Está com velocidades de transferência lentas entre sua VM do GCE e um bucket do Cloud Storage? Continue lendo e descubra como maximizar o throughput de upload e download em VMs Linux e Windows!
Visão geral
Recentemente, um cliente da DoiT International me perguntou por que os dados no SSD local de um Windows Server no Google Compute Engine (daqui em diante, GCE) estavam subindo para um bucket do Cloud Storage muito mais devagar do que o esperado. No começo, achei que bastaria um benchmark simples de comandos gsutil para mostrar a eficácia dos argumentos ideais recomendados pela documentação do GCP. Acabou que essa olhada "rápida" virou uma investigação completa sobre o desempenho de transferência de dados entre GCE e GCS, porque as descobertas iniciais foram fora do comum e bem inesperadas.

Se você só quer saber quais são os métodos ideais para mover dados entre GCE e GCS em uma máquina Linux ou Windows, vá direto até "Conclusões sobre o uso eficaz das ferramentas de transferência".
Mas se quiser quebrar a cabeça com as taxas de throughput bizarras e muitas vezes contraintuitivas que aparecem com comandos e argumentos comuns, vem comigo enquanto entramos nos detalhes que levaram ao resumo de recomendações no fim deste artigo.
Desempenho da VM Linux com gsutil: arquivos grandes
Apesar de a demanda do cliente envolver transferência de dados em um Windows Server, comecei o benchmark básico onde me sinto mais à vontade:
Linux, usando a imagem pública "Debian GNU/Linux 10 (buster)" do GCE.
Como o cliente já estava tentando transferir arquivos a partir de SSDs locais, e eu queria reduzir ao máximo a chance de discos em rede afetarem as velocidades, configurei duas VMs, uma n2-standard-4 e uma n2-standard-80, cada uma com um SSD local anexado para rodar o benchmark.
O bucket do GCS que vou usar, assim como todas as VMs descritas neste artigo, foi criado como recurso regional em us-central1.
Para simular o upload de arquivos grandes feito pelo cliente, criei um arquivo vazio de 30 GB:
fallocate -l 30G temp_30GB_file
A partir daí, testei dois parâmetros do gsutil bastante recomendados:
-m: faz a cópia paralela e multithread. Útil para transferir vários arquivos em paralelo, não para o upload de arquivos individuais.-o GSUtil:parallel_composite_upload_threshold=150M: divide arquivos grandes que ultrapassam o limite especificado em partes que sobem em paralelo e são recombinadas depois que todas as partes terminam o upload.
O desempenho máximo estimado para o SSD local nas duas VMs é o seguinte:
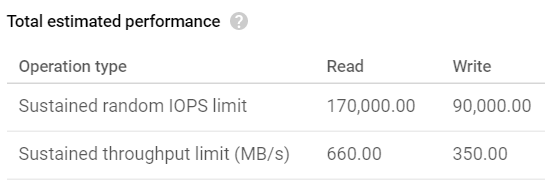
Limites de throughput de leitura/escrita do SSD local
Portanto, deveríamos conseguir até 660 MB/s de leitura e 350 MB/s de escrita com o gsutil. Vamos ver o que os benchmarks de upload mostraram:
time gsutil cp temp_30GB_file gs://doit-speed-test-bucket/
# n2-standard-4: 2m21.893s, 216.50 MB/s
# n2-standard-80: 2m11.676s, 233.30 MB/stime gsutil -m cp temp_30GB_file gs://doit-speed-test-bucket/
# n2-standard-4: 2m48.710s, 182.09 MB/s
# n2-standard-80: 2m29.348s, 205.69 MB/stime gsutil -o GSUtil:parallel_composite_upload_threshold=150M cp temp_30GB_file gs://doit-speed-test-bucket/
# n2-standard-4: 1m40.104s, 306.88 MB/s
# n2-standard-80: 0m52.145s, 589.13 MB/stime gsutil -m -o GSUtil:parallel_composite_upload_threshold=150M cp temp_30GB_file gs://doit-speed-test-bucket/
# n2-standard-4: 1m44.579s, 293.75 MB/s
# n2-standard-80: 0m51.154s, 600.54 MB/s
Como a documentação do gsutil do GCP indica, uploads de arquivos grandes ganham bastante ao incluir -o GSUtil. Quando há mais vCPUs disponíveis para auxiliar no upload paralelo das partes do arquivo, o tempo cai drasticamente: na n2-standard-80, com upload constante de 600 MB/s, chegamos perto do throughput máximo de 660 MB/s do SSD. Incluir -m para um único arquivo reduz o tempo em poucos segundos. Até aqui, nada fora do comum.
