AWS Database Migration Service (DMS) ist ein weit verbreitetes Tool für Datenbankmigration und -replikation und unterstützt sowohl homogene als auch heterogene Datenbankumgebungen. Wer mit AWS DMS Daten aus Quellen wie Amazon RDS MySQL oder Amazon RDS PostgreSQL migriert, kann mit Quellfiltern gezielt steuern, wie viele und welche Datensätze in die Zieldatenbank übertragen werden. Dabei lohnt es sich allerdings, die Grenzen dieser Filter zu kennen, damit die Migration reibungslos verläuft.
AWS DMS im Überblick
AWS DMS migriert Daten, indem es Änderungen kontinuierlich von der Quell- in die Zieldatenbank repliziert – mit minimaler Ausfallzeit. Zu den wichtigsten Funktionen gehören:
- Full Load, CDC und laufende Replikation: für die Erstmigration und die fortlaufende Synchronisation.
- Schema- und Tabellen-Mapping: flexibles Einbinden und Transformieren von Objekten.
- Filterfunktionen: Filterung auf Zeilen- und Spaltenebene, um zu steuern, welche Daten repliziert werden.
- Unterstützung mehrerer Datenbank-Engines: u. a. MySQL, PostgreSQL, SQL Server und Oracle.
Trotz dieses Funktionsumfangs verhält sich die Spaltenfilterung in AWS DMS nicht immer wie erwartet – vor allem bei Updates während CDC.
Was ist Spaltenfilterung in AWS DMS?
Mit der Spaltenfilterung in AWS DMS schließen Sie Zeilen anhand von Bedingungen auf bestimmten Spalten in die Replikation ein oder davon aus. Sie können einen DMS-Task etwa so konfigurieren, dass nur Zeilen repliziert werden, in denen eine Spalte wie "status" den Wert "active" hat oder eine Spalte "timestamp" größer als ein bestimmtes Datum ist. Praktisch ist das vor allem dann, wenn Sie nur eine Teilmenge Ihrer Daten migrieren oder bei der Migration Geschäftslogik anwenden möchten.
Hier ein Beispiel für eine DMS-Spaltenfilterregel:
{
"rules": [\
{\
"rule-type": "selection",\
"rule-id": "1",\
"rule-name": "FilterActiveUsers",\
"object-locator": {\
"schema-name": "public",\
"table-name": "users"\
},\
"rule-action": "include",\
"filters": [\
{\
"filter-type": "source",\
"column-name": "status",\
"filter-conditions": [\
{\
"filter-operator": "eq",\
"value": "active"\
}\
]\
}\
]\
}\
]
Anwendungsfall: Spaltenfilterung bei der Datenmigration
Um zu prüfen, wie DMS mit Spaltenfilterung umgeht, haben wir einen Proof of Concept (POC) durchgeführt: die Migration von Daten aus einer RDS-MySQL-8.0-Instanz in eine andere RDS-MySQL-8.0-Instanz mit AWS Database Migration Service (DMS). Die Anforderung war einfach: Zeilen aus der Quelltabelle sollten nur dann in die Zieltabelle repliziert werden, wenn eine bestimmte Spalte namens "name" eine bestimmte Bedingung erfüllt – konkret: name = "b". Dafür haben wir die Quellspaltenfilterung von DMS genutzt, mit der sich Zeilen anhand bestimmter Werte ein- oder ausschließen lassen.
Setup
- Quelle: RDS MySQL 8.0.36
- Ziel: RDS MySQL 8.0.36
- DMS-Version: Engine 3.5.4
- Migrationsmodus: Full Load mit CDC
In der Quelldatenbank wurde eine Beispieltabelle angelegt:
CREATE TABLE `Sample` (
`id` varchar(255) NOT NULL,
`name` varchar(255) NOT NULL,
PRIMARY KEY (`id`)
);
Der DMS-Migrationstask wurde mit einem Filter auf Spaltenebene konfiguriert, sodass ausschließlich Zeilen mit name = "b" repliziert werden.
