toute hausse inattendue des coûts et de prendre rapidement les mesures nécessaires pour optimiser leur utilisation.
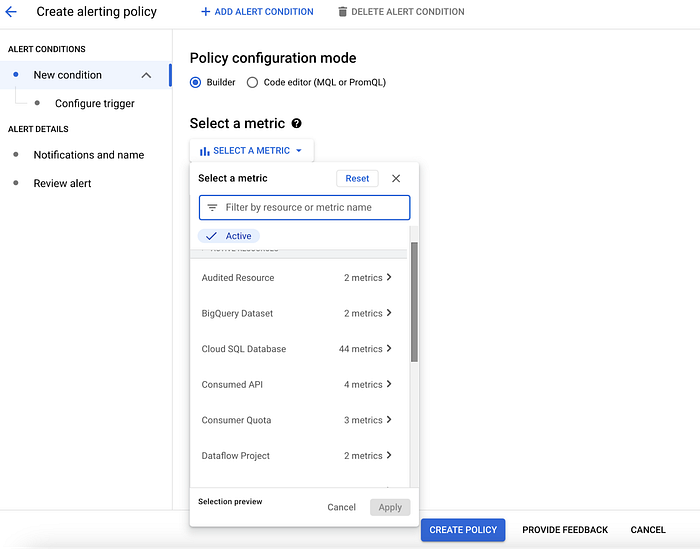
Les utilisateurs peuvent également configurer des alertes via les Cloud Monitoring Policies, comme illustré, pour suivre proactivement les dépassements sur les indicateurs d'utilisation spécifiques qu'ils souhaitent surveiller, comme le service Dataplex et ses ressources connectées.
Conclusion
L'activation par défaut imminente de l'API Dataplex dans les projets Google BigQuery présente à la fois des opportunités et des défis pour les clients Google Cloud.
En comprenant les implications et en mettant en œuvre des stratégies proactives de gestion des coûts, les utilisateurs peuvent continuer à tirer parti de la puissance de BigQuery et des capacités évolutives de Dataplex tout en assurant une exploitation maîtrisée sur le plan financier.
Les recommandations partagées dans cet article, ainsi que les éclairages des experts sectoriels de DoiT, peuvent aider les utilisateurs de Google BigQuery à aborder ce changement avec sérénité et à optimiser leur utilisation et leurs dépenses Google Cloud à la suite de cette évolution à venir.
Pour clore cet article, j'aimerais ajouter quelques mots sur nous, chez DoiT International. Accompagner nos clients dans l'analyse et la planification à long terme à la suite de changements à fort impact tels que celui-ci fait partie de nos activités majeures.
Si vous n'êtes pas encore client DoiT, nous vous invitons en tant que lecteur de cet article à nous découvrir sur nos pages ici. Nous disposons chez DoiT d'une équipe extrêmement compétente et expérimentée. Nous aidons toujours nos clients à tirer le meilleur parti de leurs ressources Google Cloud (ainsi qu'AWS et Azure) et nous publions régulièrement des blogs et webinaires comme celui-ci pour les guider au mieux à travers ces changements à mesure qu'ils surviennent.
Merci d'avoir lu cet article. Nous espérons que celui-ci, ainsi que nos autres contenus et notre équipe expérimentée, vous aideront à aborder sereinement ce changement concernant les fonctionnalités BigQuery et Dataplex dans un avenir proche !
FAQ supplémentaires
En complément de l'article LinkedIn de Sayle Matthews, de DoiT, disponible ici, qui éclaire les implications plus larges de ce changement de BigQuery à partir du 4 mars, Sayle et moi-même avons également animé un webinaire sur ce même sujet le jeudi 29 février 2024 (lien ici), au cours duquel un certain nombre de questions supplémentaires nous ont été posées. Nos réponses à une sélection de ces questions sont reproduites ci-dessous à titre de référence pour nos lecteurs (et vous pouvez écouter nos réponses à toutes ces questions sur le lien du webinaire) :
Q1 : Quelle serait la meilleure manière (la moins fastidieuse) de scanner ces API activées sur plus de 100 projets GCP ?
Réponse : Voir le script fourni dans le contenu principal de l'article ci-dessus. Nous tenons toutefois à insister sur le fait que désactiver toutes les API d'un coup peut être risqué. Nous vous invitons à désactiver de manière sélective les API spécifiques dont vous êtes certain qu'elles ne sont pas nécessaires, en fonction des besoins de votre organisation.
Q2 : Connaissez-vous l'heure du 4 mars à laquelle nous devons désactiver ces API ?
Réponse : Bien que Google ne précise pas d'heure à laquelle ces changements prendront effet, nous invitons les utilisateurs Google Cloud à procéder à la désactivation des API dont ils n'ont pas besoin dès que possible le 4 mars ou peu après, afin de réduire tout impact imprévu sur leur facturation Google Cloud. Si de nombreux clients ne seront pas affectés par ce changement, nous ne souhaitons pas que nos clients aient de mauvaises surprises côté facturation à la suite de ce changement.
Q3 : Si je n'utilise aucun des services que Google active automatiquement ici, désactiver les API après le 4 maintiendrait-il les coûts à leur niveau actuel ? (sachant que nous utilisons principalement BigQuery)
Réponse : C'est exact : depuis le changement de l'autre jour, tout fonctionne heureusement selon un modèle opt-in. Nous suggérons toutefois de vous assurer d'avoir bien désactivé les API Data Lineage, Data Catalog et Data Discovery au préalable pour garantir qu'aucun de ces processus ne se mette à facturer automatiquement.
Q4 : Pouvons-nous utiliser la console DoiT Support pour visualiser ou suivre ces coûts Dataplex ?
Réponse : Oui, si vous appliquez un filtre sur le service Dataplex, ils seront tous listés. Lorsque nos Engineers font du troubleshooting, nous filtrons généralement par service sur Dataplex puis nous groupons par SKU et par projet. Cela affiche les coûts par projet et par SKU dans la console DoiT.