Vamos aos benchmarks de download:
time gsutil cp gs://doit-speed-test-bucket/temp_30GB_file .
# n2-standard-4: 8m3.186s, 63.58 MB/s
# n2-standard-80: 6m13.585, 82.23 MB/stime gsutil -m cp gs://doit-speed-test-bucket/temp_30GB_file .
# n2-standard-4: 7m57.881s, 64.28 MB/s
# n2-standard-80: 6m20.131s, 80.81 MB/s

Calma aí
O download na VM de 80 vCPUs alcançou só 23% do throughput máximo de escrita do SSD local. Além disso, mesmo com o multithreading via -m não melhorando o desempenho desse download de arquivo único, e mesmo com as duas máquinas operando bem abaixo do throughput máximo (10 Gbps na n2-standard-4 e 32 Gbps na n2-standard-80), aparentemente subir de tier dentro da mesma família melhora a velocidade de download em cerca de 30%. Estranho, mas não tão estranho quanto conseguir só 1/4 do throughput de escrita do SSD local com uma VM absurdamente cara.
O que está rolando aqui?
Depois de muita pesquisa sobre o assunto, não achei respostas, mas descobri o s5cmd, uma ferramenta feita para acelerar drasticamente uploads e downloads em buckets S3. Ela diz rodar 12X mais rápido que os comandos equivalentes do AWS CLI (por exemplo, aws s3 cp), em grande parte por ser escrita em Go, uma linguagem compilada, enquanto o AWS CLI é escrito em Python. Acontece que o gsutil também é escrito em Python. Será que o gsutil está seriamente prejudicado pela escolha da linguagem ou simplesmente mal otimizado? Já que buckets do GCS podem ser configurados com interoperabilidade da API do S3, dá para acelerar uploads e downloads com o s5cmd só por usar uma ferramenta compilada?
Desempenho da VM Linux com s5cmd: arquivos grandes
Levei um tempinho para colocar o s5cmd para funcionar, principalmente porque descobri na marra que a interoperabilidade do GCS não suporta a API de upload multipart do S3 e, como a ferramenta foi escrita pensando só na AWS, ela falha em uploads de arquivos grandes no GCP. É preciso passar -p=1000000, um argumento que força o upload a evitar o multipart. Veja as issues #1 e #2 do s5cmd para mais detalhes.
Vale notar que o s5cmd também tem o parâmetro -c, que define o número de partes/arquivos transferidos simultaneamente, com valor padrão 5.
Com esses dois argumentos em mente, rodei os seguintes benchmarks de upload no Linux:
time s5cmd --endpoint-url https://storage.googleapis.com cp -c=1 -p=1000000 temp_30GB_file s3://doit-speed-test-bucket/
# n2-standard-4: 6m7.459s, 83.60 MB/s
# n2-standard-80: 6m50.272s, 74.88 MB/stime s5cmd --endpoint-url https://storage.googleapis.com cp -p=1000000 temp_30GB_file s3://doit-speed-test-bucket/
# n2-standard-4: 7m18.682s, 70.03 MB/s
# n2-standard-80: 6m48.380s, 75.22 MB/s
Como esperado, uploads de arquivos grandes têm desempenho bem pior em comparação com o gsutil, já que não temos a opção de multipart upload. Vemos uploads de 75 a 85 MB/s contra os 200 a 600 MB/s do gsutil. Usar concorrência 1 em vez do padrão 5 tem impacto pequeno na melhoria. Ou seja, como o s5cmd trata a AWS como cidadão de primeira classe e não considera o GCP, não dá para acelerar uploads usando essa ferramenta.
Abaixo, os benchmarks de download do s5cmd:
time s5cmd --endpoint-url https://storage.googleapis.com cp -c=1 -p=1000000 s3://doit-speed-test-bucket/temp_30GB_file .
