Sta riscontrando velocità di trasferimento ridotte tra la sua VM GCE e un bucket Cloud Storage? Allora continui a leggere per scoprire come massimizzare il throughput in upload e download su VM Linux e Windows.
Panoramica
Di recente un cliente di DoiT International mi ha chiesto perché i dati presenti sull'SSD locale di un server Windows su Google Compute Engine (di seguito GCE) venivano caricati su un bucket Cloud Storage molto più lentamente del previsto. All'inizio ho pensato che sarebbe bastato un semplice benchmark dei comandi gsutil per dimostrare l'efficacia degli argomenti consigliati dalla documentazione GCP. Quella che doveva essere un'analisi 'rapida' si è invece trasformata in un'indagine a tutto campo sulle performance di trasferimento dati tra GCE e GCS, perché i primi risultati sono stati insoliti e del tutto inattesi.

Se le interessa solo sapere quali sono i metodi migliori per spostare dati tra GCE e GCS su una macchina Linux o Windows, scorra pure fino in fondo, alla sezione "Conclusioni sull'uso efficace degli strumenti di trasferimento".
Se invece vuole arrovellarsi sui valori di throughput bizzarri e spesso controintuitivi ottenibili con i comandi e gli argomenti più comuni, mi segua mentre entriamo nei dettagli che mi hanno portato alle articolate raccomandazioni finali di questo articolo.
Performance di una VM Linux con gsutil: file di grandi dimensioni
Anche se la richiesta del cliente riguardava il trasferimento dati su un server Windows, ho preferito iniziare il benchmark di base nell'ambiente in cui mi sento più a mio agio:
Linux, tramite l'immagine pubblica GCE "Debian GNU/Linux 10 (buster)".
Dato che il cliente stava già provando a trasferire file da SSD locali e volevo ridurre al minimo l'eventualità che i dischi di rete influissero sulle velocità, ho configurato due tagli di VM, n2-standard-4 e n2-standard-80, ciascuna con un SSD locale collegato su cui eseguire i benchmark.
Il bucket GCS che utilizzerò, così come tutte le VM descritte in questo articolo, sono creati come risorse regionali nella regione us-central1.
Per simulare l'esperienza di upload del cliente, ho creato un file vuoto da 30 GB:
fallocate -l 30G temp_30GB_file
A questo punto ho testato due parametri di gsutil tra i più consigliati:
-m: serve a eseguire copie parallele e multi-thread. Utile per trasferire un gran numero di file in parallelo, non per l'upload di singoli file.-o GSUtil:parallel_composite_upload_threshold=150M: serve a suddividere i file più grandi della soglia indicata in parti che vengono caricate in parallelo e ricomposte al termine dell'upload.
Le performance massime stimate per l'SSD locale su entrambe le VM sono le seguenti:
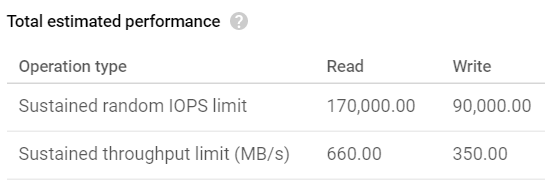
Limiti di throughput in lettura/scrittura dell'SSD locale
Dovremmo quindi poter raggiungere fino a 660 MB/s in lettura e 350 MB/s in scrittura con gsutil. Vediamo cosa hanno rivelato i benchmark di upload:
time gsutil cp temp_30GB_file gs://doit-speed-test-bucket/
# n2-standard-4: 2m21.893s, 216.50 MB/s
# n2-standard-80: 2m11.676s, 233.30 MB/stime gsutil -m cp temp_30GB_file gs://doit-speed-test-bucket/
# n2-standard-4: 2m48.710s, 182.09 MB/s
# n2-standard-80: 2m29.348s, 205.69 MB/stime gsutil -o GSUtil:parallel_composite_upload_threshold=150M cp temp_30GB_file gs://doit-speed-test-bucket/
# n2-standard-4: 1m40.104s, 306.88 MB/s
# n2-standard-80: 0m52.145s, 589.13 MB/stime gsutil -m -o GSUtil:parallel_composite_upload_threshold=150M cp temp_30GB_file gs://doit-speed-test-bucket/
# n2-standard-4: 1m44.579s, 293.75 MB/s
# n2-standard-80: 0m51.154s, 600.54 MB/s
Come previsto in base alla documentazione gsutil di GCP, l'upload di file di grandi dimensioni trae beneficio dall'inclusione di -o GSUtil. Quando sono disponibili più vCPU per supportare l'upload parallelo delle parti, il tempo di upload migliora drasticamente: con una velocità costante di 600 MB/s sulla n2-standard-80 ci avviciniamo al throughput massimo dell'SSD, pari a 660 MB/s. Aggiungere -m per un singolo file riduce il tempo di upload di pochi secondi. Fin qui niente di anomalo.
