AWS Database Migration Service (DMS) est un outil largement utilisé pour la migration et la réplication de bases de données, dans des environnements homogènes comme hétérogènes. Lorsque vous utilisez AWS DMS pour migrer des données depuis des sources telles qu'Amazon RDS MySQL ou Amazon RDS PostgreSQL, la mise en place de filtres source permet de limiter efficacement le nombre et le type d'enregistrements transférés vers la base cible. Il reste toutefois essentiel de connaître certaines limites associées à ces filtres pour garantir le bon déroulement de la migration.
Présentation d'AWS DMS
AWS DMS permet de migrer les données en répliquant en continu les modifications de la base source vers la base cible, avec un temps d'arrêt minimal. Parmi ses principales fonctionnalités :
- Full Load, CDC et réplication continue : migration initiale et synchronisation continue.
- Mappage des schémas et des tables : inclusion et transformation flexibles des objets.
- Capacités de filtrage : filtrage au niveau des lignes et des colonnes pour maîtriser les données répliquées.
- Compatibilité multi-moteurs : MySQL, PostgreSQL, SQL Server, Oracle, et d'autres.
Malgré ces atouts, le filtrage par colonne dans AWS DMS ne fonctionne pas toujours comme attendu, notamment lors du traitement des mises à jour pendant le CDC.
Qu'est-ce que le filtrage par colonne dans AWS DMS ?
Le filtrage par colonne dans AWS DMS permet d'inclure ou d'exclure des lignes de la réplication selon des conditions appliquées à des colonnes spécifiques. Vous pouvez par exemple configurer une tâche DMS pour ne répliquer que les lignes où une colonne status vaut active, ou dont la colonne timestamp est postérieure à une date donnée. C'est particulièrement utile pour migrer un sous-ensemble de données ou appliquer une logique métier durant la migration.
Voici un exemple de règle de filtre par colonne dans DMS :
{
"rules": [\
{\
"rule-type": "selection",\
"rule-id": "1",\
"rule-name": "FilterActiveUsers",\
"object-locator": {\
"schema-name": "public",\
"table-name": "users"\
},\
"rule-action": "include",\
"filters": [\
{\
"filter-type": "source",\
"column-name": "status",\
"filter-conditions": [\
{\
"filter-operator": "eq",\
"value": "active"\
}\
]\
}\
]\
}\
]
Cas d'usage : filtrage par colonne lors d'une migration de données
Pour évaluer la façon dont DMS gère le filtrage par colonne, nous avons mené une preuve de concept (POC) consistant à migrer des données d'une instance RDS MySQL 8.0 vers une autre instance RDS MySQL 8.0 via AWS DMS. L'objectif était simple : répliquer les lignes de la table source vers la table cible uniquement lorsqu'une colonne précise, nommée name, remplit une certaine condition (à savoir name = b). Pour y parvenir, nous avons utilisé la fonction de filtrage par colonne source de DMS, qui permet d'inclure ou d'exclure des lignes selon des valeurs spécifiques.
Configuration
- Source : RDS MySQL 8.0.36
- Cible : RDS MySQL 8.0.36
- Version DMS : moteur 3.5.4
- Mode de migration : Full Load avec CDC
Une table d'exemple a été créée dans la base source :
CREATE TABLE `Sample` (
`id` varchar(255) NOT NULL,
`name` varchar(255) NOT NULL,
PRIMARY KEY (`id`)
);
Une tâche de migration DMS a été configurée avec un filtre au niveau de la colonne pour ne répliquer que les lignes où name = b.