# n2-standard-4: 1m56.170s, 264.44 MB/s
# n2-standard-80: 1m46.196s, 289.28 MB/stime s5cmd --endpoint-url https://storage.googleapis.com cp -c=1 s3://doit-speed-test-bucket/temp_30GB_file .
# n2-standard-4: 3m21.380s, 152.55 MB/s
# n2-standard-80: 3m45.414s, 136.28 MB/stime s5cmd --endpoint-url https://storage.googleapis.com cp -p=1000000 s3://doit-speed-test-bucket/temp_30GB_file .
# n2-standard-4: 2m33.148s, 200.59 MB/s
# n2-standard-80: 2m48.071s, 182.78 MB/stime s5cmd --endpoint-url https://storage.googleapis.com cp s3://doit-speed-test-bucket/temp_30GB_file .
# n2-standard-4: 1m46.378s, 288.78 MB/s
# n2-standard-80: 2m1.116s, 253.64 MB/s
Que melhora absurda! Apesar de alguma variação no tempo de download, parece que deixar -c e -p de fora, mantendo os padrões, é o caminho para a velocidade ideal. Não conseguimos chegar ao throughput máximo de escrita de 350 MB/s, mas cerca de 289 MB/s em uma n2-standard-4 está muito mais perto disso do que os ~64 MB/s entregues pelo gsutil na mesma máquina. Ou seja, 4,5X mais rápido só pela troca da ferramenta de transferência.
Resumindo as descobertas acima para o Linux:
- Como o
s5cmdnão consegue usar multipart upload no GCS, faz sentido manter ogsutilpara upload, desde que você inclua-o GSUtil:parallel_composite_upload_threshold=150M. - O
s5cmdcom os parâmetros padrão dá um banho nogsutilem desempenho de download. Só de usar uma ferramenta de transferência escrita em linguagem compilada já se obtêm melhorias dramáticas (4,5X) de desempenho.
Desempenho da VM Windows com gsutil: arquivos grandes
Se você achou que o que vimos acima já era estranho, segura que vamos ao nível extremo com o Windows. Como o cliente da DoiT estava lidando com Windows Server, era hora de fazer o benchmark desse SO. Comecei a desconfiar que o problema dele não estava entre o teclado e a cadeira.
Confirmado que, no Linux, o gsutil manda muito bem no upload com os parâmetros certos e o s5cmd manda muito bem no download com os parâmetros padrão, era hora de testar esses comandos no Windows, onde mais uma vez ia me sentir humilde diante da minha pouca experiência com PowerShell.
Acabei conseguindo coletar benchmarks em uma máquina n2-standard-4 com SSD local anexado, rodando a imagem de VM "Windows Server version 1809 Datacenter Core for Containers, built on 20200813" do GCE. Por causa das taxas de licenciamento por vCPU cobradas pelo Windows Server, optei por não coletar métricas em uma n2-standard-80 neste experimento.
Uma observação importante antes de irmos às métricas:
A documentação do GCP sobre como anexar SSDs locais recomenda que, para "todos os Windows Servers", você use o driver SCSI em vez do NVMe usado normalmente em uma máquina Linux, porque o SCSI estaria mais bem otimizado para alcançar o throughput máximo. Provisionei duas VMs com SSD local anexado, uma via NVMe e outra via SCSI, para comparar o desempenho com as várias ferramentas e parâmetros que vinha investigando.
