Dans mon précédent article, j'ai présenté les briques de base pour mettre en œuvre une architecture événementielle (EDA) avec les services managés AWS. Ce nouvel article aborde les fondamentaux avancés. Avancés parce que, d'après mon expérience de consultant, très peu d'entreprises appliquent les pratiques que je souhaite aborder. Je les considère néanmoins comme des fondamentaux car elles ne sont pas optionnelles : elles sont indispensables pour bâtir des systèmes de messagerie fiables.
Bien que les exemples de cet article s'appuient sur des services AWS, le propos vaut pour n'importe quel système, quelle que soit l'infrastructure sous-jacente. La mise en œuvre peut varier, mais les principes restent les mêmes.
Comme cet article traite d'un pattern — et qu'un pattern est, par définition, une solution réutilisable à un problème récurrent —, commençons par évoquer un problème souvent négligé dans les systèmes EDA.
Le problème
Dans l'article précédent, je suggérais d'utiliser AWS SNS pour publier des messages dans un système événementiel. Voici un exemple courant de publication :
...
sns.publish(
TopicArn=users_topic_arn,
Message=json.dumps({
'event_type': 'user_registered',
'event_id': str(uuid.uuid4()),
'user_id': 'USER12345',
'name': 'John Doe',
'email': '[email protected]',
'source': 'mobile_app',
'registration_date': '2024-10-11T20:01:00Z'
})
)
...
Dans cet exemple, un événement de type user_registered est publié sur un topic SNS. Mais cet événement est-il sorti de nulle part ? Les services se contentent-ils de publier des messages ? Évidemment non. L'événement s'inscrit dans un processus métier plus large, qui implique généralement la mise à jour d'un état dans une base de données opérationnelle avant d'en notifier les composants externes. Une représentation plus fidèle de ce processus ressemblerait à ceci :
...
# Persist state changes
users_table.put_item(
Item={
'user_id': user_id,
'name': name,
'password_hash': password_hash,
'email': email,
'source': source,
'registration_date': registration_date,
'created_at': datetime.utcnow().isoformat()
}
)
# Publish corresponding events
sns.publish(
TopicArn=users_topic_arn,
Message=json.dumps({
'event_type': 'user_registered',
'event_id': str(uuid.uuid4()),
'user_id': user_id,
'name': name,
'email': email,
'source': source,
'registration_date': registration_date
})
)
...
D'abord, le nouvel utilisateur est persisté, puis une notification est publiée. Ce code paraît évident, mais posez-vous ces trois questions :
- Qu'est-ce qui peut mal tourner ?
- Quelles en seraient les conséquences ?
- Peut-on dire que ce code est fiable ?
Faites une pause et réfléchissez-y avant de poursuivre.
Très bien, comparons nos réponses.
Si quelque chose se passe mal entre l'écriture en base de données et la publication du message, le système se retrouve dans un état incohérent. L'utilisateur peut recevoir une erreur en pensant que toute l'opération a échoué, alors que l'enregistrement aura bel et bien été créé en base. Pourtant, les abonnés à l'événement user_registered ne seront pas notifiés, faute de message publié. Pourquoi cela peut-il arriver ? Le serveur peut redémarrer, la Lambda peut atteindre son timeout, des partitions réseau peuvent survenir, et bien d'autres causes encore — surtout dans le cloud.
La cohérence d'un système événementiel dépend de sa capacité à acheminer ses messages de façon fiable entre ses composants. Ce n'est pas le cas ici. Malgré son apparente simplicité, le code ci-dessus n'est pas fiable.
Que faire alors ? Peut-on englober l'écriture en base et la publication d'un événement dans une transaction atomique ? Non. Des tentatives ont été faites par le passé (par exemple DTC), sans réel succès. Le two-phase commit ? Pas davantage : il souffre des mêmes modes de défaillance.
La solution fiable consiste à transformer ces deux transactions en une seule. Comment ? Parlons du pattern outbox.
La solution : le pattern outbox
Le principe du pattern outbox est très simple. Vous persistez d'abord à la fois les changements d'état et les messages sortants dans la base de données opérationnelle, en une seule transaction atomique. Soit les deux réussissent, soit les deux échouent — jamais d'entre-deux. Ensuite, un mécanisme externe — un relais de publication — récupère les messages validés et les publie de manière asynchrone sur un bus de messages.