Règle de mappage DMS :
{
"rules": [\
{\
"rule-type": "selection",\
"rule-id": "098947021",\
"rule-name": "098947021",\
"object-locator": {\
"schema-name": "Test",\
"table-name": "Sample"\
},\
"rule-action": "include",\
"filters": [\
{\
"filter-type": "source",\
"column-name": "name",\
"filter-conditions": [\
{\
"filter-operator": "eq",\
"value": "b"\
}\
]\
}\
]\
}\
]
}
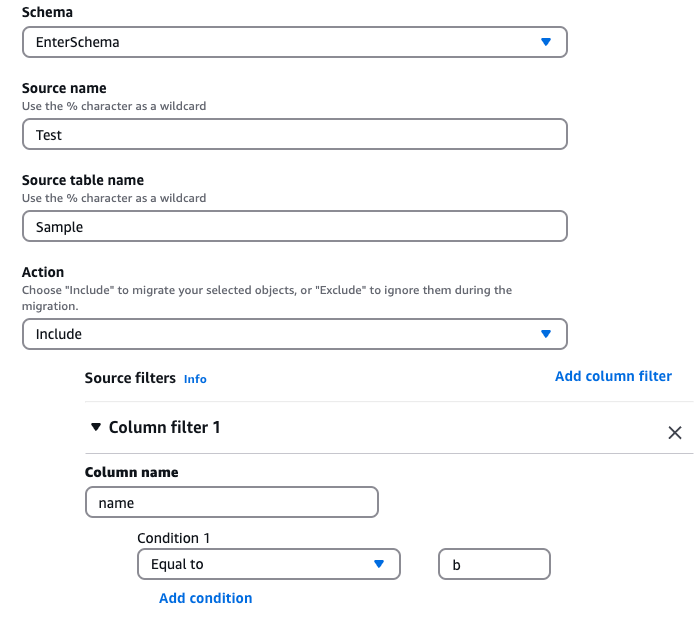
Règle de sélection avec filtre source
Observations et constats

Lorsqu'une ligne avec name = b a été insérée, elle a bien été répliquée. De même, une insertion avec name = a a correctement été ignorée. Les mises à jour, en revanche, font apparaître des incohérences :
- La mise à jour de name = a vers name = b a été ignorée, alors même que le CDC avait capturé l'événement.

Si la validation DMS est activée, ce comportement entraînera des écarts entre les bases source et cible, la validation signalant alors des divergences.
Cela illustre clairement la manière dont AWS DMS applique les filtres en se basant sur l'état antérieur à la mise à jour, ce qui peut compromettre l'intégrité des données dès lors qu'un filtrage par colonne est utilisé.

Cause racine — comment AWS DMS applique les filtres
AWS DMS évalue les filtres par colonne en s'appuyant sur l'état de la ligne avant qu'une mise à jour ne se produise. Concrètement :
- Événements d'insertion : le filtre s'applique aux valeurs de la ligne insérée.
- Événements de mise à jour : le filtre est évalué avant l'application de la mise à jour.
- Événements de suppression : le filtre vérifie l'état de la ligne avant la suppression.
Comme les mises à jour sont filtrées sur la base de l'état initial de la ligne, une mise à jour qui transforme name = a en name = b est ignorée. La ligne ne remplissait pas la condition du filtre avant la mise à jour : elle n'est donc jamais répliquée.
Ce comportement peut provoquer des incohérences de données. Si une application repose sur le filtrage de lignes après une mise à jour, les données attendues risquent de ne jamais être répliquées.
Contournement : filtrer côté base de données cible
AWS DMS ne permettant pas d'appliquer un filtre après le traitement d'une mise à jour, un contournement s'impose :
Étape 1 : retirer les filtres par colonne de la tâche DMS
Modifiez la tâche DMS pour répliquer toutes les données sans filtrage.
Étape 2 : mettre en place le filtrage sur la base de données cible
Plutôt que de répliquer directement vers la table Sample dans la base cible, vous pouvez répliquer vers une table de staging, puis utiliser un trigger ou une procédure stockée pour transférer les lignes valides vers la table Sample.
Créez une table de staging (sample_staging) dans la base RDS MySQL cible. Cette table contiendra temporairement les données répliquées avant leur transfert vers la table Sample.
Par exemple, en MySQL :
CREATE TABLE sample_staging (
id INT PRIMARY KEY,
name VARCHAR(255)
);
Étape 3 : créer une procédure stockée
Créez une procédure stockée pour déplacer les lignes valides (par exemple celles où name = b) de la table de staging (sample_staging) vers la table cible (Sample). Cette procédure prend en charge à la fois les insertions et les mises à jour.
CREATE PROCEDURE MoveValidRowsToSample()
BEGIN
-- Insert or update valid rows in the Sample table
INSERT INTO Sample (id, name)
SELECT id, name
FROM sample_staging
WHERE name = 'b'
ON DUPLICATE KEY UPDATE
name = VALUES(name);
--Delete valid rows from the staging table
DELETE FROM sample_staging
WHERE name = 'b';
END
Étape 4 : créer un trigger
Créez un trigger sur la table de staging (sample_staging) afin d'appeler automatiquement la procédure stockée à chaque insertion ou mise à jour de ligne.
CREATE TRIGGER after_insert_sample_staging
AFTER INSERT ON sample_staging
FOR EACH ROW
BEGIN
CALL MoveValidRowsToSample();
END
CREATE TRIGGER after_update_sample_staging
AFTER UPDATE ON sample_staging
FOR EACH ROW
BEGIN
CALL MoveValidRowsToSample();
END
Fonctionnement
- Base de données source : contient les données d'origine.
- AWS DMS : réplique les données de la source vers la table sample_staging dans la base RDS MySQL cible.