Abaixo, os benchmarks de velocidade de upload:
Measure-Command {gsutil cp temp_30GB_file gs://doit-speed-test-bucket/}
# NVMe: 3m50.064s, 133.53 MB/s
# SCSI: 4m7.256s, 124.24 MB/sMeasure-Command {gsutil -m cp temp_30GB_file gs://doit-speed-test-bucket/}
# NVMe: 3m59.462s, 128.29 MB/s
# SCSI: 3m34.013s, 143.54 MB/sMeasure-Command {gsutil -o GSUtil:parallel_composite_upload_threshold=150M cp temp_30GB_file gs://doit-speed-test-bucket/}
# NVMe: 5m54.046s, 86.77 MB/s
# SCSI: 6m13.929s, 82.15 MB/sMeasure-Command {gsutil -m -o GSUtil:parallel_composite_upload_threshold=150M cp temp_30GB_file gs://doit-speed-test-bucket/}
# NVMe: 5m55.751s, 86.40 MB/s
# SCSI: 5m58.078s, 85.79 MB/s

Não tem palavras pra descrever o que estou sentindo agora
Sem nenhum argumento passado para o gsutil, o throughput de upload fica em torno de 60% do alcançado em uma máquina Linux. Qualquer combinação de argumentos piora o desempenho. Quando o multipart upload é habilitado — o que rendeu 42% de melhora no Linux — a velocidade de upload cai 35%. Você também pode notar que, quando -m não é fornecido e o gsutil faz upload de forma mais otimizada para um único arquivo grande, o upload pelo drive NVMe termina antes do que pelo SCSI — sendo que esse último, em tese, tem drivers mais otimizados para Windows Servers. O que está acontecendo aqui?!
O baixo desempenho de upload em torno de 80–85 MB/s era exatamente a faixa que o cliente da DoiT estava vendo, ou seja, o problema dele era pelo menos reproduzível. Ao remover o argumento recomendado pelo GCP
-o GSUtil:parallel_composite_upload_threshold=150M em uploads de arquivos grandes, o cliente eliminaria uma penalidade de desempenho de 35%. 🤷
Os benchmarks de download contam uma história ainda mais perturbadora:
Measure-Command {gsutil cp gs://doit-speed-test-bucket/temp_30GB_file .}
# NVMe 1st attempt: 11m39.426s, 43.92 MB/s
# NVMe 2nd attempt: 9m1.857s, 56.69 MB/s
# SCSI 1st attempt: 8m54.462s, 57.48 MB/s
# SCSI 2nd attempt: 10m1.023s, 51.05 MB/sMeasure-Command {gsutil -m cp gs://doit-speed-test-bucket/temp_30GB_file .}
# NVMe 1st attempt: 8m52.537s, 57.69 MB/s
# NVMe 2nd attempt: 22m4.824s, 23.19 MB/s
# NVMe 3rd attempt: 8m50.202s, 57.94 MB/s
# SCSI 1st attempt: 7m29.502s, 68.34 MB/s
# SCSI 2nd attempt: 9m9.652s, 55.89 MB/s
Não consegui obter benchmarks de download consistentes por causa do seguinte:
- Cada operação de download travava por até 2 minutos antes de começar
- O download iniciava e avançava a cerca de 68–70 MB/s, até que…
- Às vezes pausava de novo por um tempo indeterminado
Essa dinâmica de travar e retomar o download fazia com que a média de velocidade na mesma VM e mesmo disco variasse de 23 MB/s a 58 MB/s. Foi uma loucura tentar dizer se NVMe ou SCSI seria melhor para downloads com esses travamentos longos e aleatórios. Mais sobre esse veredito daqui a pouco.
Desempenho da VM Windows com s5cmd: arquivos grandes
Frustrado com o desempenho doido e imprevisível do gsutil em download, parti rapidamente para o s5cmd — quem sabe ele não resolveria, ou pelo menos reduziria, os travamentos?
Vamos primeiro aos benchmarks de upload do s5cmd:
Measure-Command {s5cmd --endpoint-url https://storage.googleapis.com cp -c=1 -p=1000000 temp_30GB_file s3://doit-speed-test-bucket/}
# NVMe: 6m21.780s, 80.46 MB/s
# SCSI: 7m14.162s, 70.76 MB/sMeasure-Command {s5cmd --endpoint-url https://storage.googleapis.com cp -p=1000000 temp_30GB_file s3://doit-speed-test-bucket/}
# NVMe: 12m56.066s, 39.58 MB/s
# SCSI: 8m12.255s, 62.41 MB/s
Igual ao upload do s5cmd no Linux, ele é prejudicado por não conseguir usar multipart upload. Com concorrência definida em 1, o desempenho é parecido com o da mesma ferramenta no Linux, mas com a concorrência no padrão 5 surgem quedas (e oscilações) drásticas. A severidade do impacto da concorrência aqui é fora do comum, mas como o desempenho de upload do s5cmd continua sendo bem pior que o do gsutil (estranho, considerando que isso vale mesmo quando os dois não usam multipart upload), de qualquer modo não vamos usar o s5cmd para uploads — então dá para ignorar essa esquisitice da concorrência.