Diamo un'occhiata ai benchmark di download:
time gsutil cp gs://doit-speed-test-bucket/temp_30GB_file .
# n2-standard-4: 8m3.186s, 63.58 MB/s
# n2-standard-80: 6m13.585, 82.23 MB/stime gsutil -m cp gs://doit-speed-test-bucket/temp_30GB_file .
# n2-standard-4: 7m57.881s, 64.28 MB/s
# n2-standard-80: 6m20.131s, 80.81 MB/s

Un attimo, fermi tutti
Le performance di download sulla VM con 80 vCPU hanno raggiunto solo il 23% del throughput massimo in scrittura dell'SSD locale. Inoltre, nonostante l'attivazione del multi-threading con -m non porti benefici al download di un singolo file, e nonostante entrambe le macchine restino ben al di sotto del proprio throughput massimo (10 Gbps per la n2-standard-4, 32 Gbps per la n2-standard-80), risulta evidente che usare una macchina di fascia superiore all'interno della stessa famiglia porta a un miglioramento di circa il 30% nella velocità di download. Strano, ma non quanto ottenere appena 1/4 del throughput in scrittura dell'SSD locale con una VM dal costo esorbitante.
Cosa sta succedendo?
Dopo molte ricerche sul tema non ho trovato risposte, ma ho scoperto s5cmd, uno strumento progettato per migliorare drasticamente upload e download dai bucket S3. Dichiara di essere 12 volte più veloce dei comandi AWS CLI equivalenti (es. aws s3 cp), in larga parte perché è scritto in Go, un linguaggio compilato, mentre AWS CLI è scritta in Python. Si dà il caso che anche gsutil sia scritto in Python. Forse gsutil è gravemente penalizzato dalla scelta del linguaggio, o semplicemente ottimizzato male? Dato che i bucket GCS si possono configurare con interoperabilità API S3, è possibile velocizzare upload e download con s5cmd semplicemente passando a uno strumento compilato?
Performance di una VM Linux con s5cmd: file di grandi dimensioni
Far funzionare s5cmd ha richiesto un po' di tempo, soprattutto perché ho dovuto scoprire a mie spese che l'interoperabilità GCS non supporta l'API di multipart upload di S3 e, dato che questo strumento è pensato esclusivamente per AWS, fallisce sugli upload di file di grandi dimensioni in GCP. Bisogna passare -p=1000000, un argomento che forza l'esclusione del multi-part upload. Per maggiori informazioni veda le issue di s5cmd #1 e #2.
Si noti che s5cmd offre anche un parametro -c per impostare il numero di parti/file trasferiti in concorrenza, con valore predefinito pari a 5.
Tenendo a mente questi due argomenti, ho eseguito i seguenti benchmark di upload su Linux:
time s5cmd --endpoint-url https://storage.googleapis.com cp -c=1 -p=1000000 temp_30GB_file s3://doit-speed-test-bucket/
# n2-standard-4: 6m7.459s, 83.60 MB/s
# n2-standard-80: 6m50.272s, 74.88 MB/stime s5cmd --endpoint-url https://storage.googleapis.com cp -p=1000000 temp_30GB_file s3://doit-speed-test-bucket/
# n2-standard-4: 7m18.682s, 70.03 MB/s
# n2-standard-80: 6m48.380s, 75.22 MB/s
Come previsto, gli upload di file di grandi dimensioni vanno decisamente peggio rispetto a gsutil, vista l'assenza dell'opzione di multi-part upload. Vediamo upload tra 75 e 85 MB/s contro i 200–600 MB/s di gsutil. Impostare la concorrenza a 1 anziché al valore predefinito 5 ha un impatto solo marginale sulle performance. In sostanza, dato che s5cmd tratta AWS come cittadino di prima classe trascurando GCP, non possiamo migliorare gli upload affidandoci a s5cmd.
