O AWS Database Migration Service (DMS) é uma ferramenta amplamente usada para migração e replicação de bancos de dados, com suporte tanto a ambientes homogêneos quanto heterogêneos. Ao usar o AWS Database Migration Service (DMS) para migrar dados de fontes como Amazon RDS MySQL e Amazon RDS PostgreSQL, aplicar filtros na origem ajuda a limitar a quantidade e o tipo de registros transferidos para o banco de destino. Mesmo assim, vale conhecer algumas limitações desses filtros para garantir uma migração tranquila.
Visão geral do AWS DMS
O AWS DMS viabiliza a migração de dados replicando continuamente as alterações da origem para o banco de destino, com tempo de inatividade mínimo. Entre seus principais recursos estão:
- Full Load, CDC e replicação contínua: dá suporte à migração inicial e à sincronização contínua.
- Mapeamento de schemas e tabelas: permite incluir e transformar objetos com flexibilidade.
- Recursos de filtragem: oferece filtragem em nível de linha e de coluna para controlar quais dados são replicados.
- Suporte a vários mecanismos de banco de dados: funciona com MySQL, PostgreSQL, SQL Server, Oracle e outros.
Apesar desses recursos, a filtragem por coluna no AWS DMS nem sempre se comporta como o esperado, principalmente quando há atualizações durante o CDC.
O que é filtragem por coluna no AWS DMS?
A filtragem por coluna no AWS DMS permite incluir ou excluir linhas da replicação com base em condições aplicadas a colunas específicas. Por exemplo, dá para configurar uma tarefa do DMS para replicar apenas as linhas em que uma coluna como ‘status’ seja igual a ‘active’ ou em que uma coluna ‘timestamp’ seja maior que uma data específica. Isso é especialmente útil quando você precisa migrar só um subconjunto dos dados ou aplicar regras de negócio durante a migração.
Veja um exemplo de regra de filtro por coluna no DMS:
{
"rules": [\
{\
"rule-type": "selection",\
"rule-id": "1",\
"rule-name": "FilterActiveUsers",\
"object-locator": {\
"schema-name": "public",\
"table-name": "users"\
},\
"rule-action": "include",\
"filters": [\
{\
"filter-type": "source",\
"column-name": "status",\
"filter-conditions": [\
{\
"filter-operator": "eq",\
"value": "active"\
}\
]\
}\
]\
}\
]
Caso de uso: filtragem por coluna durante a migração de dados
Para testar como o DMS lida com a filtragem por coluna, fizemos uma prova de conceito (POC) migrando dados de uma instância RDS MySQL 8.0 para outra instância RDS MySQL 8.0 usando o AWS Database Migration Service (DMS). O requisito era simples: replicar linhas da tabela de origem para a tabela de destino apenas quando uma coluna específica, chamada "name", atendesse a uma condição (no caso, name = "b"). Para isso, recorremos ao recurso de filtragem por coluna na origem do DMS, que permite incluir ou excluir linhas com base em valores específicos.
Configuração
- Origem: RDS MySQL 8.0.36
- Destino: RDS MySQL 8.0.36
- Versão do DMS: Engine 3.5.4
- Modo de migração: Full Load com CDC
Uma tabela de exemplo foi criada no banco de origem:
CREATE TABLE `Sample` (
`id` varchar(255) NOT NULL,
`name` varchar(255) NOT NULL,
PRIMARY KEY (`id`)
);
Configuramos uma tarefa de migração no DMS com um filtro em nível de coluna para replicar apenas as linhas em que name = ‘b’.