Vamos aos benchmarks de download do s5cmd:
Measure-Command {s5cmd --endpoint-url https://storage.googleapis.com cp -c=1 -p=1000000 s3://doit-speed-test-bucket/temp_30GB_file .}
# NVMe 1st attempt: 2m17.954s, 222.68 MB/s
# NVMe 2nd attempt: 1m44.718s, 293.36 MB/s
# SCSI 1st attempt: 3m9.581s, 162.04 MB/s
# SCSI 2nd attempt: 1m52.500s, 273.07 MB/sMeasure-Command {s5cmd --endpoint-url https://storage.googleapis.com cp -c=1 s3://doit-speed-test-bucket/temp_30GB_file .}
# NVMe 1st attempt: 3m18.006s, 155.15 MB/s
# NVMe 2nd attempt: 4m2.792s, 126.53 MB/s
# SCSI 1st attempt: 3m37.126s, 141.48 MB/s
# SCSI 2nd attempt: 4m9.657s, 123.05 MB/sMeasure-Command {s5cmd --endpoint-url https://storage.googleapis.com cp -p=1000000 s3://doit-speed-test-bucket/temp_30GB_file .}
# NVMe 1st attempt: 2m17.151s, 223.99 MB/s
# NVMe 2nd attempt: 1m47.217s, 286.52 MB/s
# SCSI 1st attempt: 4m39.120s, 110.06 MB/s
# SCSI 2nd attempt: 1m42.159s, 300.71 MB/sMeasure-Command {s5cmd --endpoint-url https://storage.googleapis.com cp s3://doit-speed-test-bucket/temp_30GB_file .}
# NVMe 1st attempt: 2m48.714s, 182.08 MB/s
# NVMe 2nd attempt: 2m41.174s, 190.60 MB/s
# SCSI 1st attempt: 2m35.480s, 197.58 MB/s
# SCSI 2nd attempt: 2m40.483s, 191.42 MB/s
Mesmo com algumas pausas e variações nos downloads, como acontecia com o gsutil, o s5cmd de novo se mostra bem mais rápido em download. As pausas também foram mais curtas e/ou menos frequentes. Ainda assim, esses travamentos estranhos continuam aparecendo de vez em quando.
Ao contrário do que aconteceu na VM Linux, em que o melhor desempenho veio de deixar os parâmetros -c e -p de fora, aqui parece que o ideal foi incluir os dois com -c=1 -p=1000000. É difícil cravar essa configuração como a melhor por causa dos travamentos aleatórios que atrapalharam o benchmark, mas com esses argumentos a ferramenta roda razoavelmente bem. Como aconteceu com o gsutil, também é difícil definir se NVMe ou SCSI estão mais bem otimizados, justamente por causa dos travamentos.
Para entender melhor as velocidades de download em NVMe e SCSI com os argumentos ideais do s5cmd, escrevi uma função que reporta os tempos médio, mínimo e máximo a partir de 20 downloads repetidos, com a ideia de diluir o efeito das pausas momentâneas:
Measure-CommandAvg {s5cmd --endpoint-url https://storage.googleapis.com cp -c=1 -p=1000000 s3://doit-speed-test-bucket/temp_30GB_file .}
### With 20 sample downloads
# NVMe:
# Avg: 1m48.014s, 284.41 MB/s
# Min: 1m23.411s, 368.30 MB/s
# Max: 3m10.989s, 160.85 MB/s
# SCSI:
# Avg: 1m47.737s, 285.14 MB/s
# Min: 1m24.784s, 362.33 MB/s
# Max: 4m44.807s, 107.86 MB/s
A variação no tempo do mesmo download continua, mas fica claro que o SCSI não leva vantagem sobre o NVMe, no geral, em downloads de arquivos grandes — apesar de, em tese, ser o driver ideal para um SSD local em uma VM Windows.