Ecco i benchmark di download di s5cmd:
time s5cmd --endpoint-url https://storage.googleapis.com cp -c=1 -p=1000000 s3://doit-speed-test-bucket/temp_30GB_file .
# n2-standard-4: 1m56.170s, 264.44 MB/s
# n2-standard-80: 1m46.196s, 289.28 MB/stime s5cmd --endpoint-url https://storage.googleapis.com cp -c=1 s3://doit-speed-test-bucket/temp_30GB_file .
# n2-standard-4: 3m21.380s, 152.55 MB/s
# n2-standard-80: 3m45.414s, 136.28 MB/stime s5cmd --endpoint-url https://storage.googleapis.com cp -p=1000000 s3://doit-speed-test-bucket/temp_30GB_file .
# n2-standard-4: 2m33.148s, 200.59 MB/s
# n2-standard-80: 2m48.071s, 182.78 MB/stime s5cmd --endpoint-url https://storage.googleapis.com cp s3://doit-speed-test-bucket/temp_30GB_file .
# n2-standard-4: 1m46.378s, 288.78 MB/s
# n2-standard-80: 2m1.116s, 253.64 MB/s
Che salto di qualità! Sebbene ci sia una certa variabilità nei tempi di download, sembra che, omettendo -c e -p e lasciandoli ai valori predefiniti, si ottenga la velocità migliore. Non riusciamo a raggiungere il throughput massimo in scrittura di 350 MB/s, ma circa 289 MB/s su una n2-standard-4 sono molto più vicini a quel valore rispetto ai circa 64 MB/s di gsutil sulla stessa macchina. Si tratta di un aumento di 4,5 volte nella velocità di download semplicemente cambiando lo strumento di trasferimento.
Riassumendo quanto emerso, per Linux:
- Dato che
s5cmdnon supporta il multi-part upload con GCS, ha senso continuare a usaregsutilper gli upload verso GCS, a patto di includere-o GSUtil:parallel_composite_upload_threshold=150M. s5cmdcon i parametri predefiniti straccianogsutilnelle performance di download. Basta usare uno strumento di trasferimento dati scritto in un linguaggio compilato per ottenere miglioramenti drastici (4,5 volte) delle performance.
Performance di una VM Windows con gsutil: file di grandi dimensioni
Se quanto visto non le sembrava già abbastanza strano, si allacci la cintura: stiamo per tuffarci in Windows. Dopotutto, dato che il cliente DoiT lavorava con Windows Server, era arrivato il momento di passare al benchmark su quel sistema operativo. Iniziavo a sospettare che il problema non fosse tra la tastiera e la sedia.
Dopo aver confermato che, su Linux, gsutil funziona alla grande in upload con i parametri giusti e s5cmd funziona alla grande in download con i parametri predefiniti, era ora di provare questi comandi su Windows, dove ancora una volta avrei toccato con mano i limiti della mia esperienza con Powershell.
Alla fine sono riuscito a raccogliere i benchmark da una macchina n2-standard-4 con un SSD locale collegato, in esecuzione sull'immagine VM GCE "Windows Server version 1809 Datacenter Core for Containers, built on 20200813". Vista la tariffazione di licenza per vCPU di Windows Server, ho preferito non raccogliere metriche da una n2-standard-80 in questo esperimento.
Una nota importante prima di entrare nelle metriche:
La documentazione GCP sul collegamento di SSD locali raccomanda che per "Tutti i Windows Server" si utilizzi il driver SCSI per collegare l'SSD locale anziché il driver NVMe normalmente usato su una macchina Linux, in quanto SCSI è meglio ottimizzato per il throughput massimo. Ho quindi creato due VM con un SSD locale collegato, una via NVMe e una via SCSI, con l'obiettivo di confrontarne le performance affiancandole ai vari strumenti e parametri esaminati finora.