- Table de staging (sample_staging) : contient temporairement l'ensemble des données répliquées.
- Trigger : appelle automatiquement une procédure stockée à chaque insertion ou mise à jour dans la table sample_staging.
- Procédure stockée : déplace les lignes valides (où name = b) de sample_staging vers la table Sample.
- Table cible (Sample) : ne contient que les lignes valides, après traitement par le trigger et la procédure stockée.
Pour PostgreSQL, une fonction similaire peut être implémentée à l'aide de triggers BEFORE INSERT OR UPDATE.
Tests sur RDS PostgreSQL
Pour vérifier que ce comportement n'était pas propre à MySQL, nous avons reproduit le même test sur RDS PostgreSQL. Les résultats ont été identiques :
- Les mises à jour qui amenaient une ligne à satisfaire la condition du filtre n'étaient pas répliquées vers la table cible.
- Cela confirme que le problème ne dépend pas du moteur de base de données, mais relève bien d'une limite propre à la gestion des filtres par colonne par DMS pendant le CDC.
Autres limites des filtres source de DMS
- Colonnes en langues s'écrivant de droite à gauche (RTL) : on pourrait penser que les filtres source de DMS gèrent tous les types de données, quelles que soient la langue ou l'écriture. Ce n'est pas le cas. Les filtres source de DMS ne traitent pas les colonnes contenant des langues RTL comme l'hébreu. Si vos conditions de filtre portent sur ces colonnes, les filtres risquent de ne pas fonctionner comme prévu et d'entraîner une réplication incomplète ou erronée des données.
Exemple : si une colonne contient du texte en hébreu (par exemple customer_name en hébreu) et que vous appliquez une condition de filtre du type customer_name = דוד, DMS peut ne pas évaluer la condition correctement.
- Colonnes Large Object (LOB) : les filtres ne peuvent pas être appliqués aux colonnes LOB, telles que BLOB, CLOB ou TEXT en MySQL, ainsi que BYTEA ou TEXT en PostgreSQL. Toute tentative de filtrage sur ces colonnes restera sans effet.
Exemple : si la table d'un document contient une colonne content de type TEXT, définir un filtre tel que content LIKE %AWS% ne fonctionnera pas.
Recommandations pour un filtrage efficace
- Indexer les colonnes filtrées : pour améliorer les performances de la tâche DMS, créez des index sur les colonnes filtrées en complément de la clé primaire. Cela garantit un filtrage efficace et réduit la charge sur la base de données source.
- Recourir au filtrage côté cible si nécessaire : si le comportement du filtrage par colonne ne répond pas à vos besoins, appliquez plutôt les filtres directement sur la base de données cible.
- Éviter le filtrage sur les colonnes LOB et RTL : DMS ne prenant en charge ni le filtrage sur les colonnes LOB, ni les textes RTL, prévoyez des approches alternatives pour traiter ces données.
Points clés à retenir
- DMS évalue les filtres sur l'état antérieur à la mise à jour : les filtres par colonne ne vérifient que les valeurs existantes de la ligne avant l'application d'une mise à jour.
- Les mises à jour peuvent être ignorées : si une mise à jour modifie une ligne pour qu'elle satisfasse la condition du filtre, elle ne sera pas répliquée, à moins que la ligne n'ait déjà rempli la condition au préalable.
- Le contournement passe par un filtrage côté cible : pour assurer une réplication correcte, évitez les filtres par colonne dans AWS DMS et appliquez plutôt la logique de filtrage sur la base de données cible.
Ce comportement peut provoquer des pertes de données inattendues dans les configurations de réplication qui reposent sur le filtrage par colonne. Si vous devez filtrer en fonction des valeurs postérieures à une mise à jour, AWS DMS seul ne suffit pas : une logique supplémentaire doit être mise en place sur la base de données cible pour garantir une réplication fidèle.
AWS DMS évalue les filtres par colonne sur l'état antérieur à la mise à jour d'une ligne pendant le CDC. Par conséquent, les mises à jour qui modifient une ligne pour la rendre conforme à la condition du filtre ne sont pas répliquées, ce qui peut entraîner des incohérences de données inattendues. Cette limite peut peser sur vos stratégies de réplication et sur la cohérence des données.
Si votre migration repose sur un filtrage post-mise à jour, AWS DMS seul ne suffit pas : une logique supplémentaire côté base de données est indispensable. De futures évolutions d'AWS DMS ou une documentation enrichie pourraient permettre de mieux clarifier ce comportement.
Nous espérons que cet article vous aura apporté des éclairages utiles. Pour en savoir plus ou pour découvrir nos services, n'hésitez pas à nous contacter ici.