Regra de mapeamento do DMS:
{
"rules": [\
{\
"rule-type": "selection",\
"rule-id": "098947021",\
"rule-name": "098947021",\
"object-locator": {\
"schema-name": "Test",\
"table-name": "Sample"\
},\
"rule-action": "include",\
"filters": [\
{\
"filter-type": "source",\
"column-name": "name",\
"filter-conditions": [\
{\
"filter-operator": "eq",\
"value": "b"\
}\
]\
}\
]\
}\
]
}
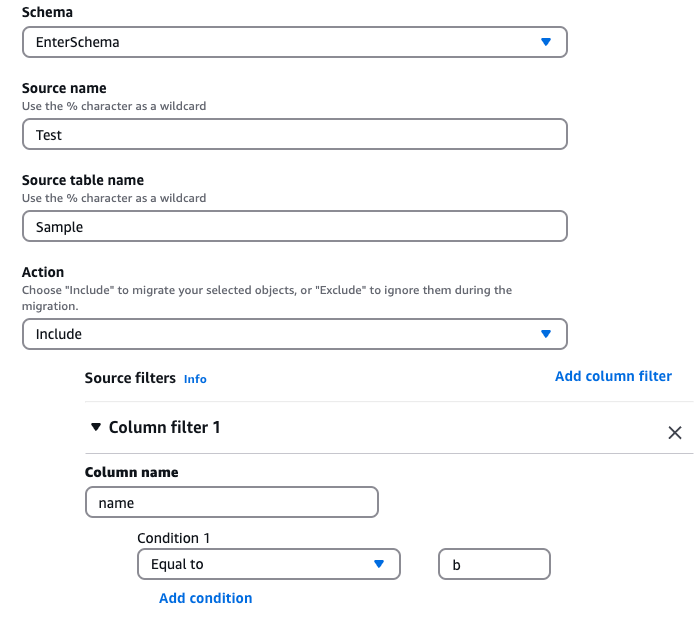
regra de seleção com filtro de origem
Observações e constatações:

Quando uma linha com name = ‘b’ foi inserida, ela foi replicada corretamente. Da mesma forma, uma inserção com name = ‘a’ foi corretamente ignorada. Já as atualizações apresentam inconsistências:
- A atualização de name=’a’ para name=’b’ foi ignorada, mesmo com o CDC tendo capturado o evento.

Se a validação do DMS estiver ativada, esse comportamento gera registros divergentes entre os bancos de origem e destino, já que a validação sinaliza as discrepâncias.
Isso reforça como o AWS DMS aplica os filtros com base no estado anterior à atualização, o que pode comprometer a integridade dos dados quando a filtragem por coluna está em uso.

Causa raiz: como o AWS DMS aplica os filtros
O AWS DMS avalia os filtros por coluna com base no estado da linha antes da atualização. Ou seja:
- Eventos de inserção: o filtro é aplicado aos valores da linha inserida.
- Eventos de atualização: o filtro é avaliado antes da atualização ser aplicada.
- Eventos de exclusão: o filtro verifica o estado da linha antes da exclusão.
Como as atualizações são filtradas pelo estado original da linha, uma alteração de name = ‘a’ para name = ‘b’ é ignorada. A linha não atendia à condição do filtro antes da atualização, então nunca chega a ser replicada.
Esse comportamento pode causar inconsistências nos dados. Se uma aplicação depende da filtragem de linhas após uma atualização, os dados esperados podem nunca ser replicados.
Solução alternativa: filtragem no banco de destino
Como o AWS DMS não permite aplicar filtros depois de uma atualização processada, é preciso recorrer a uma solução alternativa:
Etapa 1: remover os filtros de coluna da tarefa do DMS
Ajuste a tarefa do DMS para replicar todos os dados sem filtragem.
Etapa 2: implementar a filtragem no banco de destino
Em vez de replicar diretamente para a tabela Sample no banco de destino, replique para uma tabela de staging e use uma trigger ou stored procedure para mover as linhas válidas até a tabela Sample.
Crie uma tabela de staging (sample_staging) no banco RDS MySQL de destino. Ela vai armazenar temporariamente os dados replicados antes de eles seguirem para a tabela Sample.
Por exemplo, no MySQL:
CREATE TABLE sample_staging (
id INT PRIMARY KEY,
name VARCHAR(255)
);
Etapa 3: criar uma stored procedure
Crie uma stored procedure para mover as linhas válidas (por exemplo, aquelas em que name = ‘b’) da tabela de staging (sample_staging) para a tabela de destino (Sample). Essa procedure cuida tanto das inserções quanto das atualizações.
CREATE PROCEDURE MoveValidRowsToSample()
BEGIN
-- Insert or update valid rows in the Sample table
INSERT INTO Sample (id, name)
SELECT id, name
FROM sample_staging
WHERE name = 'b'
ON DUPLICATE KEY UPDATE
name = VALUES(name);
--Delete valid rows from the staging table
DELETE FROM sample_staging
WHERE name = 'b';
END
Etapa 4: criar uma trigger
Crie uma trigger na tabela de staging (sample_staging) para chamar automaticamente a stored procedure sempre que uma linha for inserida ou atualizada.
CREATE TRIGGER after_insert_sample_staging
AFTER INSERT ON sample_staging
FOR EACH ROW
BEGIN
CALL MoveValidRowsToSample();
END
CREATE TRIGGER after_update_sample_staging
AFTER UPDATE ON sample_staging
FOR EACH ROW
BEGIN
CALL MoveValidRowsToSample();
END
Como isso funciona
- Banco de origem: contém os dados originais.