Ecco i benchmark sulla velocità di upload:
Measure-Command {gsutil cp temp_30GB_file gs://doit-speed-test-bucket/}
# NVMe: 3m50.064s, 133.53 MB/s
# SCSI: 4m7.256s, 124.24 MB/sMeasure-Command {gsutil -m cp temp_30GB_file gs://doit-speed-test-bucket/}
# NVMe: 3m59.462s, 128.29 MB/s
# SCSI: 3m34.013s, 143.54 MB/sMeasure-Command {gsutil -o GSUtil:parallel_composite_upload_threshold=150M cp temp_30GB_file gs://doit-speed-test-bucket/}
# NVMe: 5m54.046s, 86.77 MB/s
# SCSI: 6m13.929s, 82.15 MB/sMeasure-Command {gsutil -m -o GSUtil:parallel_composite_upload_threshold=150M cp temp_30GB_file gs://doit-speed-test-bucket/}
# NVMe: 5m55.751s, 86.40 MB/s
# SCSI: 5m58.078s, 85.79 MB/s

Non ho parole per descrivere quello che provo in questo momento
Senza fornire alcun argomento a gsutil, il throughput in upload è circa il 60% di quello ottenuto su una macchina Linux. Qualsiasi combinazione di argomenti peggiora le performance. Quando si abilita il multi-part upload — che su Linux portava a un miglioramento del 42% nella velocità di upload — la velocità cala del 35%. Si noterà inoltre che, quando -m non viene fornito e gsutil può gestire in modo più efficiente un singolo file di grandi dimensioni, l'upload dal disco NVMe si completa più rapidamente rispetto al disco SCSI, quest'ultimo presumibilmente dotato di driver più ottimizzati per i Windows Server. Ma cosa sta succedendo?!
Le basse performance in upload, intorno a 80–85 MB/s, ricadevano esattamente nell'intervallo che il cliente DoiT stava sperimentando, quindi il problema era almeno riproducibile. Rimuovendo l'argomento -o GSUtil:parallel_composite_upload_threshold=150M consigliato da GCP per gli upload di file di grandi dimensioni, il cliente poteva eliminare una penalizzazione delle performance del 35%. 🤷
Il benchmark dei download racconta una storia ancora più amara:
Measure-Command {gsutil cp gs://doit-speed-test-bucket/temp_30GB_file .}
# NVMe 1st attempt: 11m39.426s, 43.92 MB/s
# NVMe 2nd attempt: 9m1.857s, 56.69 MB/s
# SCSI 1st attempt: 8m54.462s, 57.48 MB/s
# SCSI 2nd attempt: 10m1.023s, 51.05 MB/sMeasure-Command {gsutil -m cp gs://doit-speed-test-bucket/temp_30GB_file .}
# NVMe 1st attempt: 8m52.537s, 57.69 MB/s
# NVMe 2nd attempt: 22m4.824s, 23.19 MB/s
# NVMe 3rd attempt: 8m50.202s, 57.94 MB/s
# SCSI 1st attempt: 7m29.502s, 68.34 MB/s
# SCSI 2nd attempt: 9m9.652s, 55.89 MB/s
Non sono riuscito a ottenere benchmark di download coerenti per via di questo problema:
- Ogni operazione di download restava in attesa fino a 2 minuti prima di partire
- Il download partiva e procedeva a circa 68–70 MB/s, finché…
- A volte si fermava di nuovo per un tempo indeterminato
Il continuo alternarsi di blocchi e ripartenze faceva sì che la velocità media di download sulla stessa VM e sullo stesso disco oscillasse tra 23 MB/s e 58 MB/s. Era una follia cercare di stabilire se NVMe o SCSI fossero più adatti ai download con questi blocchi prolungati e casuali. Su questa conclusione torneremo più avanti.
Performance di una VM Windows con s5cmd: file di grandi dimensioni
Esasperato dalle performance di download di gsutil, irregolari e bizzarre, sono passato rapidamente a s5cmd: chissà che non riuscisse a risolvere o ridurre l'impatto dei blocchi.
Vediamo prima i benchmark di upload con s5cmd:
Measure-Command {s5cmd --endpoint-url https://storage.googleapis.com cp -c=1 -p=1000000 temp_30GB_file s3://doit-speed-test-bucket/}
# NVMe: 6m21.780s, 80.46 MB/s
# SCSI: 7m14.162s, 70.76 MB/sMeasure-Command {s5cmd --endpoint-url https://storage.googleapis.com cp -p=1000000 temp_30GB_file s3://doit-speed-test-bucket/}
# NVMe: 12m56.066s, 39.58 MB/s
# SCSI: 8m12.255s, 62.41 MB/s
Come per l'upload con s5cmd su Linux, l'impossibilità di utilizzare il multi-part upload è un freno. Le performance di upload con concorrenza impostata a 1 sono paragonabili a quelle ottenute dallo stesso strumento su una macchina Linux, ma con la concorrenza al valore predefinito di 5 si registrano cali (e oscillazioni) drastici. La portata dell'impatto della concorrenza è anomala, ma poiché le performance di upload di s5cmd rimangono nettamente peggiori di quelle di gsutil (il che è strano, dato che ciò vale anche quando entrambi non utilizzano il multi-part upload), in ogni caso non vogliamo usare s5cmd per gli upload; possiamo quindi tranquillamente ignorare l'anomalia di concorrenza in upload di s5cmd.
