In meinem vorherigen Beitrag habe ich die grundlegenden Bausteine zur Umsetzung von Event-Driven Architecture (EDA) mit AWS Managed Services beschrieben. In diesem Beitrag geht es um die fortgeschrittenen Grundlagen. Fortgeschritten deshalb, weil aus meiner Beratungspraxis nur sehr wenige Unternehmen die Praktiken anwenden, die ich hier behandeln möchte. Trotzdem zähle ich sie zu den Grundlagen, denn sie sind nicht optional, sondern unverzichtbar für den Aufbau zuverlässiger, nachrichtenbasierter Systeme.
Auch wenn die Beispiele in diesem Beitrag AWS-Dienste nutzen, gilt der Inhalt für jedes System – unabhängig von der zugrunde liegenden Infrastruktur. Die Implementierung kann sich unterscheiden, die zugrunde liegenden Prinzipien bleiben dieselben.
Da es in diesem Beitrag um ein Pattern geht – und Patterns per Definition wiederverwendbare Lösungen für häufig auftretende Probleme sind – möchte ich mit einem Problem beginnen, das in EDA-basierten Systemen oft übersehen wird.
Das Problem
Im vorherigen Beitrag habe ich vorgeschlagen, AWS SNS für das Veröffentlichen von Nachrichten in einem Event-Driven-System einzusetzen. Hier ein typisches Beispiel, wie eine solche Veröffentlichung aussehen kann:
...
sns.publish(
TopicArn=users_topic_arn,
Message=json.dumps({
'event_type': 'user_registered',
'event_id': str(uuid.uuid4()),
'user_id': 'USER12345',
'name': 'John Doe',
'email': '[email protected]',
'source': 'mobile_app',
'registration_date': '2024-10-11T20:01:00Z'
})
)
...
Im obigen Beispiel wird ein Event vom Typ user_registered in einem SNS-Topic veröffentlicht. Aber kommt dieses Event aus dem Nichts? Tun Services tatsächlich nichts anderes, als Nachrichten zu veröffentlichen? Natürlich nicht. Das Event ist Teil eines größeren Geschäftsprozesses, der typischerweise einen Zustand in einer operativen Datenbank aktualisiert, bevor externe Komponenten darüber informiert werden. Eine genauere Darstellung dieses Ablaufs sähe so aus:
...
# Persist state changes
users_table.put_item(
Item={
'user_id': user_id,
'name': name,
'password_hash': password_hash,
'email': email,
'source': source,
'registration_date': registration_date,
'created_at': datetime.utcnow().isoformat()
}
)
# Publish corresponding events
sns.publish(
TopicArn=users_topic_arn,
Message=json.dumps({
'event_type': 'user_registered',
'event_id': str(uuid.uuid4()),
'user_id': user_id,
'name': name,
'email': email,
'source': source,
'registration_date': registration_date
})
)
...
Zuerst wird der neue Nutzer persistiert, anschließend die Benachrichtigung veröffentlicht. Auf den ersten Blick wirkt der Code unkompliziert – doch denken Sie über diese drei Fragen nach:
- Was kann hier schiefgehen?
- Welche Konsequenzen hat das?
- Würden Sie diesen Code als zuverlässig bezeichnen?
Halten Sie kurz inne und überlegen Sie, bevor Sie weiterlesen.
Gut, vergleichen wir unsere Antworten.
Wenn zwischen dem Schreiben in die Datenbank und dem Veröffentlichen der Nachricht etwas schiefgeht, befindet sich das System in einem inkonsistenten Zustand. Der Nutzer bekommt möglicherweise eine Fehlermeldung und nimmt an, der gesamte Vorgang sei fehlgeschlagen – tatsächlich wurde der Datensatz aber bereits angelegt. Die Subscriber des user_registered-Events erfahren davon jedoch nichts, weil die Nachricht nie veröffentlicht wurde. Warum kann das passieren? Der Server kann neu starten, das Lambda kann in einen Timeout laufen, es kann zu Netzwerkpartitionen kommen – oder zu unzähligen anderen Ursachen, gerade in der Cloud.
Die Konsistenz eines Event-Driven-Systems hängt davon ab, ob es Nachrichten zuverlässig zwischen seinen Komponenten zustellen kann. Genau das ist hier nicht der Fall. Trotz der scheinbaren Einfachheit ist der obige Code nicht zuverlässig.
Was lässt sich also tun? Können wir das Schreiben in die Datenbank und das Veröffentlichen eines Events in einer atomaren Transaktion zusammenfassen? Nein. Es gab in der Vergangenheit Versuche in diese Richtung (z. B. DTC), die jedoch nicht gut endeten. Two-Phase Commit? Hilft ebenfalls nicht, da es unter ähnlichen Fehlerbedingungen leidet.
Die zuverlässige Lösung besteht darin, aus zwei Transaktionen eine einzige zu machen. Wie? Sprechen wir über das Outbox-Pattern.
Die Lösung: Outbox
Die Idee hinter dem Outbox-Pattern ist denkbar einfach. Zunächst persistieren Sie sowohl die Zustandsänderungen als auch die ausgehenden Nachrichten in einer einzigen atomaren Transaktion in der operativen Datenbank. Entweder gelingt beides oder beides schlägt fehl – dazwischen gibt es nichts. Anschließend holt ein externer Mechanismus – das Publishing-Relay – die committeten Nachrichten ab und veröffentlicht sie asynchron auf einem Message Bus.