- AWS DMS: replica os dados da origem para a tabela sample_staging no banco RDS MySQL de destino.
- Tabela de staging (sample_staging): armazena temporariamente todos os dados replicados.
- Trigger: dispara a stored procedure sempre que dados são inseridos ou atualizados na tabela sample_staging.
- Stored procedure: move as linhas válidas (em que name = ‘b’) de sample_staging para a tabela Sample.
- Tabela de destino (Sample): mantém apenas as linhas válidas depois que a trigger e a stored procedure processam os dados.
No PostgreSQL, dá para implementar uma função semelhante usando triggers BEFORE INSERT OR UPDATE.
Testes no RDS PostgreSQL
Para confirmar que esse comportamento não era específico do MySQL, fizemos o mesmo teste no RDS PostgreSQL. Os resultados foram idênticos:
- Atualizações que faziam uma linha passar a atender à condição do filtro não foram replicadas para a tabela de destino.
- Isso confirma que o problema não é específico de um banco, mas sim uma limitação de como o DMS lida com filtros por coluna durante o CDC.
Outras limitações dos filtros de origem do DMS
- Colunas com idiomas da direita para a esquerda (RTL): ao usar filtros de origem do DMS, é natural supor que a ferramenta dê conta de qualquer tipo de dado, independentemente do idioma ou do alfabeto. Mas não é o caso. Os filtros de origem do DMS não processam colunas com idiomas RTL, como o hebraico. Se as condições do filtro envolverem essas colunas, ele pode não funcionar como esperado, resultando em replicação incompleta ou incorreta dos dados.
Exemplo: se você tem uma coluna com texto em hebraico (por exemplo, customer_name em hebraico) e aplica uma condição de filtro como customer_name = "דוד", o DMS pode falhar ao avaliar a condição corretamente.
- Colunas Large Object (LOB): os filtros não funcionam em colunas LOB, como BLOBs, CLOBs ou TEXT no MySQL e BYTEA ou TEXT no PostgreSQL. Tentar filtrar por essas colunas não terá efeito.
Exemplo: se a tabela de um documento tem uma coluna content do tipo TEXT, definir um filtro como content LIKE ‘%AWS%’ não vai funcionar.
Recomendações para uma filtragem eficaz
- Indexe as colunas filtradas: para melhorar o desempenho da tarefa do DMS, crie índices nas colunas filtradas junto com a chave primária. Isso garante uma filtragem eficiente e reduz a carga no banco de origem.
- Use filtragem no destino quando necessário: se o comportamento da filtragem por coluna não atender ao seu cenário, aplique os filtros direto no banco de destino.
- Evite filtrar colunas LOB e RTL: como o DMS não dá suporte a filtragem em colunas LOB ou em texto RTL, planeje abordagens alternativas para tratar esses dados.
Principais aprendizados:
- O DMS avalia os filtros pelo estado anterior à atualização: os filtros por coluna verificam apenas os valores atuais da linha antes da atualização ser aplicada.
- Atualizações podem ser ignoradas: se uma atualização modificar uma linha para passar a atender à condição do filtro, ela não será replicada, a menos que a linha já cumprisse a condição antes.
- A solução alternativa exige filtragem no destino: para garantir uma replicação correta, evite os filtros por coluna no AWS DMS e aplique a lógica de filtragem no banco de destino.
Esse comportamento pode causar perda inesperada de dados em cenários de replicação que dependem da filtragem por coluna. Se você precisa filtrar com base nos valores pós-atualização, o AWS DMS sozinho não dá conta — é preciso implementar uma lógica adicional no banco de destino para garantir uma replicação precisa.
O AWS DMS avalia os filtros por coluna com base no estado anterior à atualização de uma linha durante o CDC. Como consequência, atualizações que alteram uma linha para corresponder à condição do filtro não são replicadas, o que pode gerar inconsistências inesperadas. Essa limitação pode afetar suas estratégias de consistência e replicação de dados.
Se a sua migração depende de filtragem pós-atualização, o AWS DMS sozinho não basta: é preciso uma lógica adicional do lado do banco. Atualizações futuras do AWS DMS ou uma documentação mais clara podem ajudar a esclarecer esse comportamento.
Espero que este post tenha trazido insights valiosos. Se quiser saber mais ou tiver interesse nos nossos serviços, fale com a gente. É só entrar em contato aqui.