Passiamo ai benchmark di download con s5cmd:
Measure-Command {s5cmd --endpoint-url https://storage.googleapis.com cp -c=1 -p=1000000 s3://doit-speed-test-bucket/temp_30GB_file .}
# NVMe 1st attempt: 2m17.954s, 222.68 MB/s
# NVMe 2nd attempt: 1m44.718s, 293.36 MB/s
# SCSI 1st attempt: 3m9.581s, 162.04 MB/s
# SCSI 2nd attempt: 1m52.500s, 273.07 MB/sMeasure-Command {s5cmd --endpoint-url https://storage.googleapis.com cp -c=1 s3://doit-speed-test-bucket/temp_30GB_file .}
# NVMe 1st attempt: 3m18.006s, 155.15 MB/s
# NVMe 2nd attempt: 4m2.792s, 126.53 MB/s
# SCSI 1st attempt: 3m37.126s, 141.48 MB/s
# SCSI 2nd attempt: 4m9.657s, 123.05 MB/sMeasure-Command {s5cmd --endpoint-url https://storage.googleapis.com cp -p=1000000 s3://doit-speed-test-bucket/temp_30GB_file .}
# NVMe 1st attempt: 2m17.151s, 223.99 MB/s
# NVMe 2nd attempt: 1m47.217s, 286.52 MB/s
# SCSI 1st attempt: 4m39.120s, 110.06 MB/s
# SCSI 2nd attempt: 1m42.159s, 300.71 MB/sMeasure-Command {s5cmd --endpoint-url https://storage.googleapis.com cp s3://doit-speed-test-bucket/temp_30GB_file .}
# NVMe 1st attempt: 2m48.714s, 182.08 MB/s
# NVMe 2nd attempt: 2m41.174s, 190.60 MB/s
# SCSI 1st attempt: 2m35.480s, 197.58 MB/s
# SCSI 2nd attempt: 2m40.483s, 191.42 MB/s
Pur con qualche blocco e una certa variabilità nei download, come accadeva con gsutil, anche qui s5cmd si conferma molto più performante di gsutil in download. Inoltre i blocchi sono di durata inferiore e/o meno frequenti. Resta comunque il fatto che questi strani blocchi compaiono ancora di tanto in tanto.
A differenza di quanto fatto sulla VM Linux, dove ho ottenuto le massime performance omettendo i parametri -c e -p, qui la configurazione ottimale sembra includerli entrambi con -c=1 -p=1000000. È difficile dichiararla la più ottimale in assoluto, dati i blocchi casuali che hanno minato i miei benchmark, ma con questi argomenti il comportamento è sufficientemente buono. Come per gsutil, anche qui è arduo stabilire se NVMe o SCSI siano più ottimizzati, proprio a causa dei blocchi.
Per cercare di capire meglio le velocità di download su NVMe e SCSI con argomenti s5cmd ottimali, ho scritto una funzione che riporta runtime medio, minimo e massimo su 20 download ripetuti, con l'obiettivo di mediare i blocchi momentanei:
Measure-CommandAvg {s5cmd --endpoint-url https://storage.googleapis.com cp -c=1 -p=1000000 s3://doit-speed-test-bucket/temp_30GB_file .}
### With 20 sample downloads
# NVMe:
# Avg: 1m48.014s, 284.41 MB/s
# Min: 1m23.411s, 368.30 MB/s
# Max: 3m10.989s, 160.85 MB/s
# SCSI:
# Avg: 1m47.737s, 285.14 MB/s
# Min: 1m24.784s, 362.33 MB/s
# Max: 4m44.807s, 107.86 MB/s
Permane una certa variabilità nel tempo richiesto per completare lo stesso download, ma è evidente che SCSI non offre alcun vantaggio rispetto a NVMe per i download di file di grandi dimensioni, nonostante sia presumibilmente il driver ideale da utilizzare con un SSD locale su una VM Windows.