DMS-Mapping-Regel:
{
"rules": [\
{\
"rule-type": "selection",\
"rule-id": "098947021",\
"rule-name": "098947021",\
"object-locator": {\
"schema-name": "Test",\
"table-name": "Sample"\
},\
"rule-action": "include",\
"filters": [\
{\
"filter-type": "source",\
"column-name": "name",\
"filter-conditions": [\
{\
"filter-operator": "eq",\
"value": "b"\
}\
]\
}\
]\
}\
]
}
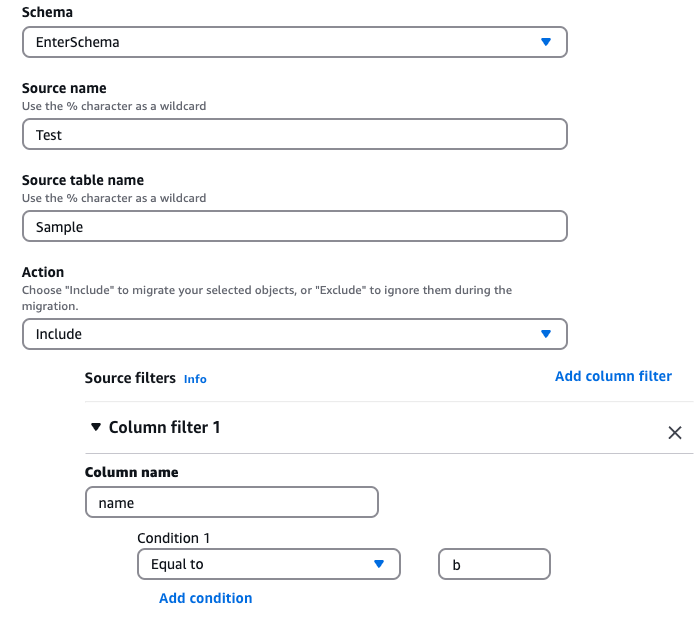
Selection Rule mit Quellfilter
Beobachtungen und Ergebnisse:

Eine eingefügte Zeile mit name = "b" wurde korrekt repliziert. Ein Insert mit name = "a" wurde ebenso korrekt ignoriert. Bei Updates zeigen sich jedoch Inkonsistenzen:
- Ein Update von name="a" auf name="b" wurde ignoriert, obwohl CDC das Ereignis erfasst hatte.

Ist die DMS-Validierung aktiv, führt dieses Verhalten zu Abweichungen zwischen Quell- und Zieldatenbank, da die Validierung die Diskrepanzen meldet.
Das zeigt deutlich: AWS DMS wendet Filter auf den Zustand vor dem Update an – und das kann bei Spaltenfiltern zu Problemen mit der Datenintegrität führen.

Ursache – wie AWS DMS Filter anwendet
AWS DMS wertet Spaltenfilter auf Basis des Zeilenzustands vor dem Update aus. Konkret heißt das:
- Insert-Events: Der Filter greift auf die Werte der eingefügten Zeile.
- Update-Events: Der Filter wird ausgewertet, bevor das Update angewendet wird.
- Delete-Events: Der Filter prüft den Zustand der Zeile vor dem Löschen.
Da Updates anhand des ursprünglichen Zeilenzustands gefiltert werden, wird ein Update von name = "a" auf name = "b" ignoriert. Die Zeile erfüllte die Filterbedingung vor dem Update nicht – und wird daher nie repliziert.
Das kann zu Dateninkonsistenzen führen. Verlässt sich eine Anwendung darauf, dass Zeilen nach einem Update gefiltert werden, gelangen die erwarteten Daten unter Umständen nie in die Replikation.
Workaround: Filterung in der Zieldatenbank
Da AWS DMS keine Möglichkeit bietet, Filter erst nach Verarbeitung eines Updates anzuwenden, braucht es einen Workaround:
Schritt 1: Spaltenfilter aus dem DMS-Task entfernen
Passen Sie den DMS-Task so an, dass alle Daten ohne Filterung repliziert werden.
Schritt 2: Filterung in der Zieldatenbank umsetzen
Anstatt direkt in die Tabelle Sample der Zieldatenbank zu replizieren, replizieren Sie zunächst in eine Staging-Tabelle und verschieben gültige Zeilen anschließend per Trigger oder Stored Procedure in die Tabelle Sample.
Legen Sie dazu in der Ziel-RDS-MySQL-Datenbank eine Staging-Tabelle (sample_staging) an. Sie hält die replizierten Daten zwischen, bis sie in die Tabelle Sample übernommen werden.
Beispiel in MySQL:
CREATE TABLE sample_staging (
id INT PRIMARY KEY,
name VARCHAR(255)
);
Schritt 3: Stored Procedure anlegen
Legen Sie eine Stored Procedure an, die gültige Zeilen (z. B. Zeilen mit name = "b") aus der Staging-Tabelle (sample_staging) in die Zieltabelle (Sample) verschiebt. Diese Prozedur verarbeitet sowohl Inserts als auch Updates.
CREATE PROCEDURE MoveValidRowsToSample()
BEGIN
-- Insert or update valid rows in the Sample table
INSERT INTO Sample (id, name)
SELECT id, name
FROM sample_staging
WHERE name = 'b'
ON DUPLICATE KEY UPDATE
name = VALUES(name);
--Delete valid rows from the staging table
DELETE FROM sample_staging
WHERE name = 'b';
END
Schritt 4: Trigger anlegen
Legen Sie auf der Staging-Tabelle (sample_staging) einen Trigger an, der die Stored Procedure automatisch aufruft, sobald eine Zeile eingefügt oder aktualisiert wird.
CREATE TRIGGER after_insert_sample_staging
AFTER INSERT ON sample_staging
FOR EACH ROW
BEGIN
CALL MoveValidRowsToSample();
END
CREATE TRIGGER after_update_sample_staging
AFTER UPDATE ON sample_staging
FOR EACH ROW
BEGIN
CALL MoveValidRowsToSample();
END
So funktioniert das Ganze
- Quelldatenbank: enthält die Originaldaten.
- AWS DMS: repliziert die Daten von der Quelle in die Tabelle sample_staging der Ziel-RDS-MySQL-Datenbank.