Figure 1 : le pattern outbox
Mise en œuvre : généralités
Il n'existe pas de méthode universelle pour implémenter le pattern outbox. Les détails dépendent de la stack technologique en place, et avant tout de la base de données.
D'abord, la base de données détermine les moyens dont vous disposez (ou non) pour valider les données mises à jour et les messages sortants dans une transaction atomique. Si elle prend en charge les transactions multi-tables (bases relationnelles, DynamoDB, etc.), vous pouvez persister les messages dans une table dédiée, généralement appelée outbox. Sinon, l'état mis à jour et les messages doivent être persistés dans un même enregistrement.
Ensuite, il vous faut un moyen fiable de récupérer les messages persistés. Certaines bases de données offrent un modèle push : la base elle-même dispose de mécanismes pour appeler le relais de publication et lui transmettre les nouveaux messages. Par exemple, les triggers Lambda dans DynamoDB ou un mécanisme de change data capture (CDC) dans les bases relationnelles.
Enfin, la façon dont vous persistez et récupérez les messages détermine la manière dont vous garantirez qu'un même message ne sera pas repris et republié inutilement.
Mise en œuvre : exemple
Revenons à l'exemple initial. Puisque le code utilise DynamoDB, le moyen le plus simple d'implémenter le pattern outbox ici consiste à tirer parti de sa capacité à exécuter des transactions multi-tables et à ajouter les événements sortants dans une table dédiée :
...
with dynamodb.meta.client.transact_write_items(
TransactItems=[\
{\
'Put': {\
'TableName': users_table.name,\
'Item': {\
'user_id': user_id,\
'name': name,\
'password_hash': password_hash,\
'email': email,\
'source': source,\
'registration_date': registration_date,\
'created_at': datetime.utcnow().isoformat()\
}\
}\
},\
{\
'Put': {\
'TableName': outbox_table.name,\
'Item': {\
'event_id': event_id,\
'data': {\
'event_type': 'user_registered',\
'event_id': event_id,\
'user_id': user_id,\
'name': name,\
'email': email,\
'source': source,\
'registration_date': registration_date\
}\
}\
}\
}\
]
)
...
Reste à décider comment publier concrètement les événements sur le topic SNS. La solution la plus simple : activer DynamoDB Streams sur la table outbox pour déclencher une fonction Lambda à chaque nouvel enregistrement, et publier ses événements sur le topic SNS.
Enfin, vous devez décider du sort des messages déjà publiés. La fonction de publication peut supprimer les enregistrements de la table outbox dès qu'elle reçoit la confirmation que la publication sur SNS a réussi. Elle peut aussi conserver l'enregistrement et le mettre à jour avec l'horodatage de la publication effective.
La figure 2 résume la solution complète :
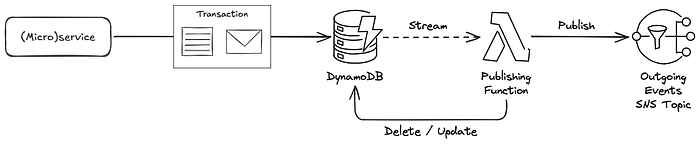
Figure 2 : le pattern outbox mis en œuvre avec AWS DynamoDB, Lambda et SNS
Face à la solution naïve qui se borne à publier les événements sortants sur un topic SNS, l'implémentation du pattern outbox donne un système plus complexe, comportant davantage de pièces mobiles. En contrepartie, la solution obtenue est fiable. Si la transaction d'origine a été validée, peu importe ce qui survient ensuite à l'exécution : les événements correspondants seront publiés et délivrés aux abonnés.
Articles de la série
- Event-Driven Architecture on AWS, Part I: The Basics
- Event-Driven Architecture on AWS, Part II: The Advanced Basics (article actuel)
- Event-Driven Architecture on AWS, Part III: The Hard Basics
Publié initialement sur https://vladikk.com .
La cohérence d'un système événementiel dépend de sa capacité à acheminer ses messages de façon fiable entre ses composants. Le pattern outbox permet de mettre à jour l'état du système et de publier les événements qui en résultent au sein d'une seule transaction atomique, même lorsque l'infrastructure sous-jacente ne prend pas en charge ce type de transactions inter-services. La fiabilité qu'il apporte au système l'emporte largement sur l'effort nécessaire à sa mise en œuvre.