Verifichiamo ora se gli upload sono più performanti via NVMe usando la stessa funzione di media su 20 upload ripetuti:
Measure-CommandAvg {gsutil cp temp_30GB_file gs://doit-speed-test-bucket/}
# NVMe:
# Avg: 3m23.216s, 151.17 MB/s
# Min: 2m31.169s, 203.22 MB/s
# Max: 4m13.943s, 121.42 MB/s
# SCSI:
# Avg: 5m1.570s, 101.87 MB/s
# Min: 3m2.649s, 168.19 MB/s
# Max: 35m3.276s, 14.61 MB/s
Le esecuzioni singole precedenti, che indicavano NVMe come potenzialmente più performante di SCSI per gli upload, vengono confermate. In questo caso di esecuzione ripetuta su venti campioni, NVMe risulta nettamente più performante.
Pertanto, con le VM Windows, contrariamente a quanto indicato dalla documentazione GCP, non solo dovremmo evitare di usare -o GSUtil:parallel_composite_upload_threshold=150M con gsutil negli upload verso GCS, ma dovremmo anche evitare SCSI e preferire NVMe come driver dell'SSD locale, per migliorare gli upload e forse anche i download. Vediamo inoltre che, sia per i download sia per gli upload, ci sono pause frequenti e imprevedibili che vanno da 1–2 minuti fino a 10–30 minuti.
Cosa dico al cliente…
A questo punto ho informato il cliente che esistono limiti intrinseci al trasferimento dati quando si utilizza una VM Windows, ma che potevano essere parzialmente mitigati:
- Lasciando gli argomenti opzionali ai loro valori predefiniti negli upload di file di grandi dimensioni con
gsutil cp, nonostante la documentazione GCP suggerisca il contrario - Utilizzando
s5cmd -c=1 -p=1000000al posto digsutilper i download - Utilizzando il driver NVMe al posto di SCSI per lo storage SSD locale, per migliorare le velocità di upload e, possibilmente, anche quelle di download, nonostante la documentazione GCP suggerisca il contrario
Ho però anche detto al cliente che upload e download sarebbero migliorati drasticamente aggirando del tutto i blocchi tipici di Windows: spostare i dati su una macchina Linux tramite snapshot del disco, e poi eseguire le operazioni di sincronizzazione con GCS da un disco collegato a Linux. Si è rivelata la via più rapida per ottenere il throughput atteso tra una VM GCE e GCS, e ha portato a un cliente soddisfatto, anche se rimasto frustrato dai problemi di performance senza senso del suo Windows Server.
La conclusione che ho tratto dall'esperienza è questa: non solo gsutil è tristemente poco ottimizzato per le operazioni su server Windows, ma sembra esserci anche un problema di fondo nella capacità di GCS di trasferire dati da e verso Windows, dato che ritardi e blocchi si manifestano sia in gsutil sia in s5cmd per le operazioni di download e upload.
Il problema del cliente era risolto… eppure la mia curiosità non era ancora soddisfatta. Quale furto di banda avrei scoperto provando a trasferire un gran numero di file piccoli al posto di pochi file di grandi dimensioni?
Performance di una VM Linux con gsutil: file piccoli
Tornando a Linux, ho suddiviso il file da 30 GB in 50K (per la precisione 50.001) file:
mkdir parts
split -b 644245 temp_30GB_file
mv x* parts/
E ho proseguito con il benchmark delle performance di upload con gsutil:
nohup bash -c 'time gsutil cp -r parts/* gs://doit-speed-test-bucket/smallparts/' &
# n2-standard-4: 71m30.420s, 7.16 MB/s
# n2-standard-80: 69m32.803s, 7.36 MB/snohup bash -c 'time gsutil -m cp -r parts/* gs://doit-speed-test-bucket/smallparts/' &
# n2-standard-4: 9m7.045s, 56.16 MB/s
# n2-standard-80: 3m41.081s, 138.95 MB/s
Come previsto, passare -m per attivare l'upload multi-thread parallelo dei file migliora drasticamente la velocità di upload: non provi a caricare una cartella di grandi dimensioni piena di file senza questo parametro. Più vCPU ha la sua macchina, più upload può effettuare in contemporanea.