Vamos validar também se os uploads são mais performáticos via NVMe, usando a mesma função de média sobre 20 uploads repetidos:
Measure-CommandAvg {gsutil cp temp_30GB_file gs://doit-speed-test-bucket/}
# NVMe:
# Avg: 3m23.216s, 151.17 MB/s
# Min: 2m31.169s, 203.22 MB/s
# Max: 4m13.943s, 121.42 MB/s
# SCSI:
# Avg: 5m1.570s, 101.87 MB/s
# Min: 3m2.649s, 168.19 MB/s
# Max: 35m3.276s, 14.61 MB/s
Aqui validamos as execuções individuais anteriores que apontavam o NVMe como possivelmente mais performático que o SCSI para uploads. Neste caso de vinte execuções repetidas, o NVMe é consideravelmente mais rápido.
Ou seja, em VMs Windows, e ao contrário do que diz a documentação do GCP, não só devemos evitar o uso de -o GSUtil:parallel_composite_upload_threshold=150M com o gsutil ao subir dados para o GCS, como também devemos preferir o NVMe ao SCSI como driver do SSD local para acelerar uploads e, talvez, downloads. Também observamos que, em downloads e uploads, há pausas frequentes e imprevisíveis que vão de 1–2 minutos a até 10–30 minutos.
O que dizer para o cliente…
Nesse ponto, expliquei ao cliente que existem limitações inerentes de transferência de dados ao usar uma VM Windows, mas que era possível mitigá-las em parte:
- Mantendo os argumentos opcionais nos seus padrões para uploads de arquivos grandes com
gsutil cp, apesar do que sugere a documentação do GCP - Usando
s5cmd -c=1 -p=1000000em vez degsutilpara downloads - Usando o driver NVMe em vez do SCSI no SSD local, para melhorar uploads e, possivelmente, downloads — apesar do que sugere a documentação do GCP
Por outro lado, também avisei o cliente que uploads e downloads ficariam drasticamente melhores ao evitar de vez os travamentos do Windows: mover os dados para uma máquina Linux via snapshots de disco e, depois, rodar as operações de sincronização com o GCS a partir de um disco anexado ao Linux. No fim, esse foi o caminho mais rápido para alcançar o throughput esperado entre uma VM do GCE e o GCS, e deixou o cliente satisfeito — embora ainda frustrado com problemas de desempenho sem sentido no Windows Server dele.
O que tirei dessa experiência foi o seguinte: o gsutil não só está terrivelmente pouco otimizado para operações em servidores Windows, como também parece existir um problema de fundo na capacidade do GCS de transferir dados de e para o Windows, já que tanto o gsutil quanto o s5cmd apresentam atrasos e travamentos em downloads e uploads.
O problema do cliente foi resolvido… mas minha curiosidade ainda não estava satisfeita. Que tipo de roubo de banda eu encontraria ao tentar transferir um grande número de arquivos pequenos em vez de um pequeno número de arquivos grandes?
Desempenho da VM Linux com gsutil: arquivos pequenos
Voltando ao Linux, dividi o arquivo grande de 30 GB em 50 mil (na verdade, 50.001) arquivos:
mkdir parts
split -b 644245 temp_30GB_file
mv x* parts/
E parti para o benchmark de upload com o gsutil:
nohup bash -c 'time gsutil cp -r parts/* gs://doit-speed-test-bucket/smallparts/' &
# n2-standard-4: 71m30.420s, 7.16 MB/s
# n2-standard-80: 69m32.803s, 7.36 MB/snohup bash -c 'time gsutil -m cp -r parts/* gs://doit-speed-test-bucket/smallparts/' &
# n2-standard-4: 9m7.045s, 56.16 MB/s
# n2-standard-80: 3m41.081s, 138.95 MB/s
Como esperado, passar -m para fazer o upload paralelo e multithread acelera muito a velocidade — não tente subir uma pasta grande de arquivos sem isso. Quanto mais vCPUs sua máquina tem, mais uploads simultâneos você consegue.
Abaixo, os benchmarks de download com o gsutil:
nohup bash -c 'time gsutil cp -r gs://doit-speed-test-bucket/smallparts/ parts/' &
# n2-standard-4: 61m24.516s, 8.34 MB/s
# n2-standard-80: 56m54.841s, 9.00 MB/snohup bash -c 'time gsutil -m cp -r gs://doit-speed-test-bucket/smallparts/ parts/' &
# n2-standard-4: 7m42.249s, 66.46 MB/s
# n2-standard-80: 3m38.421s, 140.65 MB/s
De novo, passar -m é obrigatório — não tente baixar uma pasta grande de arquivos sem isso. Como nos uploads, o desempenho do gsutil melhora com o paralelismo do -m e várias vCPUs disponíveis.