Abbildung 1: Das Outbox-Pattern
Implementierung: Allgemein
Es gibt keinen universellen Weg, das Outbox-Pattern umzusetzen. Die Details hängen vom verwendeten Technologie-Stack ab, allen voran von der Datenbank.
Erstens bestimmt die Datenbank, welche Mittel Ihnen zur Verfügung stehen – oder eben nicht – um aktualisierte Daten und ausgehende Nachrichten in einer atomaren Transaktion zu committen. Unterstützt sie Transaktionen über mehrere Tabellen (z. B. relationale Datenbanken, DynamoDB usw.), können Sie die Nachrichten in einer dedizierten Tabelle ablegen, die üblicherweise "outbox" heißt. Falls nicht, müssen sowohl der aktualisierte Zustand als auch die Nachrichten in einem einzigen Datensatz persistiert werden.
Zweitens benötigen Sie einen zuverlässigen Weg, die persistierten Nachrichten abzuholen. Manche Datenbanken ermöglichen das Push-Modell: Die Datenbank selbst ruft das Publishing-Relay auf und übergibt ihm die neuen Nachrichten. Beispiele dafür sind Lambda-Trigger in DynamoDB oder ein Change Data Capture (CDC)-Mechanismus in relationalen Datenbanken.
Letztlich definiert die Art, wie Sie Nachrichten persistieren und abholen, auch wie Sie sicherstellen, dass dieselbe Nachricht nicht unnötig erneut aufgegriffen und veröffentlicht wird.
Implementierung: Beispiel
Kommen wir zurück zu unserem Ausgangsbeispiel. Da der Code DynamoDB nutzt, lässt sich das Outbox-Pattern hier am einfachsten umsetzen, indem man dessen Multi-Tabellen-Transaktionen nutzt und die ausgehenden Events in eine dedizierte Tabelle schreibt:
...
with dynamodb.meta.client.transact_write_items(
TransactItems=[\
{\
'Put': {\
'TableName': users_table.name,\
'Item': {\
'user_id': user_id,\
'name': name,\
'password_hash': password_hash,\
'email': email,\
'source': source,\
'registration_date': registration_date,\
'created_at': datetime.utcnow().isoformat()\
}\
}\
},\
{\
'Put': {\
'TableName': outbox_table.name,\
'Item': {\
'event_id': event_id,\
'data': {\
'event_type': 'user_registered',\
'event_id': event_id,\
'user_id': user_id,\
'name': name,\
'email': email,\
'source': source,\
'registration_date': registration_date\
}\
}\
}\
}\
]
)
...
Als Nächstes müssen wir entscheiden, wie die Events tatsächlich in das SNS-Topic veröffentlicht werden. Am einfachsten ist es, DynamoDB Streams auf der Outbox-Tabelle zu nutzen, um für jeden neuen Datensatz eine Lambda-Funktion auszulösen, die dessen Events im SNS-Topic veröffentlicht.
Schließlich müssen Sie entscheiden, was mit bereits veröffentlichten Nachrichten geschehen soll. Die Publishing-Funktion könnte die Datensätze aus der Outbox-Tabelle löschen, sobald sie die Bestätigung erhält, dass die Veröffentlichung in SNS erfolgreich abgeschlossen wurde. Alternativ kann sie den Datensatz behalten und mit dem Zeitstempel der tatsächlichen Veröffentlichung aktualisieren.
Abbildung 2 fasst die vollständige Lösung zusammen:
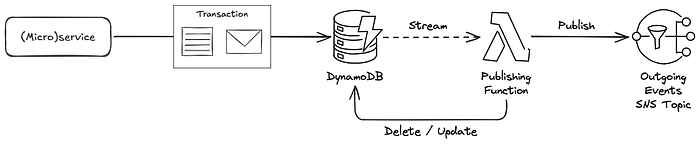
Abbildung 2: Das Outbox-Pattern, umgesetzt mit AWS DynamoDB, Lambda und SNS
Verglichen mit dem naiven Ansatz, die ausgehenden Events einfach in das passende SNS-Topic zu schreiben, entsteht durch das Outbox-Pattern ein komplexeres System mit mehr beweglichen Teilen. Dafür ist das Ergebnis zuverlässig: Sobald die ursprüngliche Transaktion committet wurde, werden die zugehörigen Events – egal was zur Laufzeit passiert – veröffentlicht und an die Subscriber zugestellt.
Beiträge der Serie
- Event-Driven Architecture on AWS, Teil I: The Basics
- Event-Driven Architecture on AWS, Teil II: The Advanced Basics (aktueller Beitrag)
- Event-Driven Architecture on AWS, Teil III: The Hard Basics
Ursprünglich veröffentlicht auf https://vladikk.com.
Die Konsistenz eines Event-Driven-Systems hängt davon ab, wie zuverlässig es Nachrichten zwischen seinen Komponenten zustellen kann. Das Outbox-Pattern ermöglicht es, Zustandsänderungen und die daraus resultierenden Events als atomare Transaktion zu speichern und zu veröffentlichen – selbst dann, wenn die zugrunde liegende Infrastruktur keine serviceübergreifenden Transaktionen unterstützt. Die Zuverlässigkeit, die die Outbox dem System verleiht, wiegt den Implementierungsaufwand bei Weitem auf.