Ecco i benchmark delle performance di download con gsutil:
nohup bash -c 'time gsutil cp -r gs://doit-speed-test-bucket/smallparts/ parts/' &
# n2-standard-4: 61m24.516s, 8.34 MB/s
# n2-standard-80: 56m54.841s, 9.00 MB/snohup bash -c 'time gsutil -m cp -r gs://doit-speed-test-bucket/smallparts/ parts/' &
# n2-standard-4: 7m42.249s, 66.46 MB/s
# n2-standard-80: 3m38.421s, 140.65 MB/s
Anche qui passare -m è obbligatorio: non provi a scaricare una cartella piena di file senza. Come per gli upload, le performance di gsutil migliorano con gli upload paralleli ottenuti grazie a -m e a un buon numero di vCPU disponibili.
Su Linux non ho riscontrato nulla di anomalo negli upload e nei download di massa di file piccoli con gsutil.
Performance di una VM Linux con s5cmd: file piccoli
Avendo già stabilito che s5cmd non andrebbe usato per gli upload di file su GCS, riporterò solo i benchmark di download su Linux:
nohup bash -c 'time s5cmd --endpoint-url https://storage.googleapis.com cp s3://doit-speed-test-bucket/smallparts/* parts/' &
# n2-standard-4: 1m19.531s, 386.26 MB/s
# n2-standard-80: 1m31.592s, 335.40 MB/snohup bash -c 'time s5cmd --endpoint-url https://storage.googleapis.com cp -c=80 s3://doit-speed-test-bucket/smallparts/* parts/' &
# n2-standard-80: 1m29.837s, 341.95 MB/s
Sulla macchina n2-standard-4 si registra un aumento di 6,9 volte nella velocità di download di massa di file piccoli rispetto a gsutil. Ha quindi senso usare s5cmd sia per scaricare molti file piccoli sia per scaricare file più grandi.
Su Linux non è stato osservato nulla di anomalo nei download di massa di file piccoli con s5cmd.
Performance di una VM Windows con s5cmd: file piccoli (e ulteriori test su file di grandi dimensioni)
Dato che s5cmd ha download nettamente più veloci di gsutil su qualsiasi sistema operativo, prenderò in considerazione solo s5cmd per i benchmark di download su Windows con file piccoli:
Measure-CommandAvg {s5cmd --endpoint-url https://storage.googleapis.com cp s3://doit-speed-test-bucket/smallparts/* parts/}
# NVMe:
# Avg: 2m39.540s, 192.55 MB/s
# Min: 2m35.323s, 197.78 MB/s
# Max: 2m44.260s, 187.02 MB/s
# SCSI:
# Avg: 2m45.431s, 185.70 MB/s
# Min: 2m40.785s, 191.06 MB/s
# Max: 2m50.930s, 179.72 MB/s
Vediamo che scaricare 50K file piccoli su una VM Windows dà risultati migliori e più prevedibili rispetto al download di file molto più grandi. NVMe supera SCSI solo di un soffio.
In questo scenario si nota una strana coerenza e l'assenza di lunghi blocchi nella sincronizzazione dei dati, a differenza dei comandi di copia di singoli file di grandi dimensioni visti prima. Solo per avere conferma che la tendenza al blocco sia più probabile con file di grandi dimensioni, ho eseguito la funzione di media su 20 download ripetuti del file da 30 GB:
Measure-CommandAvg {s5cmd --endpoint-url https://storage.googleapis.com cp -p=1000000 s3://doit-speed-test-bucket/temp_30GB_file .}
### With 20 sample downloads
# NVMe:
# Avg: 3m3.770s, 167.17 MB/s
# Min: 1m34.901s, 323.70 MB/s
# Max: 10m34.575s, 48.41 MB/s
# SCSI:
# Avg: 2m20.131s, 219.22 MB/s
# Min: 1m31.585s, 335.43 MB/s
# Max: 3m43.215s, 137.63 MB/s
Il tempo di download su Windows con NVMe varia da 1m37s a 10m35s, mentre con 50K file piccoli sullo stesso sistema operativo oscilla soltanto tra 2m35s e 2m44s. Sembra dunque esserci un problema specifico di Windows o GCS con i trasferimenti di file di grandi dimensioni su una VM Windows.
Si noti anche che il tempo medio di download su NVMe risulta circa il 73% più lungo (3m3s contro 1m46s) rispetto all'esecuzione di s5cmd su Linux.