Não encontrei nada fora do comum no Linux com uploads e downloads em massa de arquivos pequenos via gsutil.
Desempenho da VM Linux com s5cmd: arquivos pequenos
Como já ficou claro que o s5cmd não deve ser usado para uploads ao GCS, vou reportar só os benchmarks de download no Linux abaixo:
nohup bash -c 'time s5cmd --endpoint-url https://storage.googleapis.com cp s3://doit-speed-test-bucket/smallparts/* parts/' &
# n2-standard-4: 1m19.531s, 386.26 MB/s
# n2-standard-80: 1m31.592s, 335.40 MB/snohup bash -c 'time s5cmd --endpoint-url https://storage.googleapis.com cp -c=80 s3://doit-speed-test-bucket/smallparts/* parts/' &
# n2-standard-80: 1m29.837s, 341.95 MB/s
Na máquina n2-standard-4, vemos um speedup de 6,9X na velocidade de download em massa de arquivos pequenos em comparação com o gsutil. Faz sentido, então, usar o s5cmd tanto para baixar muitos arquivos pequenos quanto para baixar arquivos maiores.
Nada fora do comum foi observado no Linux com downloads em massa de arquivos pequenos via s5cmd.
Desempenho da VM Windows com s5cmd: arquivos pequenos (e mais testes com arquivos grandes)
Já que o s5cmd tem downloads bem mais rápidos que o gsutil em qualquer SO, vou considerar só o s5cmd nos benchmarks de download no Windows com arquivos pequenos:
Measure-CommandAvg {s5cmd --endpoint-url https://storage.googleapis.com cp s3://doit-speed-test-bucket/smallparts/* parts/}
# NVMe:
# Avg: 2m39.540s, 192.55 MB/s
# Min: 2m35.323s, 197.78 MB/s
# Max: 2m44.260s, 187.02 MB/s
# SCSI:
# Avg: 2m45.431s, 185.70 MB/s
# Min: 2m40.785s, 191.06 MB/s
# Max: 2m50.930s, 179.72 MB/s
Vemos que baixar 50 mil arquivos menores para uma VM Windows tem desempenho melhor e mais previsível do que baixar arquivos muito maiores. O NVMe supera o SCSI por uma margem mínima.
Há uma consistência estranha e ausência de pausas longas nesse caso de sincronização de dados, em contraste com os comandos de cópia de arquivos grandes individuais vistos antes. Para confirmar que a tendência de travamento aparece mais em arquivos grandes, rodei a função de média sobre 20 downloads repetidos do arquivo de 30 GB:
Measure-CommandAvg {s5cmd --endpoint-url https://storage.googleapis.com cp -p=1000000 s3://doit-speed-test-bucket/temp_30GB_file .}
### With 20 sample downloads
# NVMe:
# Avg: 3m3.770s, 167.17 MB/s
# Min: 1m34.901s, 323.70 MB/s
# Max: 10m34.575s, 48.41 MB/s
# SCSI:
# Avg: 2m20.131s, 219.22 MB/s
# Min: 1m31.585s, 335.43 MB/s
# Max: 3m43.215s, 137.63 MB/s
Vemos que o tempo de download no Windows com NVMe varia de 1m37s a 10m35s, enquanto com 50 mil arquivos pequenos no mesmo SO o tempo ficou entre 2m35s e 2m44s. Ou seja, parece haver um problema específico do Windows ou do GCS em transferências de arquivos grandes em uma VM Windows.
Note também que o tempo médio de download via NVMe é cerca de 73% maior (3m3s vs. 1m46s) do que rodando o s5cmd no Linux.
É tentador dizer que o SCSI seria mais vantajoso para downloads em massa de arquivos pequenos do que o NVMe com base nos resultados acima, mas, com os travamentos aleatórios distorcendo a média, vou ficar com o NVMe como driver preferido, dada sua eficácia comprovada no upload em massa de arquivos pequenos (veja abaixo) e seu desempenho equivalente no download de arquivos grandes, como mostrado antes.