- Staging-Tabelle (sample_staging): hält alle replizierten Daten zwischen.
- Trigger: ruft automatisch eine Stored Procedure auf, sobald Daten in sample_staging eingefügt oder aktualisiert werden.
- Stored Procedure: verschiebt gültige Zeilen (mit name = "b") aus sample_staging in die Tabelle Sample.
- Zieltabelle (Sample): enthält ausschließlich die gültigen Zeilen, nachdem Trigger und Stored Procedure die Daten verarbeitet haben.
Für PostgreSQL lässt sich die Logik analog mit BEFORE-INSERT-OR-UPDATE-Triggern abbilden.
Test mit RDS PostgreSQL
Um auszuschließen, dass dieses Verhalten MySQL-spezifisch ist, haben wir denselben Test mit RDS PostgreSQL durchgeführt. Das Ergebnis war identisch:
- Updates, durch die eine Zeile die Filterbedingung erfüllte, wurden nicht in die Zieltabelle repliziert.
- Es handelt sich also nicht um ein datenbankspezifisches Problem, sondern um eine grundsätzliche Einschränkung von DMS bei der Verarbeitung von Spaltenfiltern während CDC.
Weitere Einschränkungen von DMS-Quellfiltern
- Spalten mit Right-to-Left-Sprachen (RTL): Bei DMS-Quellfiltern liegt die Annahme nahe, dass das Tool jede Art von Daten verarbeitet – unabhängig von Sprache oder Schrift. Das stimmt jedoch nicht. DMS-Quellfilter verarbeiten keine Spalten mit RTL-Sprachen wie Hebräisch. Beziehen Ihre Filterbedingungen solche Spalten ein, greifen die Filter unter Umständen nicht wie erwartet – die Folge ist eine unvollständige oder fehlerhafte Replikation.
Beispiel: Enthält eine Spalte hebräischen Text (etwa customer_name auf Hebräisch) und Sie verwenden eine Filterbedingung wie customer_name = "דוד", kann DMS diese unter Umständen nicht korrekt auswerten.
- Large-Object-Spalten (LOB): Auf LOB-Spalten – etwa BLOBs, CLOBs oder TEXT in MySQL bzw. BYTEA oder TEXT in PostgreSQL – lassen sich keine Filter anwenden. Filterversuche auf solchen Spalten bleiben wirkungslos.
Beispiel: Hat eine Dokumententabelle eine Spalte content vom Typ TEXT, greift ein Filter wie content LIKE "%AWS%" nicht.
Empfehlungen für eine effektive Filterung
- Gefilterte Spalten indexieren: Legen Sie für eine bessere Performance des DMS-Tasks Indizes auf den gefilterten Spalten zusammen mit dem Primärschlüssel an. Das beschleunigt die Filterung und entlastet die Quelldatenbank.
- Bei Bedarf zielseitig filtern: Wenn die Spaltenfilterung Ihre Anforderungen nicht erfüllt, verlagern Sie die Filterung auf die Zieldatenbank.
- Filterung auf LOB- und RTL-Spalten vermeiden: Da DMS hier keine Filterung unterstützt, sollten Sie für solche Daten von vornherein einen anderen Weg einplanen.
Wichtige Erkenntnisse:
- DMS prüft Filter auf dem Zustand vor dem Update: Spaltenfilter berücksichtigen ausschließlich die bestehenden Zeilenwerte, bevor das Update angewendet wird.
- Updates können ignoriert werden: Verändert ein Update eine Zeile so, dass sie die Filterbedingung erst danach erfüllt, wird sie nicht repliziert – es sei denn, die Zeile hatte die Bedingung schon vorher erfüllt.
- Workaround setzt zielseitige Filterung voraus: Verzichten Sie für eine korrekte Replikation auf Spaltenfilter in AWS DMS und implementieren Sie die Filterlogik stattdessen in der Zieldatenbank.
In Replikations-Setups, die auf Spaltenfilterung basieren, kann dieses Verhalten zu unerwartetem Datenverlust führen. Wer auf Werten nach dem Update filtern muss, kommt mit AWS DMS allein nicht aus – ohne zusätzliche Logik in der Zieldatenbank lässt sich keine korrekte Replikation gewährleisten.
AWS DMS wertet Spaltenfilter während CDC auf dem Zustand vor dem Update einer Zeile aus. Updates, die eine Zeile so verändern, dass sie die Filterbedingung erst danach erfüllt, werden daher nicht repliziert – mit der Folge unerwarteter Dateninkonsistenzen. Diese Einschränkung kann sich auf Strategien für Datenkonsistenz und Replikation auswirken.
Setzt Ihre Migration auf Filterung nach dem Update, genügt AWS DMS allein nicht; zusätzliche Logik auf Datenbankseite ist Pflicht. Künftige Updates von AWS DMS oder eine bessere Dokumentation könnten dieses Verhalten klarer machen.
Ich hoffe, dieser Blogbeitrag liefert Ihnen wertvolle Einblicke. Wenn Sie mehr erfahren möchten oder sich für unsere Services interessieren, melden Sie sich gerne. Sie erreichen uns hier.