Verrebbe da dire che, in base ai risultati sopra, SCSI possa essere più vantaggioso di NVMe per i download di massa di file piccoli, ma con i blocchi casuali nel processo di download che alterano la media, mantengo NVMe come driver preferito vista la sua comprovata efficacia nell'upload di massa di file piccoli (vedi sotto) e le performance sostanzialmente equivalenti nel download di file di grandi dimensioni mostrate prima.
Performance di una VM Windows con gsutil: file piccoli
Ecco le metriche per il caricamento di molti file piccoli da una VM Windows:
Measure-CommandAvg {gsutil -q -m cp -r parts gs://doit-speed-test-bucket/smallparts/}
# NVMe:
# Avg: 16m36.562s, 30.83 MB/s
# Min: 16m22.914s, 31.25 MB/s
# Max: 17m0.299s, 30.11 MB/s
# SCSI:
# Avg: 17m29.591s, 29.27 MB/s
# Min: 17m5.236s, 29.96 MB/s
# Max: 18m3.469s, 28.35 MB/s
NVMe supera SCSI e, ancora una volta, le velocità sono molto più basse rispetto a una macchina Linux. Su Linux gli upload di massa di file piccoli richiedono circa 9m7s, il che rende il tempo medio di upload Windows con NVMe di 16m36s circa l'82% più lento rispetto a Linux.
Riproducibilità dei benchmark
Se è interessato a eseguire i suoi benchmark per replicare quanto ho rilevato, di seguito trova gli script shell e Powershell che ho utilizzato, insieme ai commenti che riassumono il throughput osservato:
Conclusioni sull'uso efficace degli strumenti di trasferimento
Tutto sommato, c'è molta più complessità di quanta ce ne dovrebbe essere nel determinare il metodo migliore per trasferire dati tra VM GCE — con dati su un SSD locale — e GCS.

Le differenze di performance tra i vari sistemi operativi GCE e GCS sono in qualche modo tutte collegate, lo so e basta
I server Windows registrano riduzioni drastiche sia delle velocità di download sia di quelle di upload, per ragioni tuttora ignote, rispetto ai migliori comandi equivalenti su una macchina Linux. Si tratta di cali sostanziali, tipicamente del 70–80% rispetto al miglior comando equivalente su Linux. I trasferimenti di file di grandi dimensioni sono colpiti più pesantemente rispetto al trasferimento di molti file piccoli.
Pertanto, se ha bisogno di migrare TB di dati o file particolarmente grandi da Windows a GCS in tempi stretti, può aggirare questi problemi di performance creando uno snapshot del disco, collegando un disco creato da quello snapshot a una macchina Linux e caricando i dati tramite quel sistema operativo.
Indipendentemente dai problemi dei server Windows, lo strumento di trasferimento dati predefinito gsutil disponibile sulle VM GCE è inadeguato per download ad alto throughput su qualsiasi sistema operativo. Passando a s5cmd può ottenere miglioramenti di diverse volte nella velocità di download.
Per aiutarla a districarsi tra la miriade di strumenti e argomenti possibili, di seguito trova un riepilogo delle mie raccomandazioni per massimizzare il throughput sulla base dei benchmark presentati in questo articolo:
Linux — Download
- Singolo file di grandi dimensioni:
s5cmd --endpoint-url https://storage.googleapis.com cp s3://your_bucket/your_file . - File multipli, piccoli o grandi:
s5cmd --endpoint-url https://storage.googleapis.com cp s3://your_bucket/path* your_path/
Linux — Upload
- Singolo file di grandi dimensioni:
gsutil -o GSUtil:parallel_composite_upload_threshold=150M cp your_file gs://your_bucket/ - File multipli, piccoli o grandi:
gsutil -m -o GSUtil:parallel_composite_upload_threshold=150M cp -r your_path/ gs://your_bucket/
Windows Server — Download
- Utilizzi NVMe, non SCSI, per collegare un SSD locale
- Singolo file di grandi dimensioni:
s5cmd --endpoint-url https://storage.googleapis.com cp -c=1 -p=1000000 s3://your_bucket/your_file . - File multipli, piccoli o grandi:
s5cmd --endpoint-url https://storage.googleapis.com cp s3://your_bucket/path* your_path/
Windows Server — Upload
- Utilizzi NVMe, non SCSI, per collegare un SSD locale
- Singolo file di grandi dimensioni:
gsutil cp your_file gs://your_bucket/ - File multipli, piccoli o grandi:
gsutil -m cp -r your_path/ gs://your_bucket/your_path/