Desempenho da VM Windows com gsutil: arquivos pequenos
Abaixo, as métricas de upload de muitos arquivos pequenos a partir de uma VM Windows:
Measure-CommandAvg {gsutil -q -m cp -r parts gs://doit-speed-test-bucket/smallparts/}
# NVMe:
# Avg: 16m36.562s, 30.83 MB/s
# Min: 16m22.914s, 31.25 MB/s
# Max: 17m0.299s, 30.11 MB/s
# SCSI:
# Avg: 17m29.591s, 29.27 MB/s
# Min: 17m5.236s, 29.96 MB/s
# Max: 18m3.469s, 28.35 MB/s
O NVMe supera o SCSI, e seguimos vendo velocidades muito mais lentas do que em uma máquina Linux. No Linux, uploads em massa de arquivos pequenos levam cerca de 9m7s, ou seja, o tempo médio de upload no Windows com NVMe (16m36s) é cerca de 82% mais lento que no Linux.
Reprodutibilidade dos benchmarks
Se quiser rodar seus próprios benchmarks para replicar essas descobertas, abaixo estão os scripts shell e PowerShell que usei, com comentários resumindo o throughput observado:
Conclusões sobre o uso eficaz das ferramentas de transferência
No geral, há muito mais complexidade do que deveria existir para definir o melhor método de transferir dados entre VMs do GCE — com dados em um SSD local — e o GCS.

As diferenças de desempenho entre os vários SOs do GCE e o GCS estão todas conectadas de algum jeito, eu só sei que estão
Servidores Windows sofrem reduções drásticas tanto na velocidade de download quanto na de upload, por motivos ainda desconhecidos, em comparação com os melhores comandos equivalentes em uma máquina Linux. As quedas de desempenho são substanciais, geralmente de 70 a 80% mais lentas do que o melhor comando equivalente no Linux. Transferências de arquivos grandes são impactadas mais fortemente do que as de muitos arquivos pequenos.
Por isso, se você precisa migrar TBs de dados ou arquivos especialmente grandes do Windows para o GCS com prazo apertado, talvez valha a pena contornar esses problemas tirando um snapshot do disco, anexando um disco criado a partir desse snapshot a uma máquina Linux e subindo os dados a partir desse SO.
Independentemente das questões do Windows Server, a ferramenta padrão de transferência gsutil disponível em VMs do GCE é insuficiente para downloads de alto throughput em qualquer SO. Usando o s5cmd no lugar, dá para conseguir melhorias de várias vezes na velocidade de download.
Para te ajudar a navegar pela enxurrada de opções de ferramentas e argumentos, abaixo está um resumo das minhas recomendações para maximizar o throughput com base nos benchmarks deste artigo:
Linux — Download
- Arquivo único grande:
s5cmd --endpoint-url https://storage.googleapis.com cp s3://your_bucket/your_file . - Múltiplos arquivos, pequenos ou grandes:
s5cmd --endpoint-url https://storage.googleapis.com cp s3://your_bucket/path* your_path/
Linux — Upload
- Arquivo único grande:
gsutil -o GSUtil:parallel_composite_upload_threshold=150M cp your_file gs://your_bucket/ - Múltiplos arquivos, pequenos ou grandes:
gsutil -m -o GSUtil:parallel_composite_upload_threshold=150M cp -r your_path/ gs://your_bucket/
Windows Server — Download
- Use NVMe, não SCSI, para conectar um SSD local
- Arquivo único grande:
s5cmd --endpoint-url https://storage.googleapis.com cp -c=1 -p=1000000 s3://your_bucket/your_file . - Múltiplos arquivos, pequenos ou grandes:
s5cmd --endpoint-url https://storage.googleapis.com cp s3://your_bucket/path* your_path/
Windows Server — Upload
- Use NVMe, não SCSI, para conectar um SSD local
- Arquivo único grande:
gsutil cp your_file gs://your_bucket/ - Múltiplos arquivos, pequenos ou grandes:
gsutil -m cp -r your_path/ gs://your_bucket/your_path/