¿Tienes velocidades de transferencia lentas entre tu VM de GCE y un bucket de Cloud Storage? Sigue leyendo y descubre cómo sacarle el máximo throughput de subida y descarga a tus VMs Linux y Windows.
Resumen
Hace poco, un cliente de DoiT International me preguntó por qué los datos del SSD local de un Google Compute Engine (de aquí en adelante, GCE) con Windows Server se subían a un bucket de Cloud Storage mucho más lento de lo esperado. Al principio pensé que bastaría con un benchmarking sencillo de comandos gsutil para mostrar la efectividad de los argumentos ideales que recomienda la documentación de GCP. Sin embargo, ese vistazo "rápido" terminó convirtiéndose en una investigación a fondo del rendimiento de transferencia de datos entre GCE y GCS, porque los hallazgos iniciales fueron extraños y bastante inesperados.

Si solo te interesa saber cuáles son los métodos ideales para mover datos entre GCE y GCS en una máquina Linux o Windows, baja directo hasta "Conclusiones sobre el uso efectivo de herramientas de transferencia".
Si, en cambio, prefieres rascarte la cabeza con las extrañas y muchas veces contraintuitivas tasas de throughput que se obtienen con los comandos y argumentos más usados, acompáñame mientras entramos en detalle en lo que dio origen al complejo resumen de recomendaciones del final del artículo.
Rendimiento de una VM Linux con gsutil: archivos grandes
Aunque la solicitud del cliente involucraba transferencia de datos en un Windows Server, primero hice el benchmarking básico donde me sentía más cómodo:
Linux, mediante la imagen pública de GCE "Debian GNU/Linux 10 (buster)".
Como el cliente ya estaba intentando transferir archivos desde SSDs locales y yo quería minimizar las probabilidades de que los discos en red afectaran las velocidades, configuré dos tamaños de VM, n2-standard-4 y n2-standard-80, cada una con un SSD local conectado donde se hará el benchmarking.
El bucket de GCS que voy a usar, así como todas las VMs descritas en este artículo, se crearon como recursos regionales en us-central1.
Para simular la subida de archivos grandes del cliente, creé un archivo vacío de 30 GB:
fallocate -l 30G temp_30GB_file
A partir de ahí, probé dos parámetros de gsutil que suelen recomendarse:
-m: sirve para realizar copias paralelas y multihilo. Es útil para transferir muchos archivos en paralelo, no para subir archivos individuales.-o GSUtil:parallel_composite_upload_threshold=150M: divide los archivos grandes que superan el umbral indicado en partes que luego se suben en paralelo y se combinan al terminar la subida de todas.
El rendimiento máximo estimado para el SSD local en ambas VMs es el siguiente:
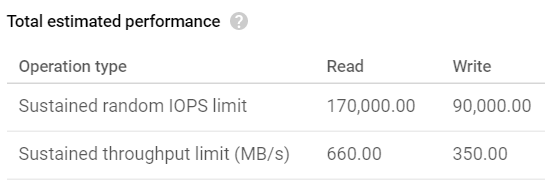
Límites de throughput de lectura/escritura del SSD local
Por lo tanto, deberíamos poder llegar hasta 660 MB/s de lectura y 350 MB/s de escritura con gsutil. Veamos qué arrojaron los benchmarks de subida:
time gsutil cp temp_30GB_file gs://doit-speed-test-bucket/
# n2-standard-4: 2m21.893s, 216.50 MB/s
# n2-standard-80: 2m11.676s, 233.30 MB/stime gsutil -m cp temp_30GB_file gs://doit-speed-test-bucket/
# n2-standard-4: 2m48.710s, 182.09 MB/s
# n2-standard-80: 2m29.348s, 205.69 MB/stime gsutil -o GSUtil:parallel_composite_upload_threshold=150M cp temp_30GB_file gs://doit-speed-test-bucket/
# n2-standard-4: 1m40.104s, 306.88 MB/s
# n2-standard-80: 0m52.145s, 589.13 MB/stime gsutil -m -o GSUtil:parallel_composite_upload_threshold=150M cp temp_30GB_file gs://doit-speed-test-bucket/
# n2-standard-4: 1m44.579s, 293.75 MB/s
# n2-standard-80: 0m51.154s, 600.54 MB/s
Tal como anticipa la documentación de gsutil de GCP, las subidas de archivos grandes se benefician al incluir -o GSUtil. Cuando hay más vCPUs disponibles para la subida en paralelo de las partes del archivo, el tiempo de subida mejora drásticamente, hasta el punto de que con una velocidad de subida sostenida de 600 MB/s en la n2-standard-80 nos acercamos al throughput máximo del SSD de 660 MB/s. Incluir -m para un solo archivo reduce el tiempo de subida unos cuantos segundos. Hasta aquí, nada fuera de lo común.
Veamos los benchmarks de descarga:
time gsutil cp gs://doit-speed-test-bucket/temp_30GB_file .
# n2-standard-4: 8m3.186s, 63.58 MB/s
# n2-standard-80: 6m13.585, 82.23 MB/stime gsutil -m cp gs://doit-speed-test-bucket/temp_30GB_file .
# n2-standard-4: 7m57.881s, 64.28 MB/s
# n2-standard-80: 6m20.131s, 80.81 MB/s

Espera un momento
El rendimiento de descarga en la VM de 80 vCPUs apenas alcanzó el 23% del throughput máximo de escritura del SSD local. Además, aunque activar el multihilo con -m no mejora el rendimiento en la descarga de un solo archivo, y aunque ambas máquinas operan muy por debajo de su throughput máximo (10 Gbps en la n2-standard-4 y 32 Gbps en la n2-standard-80), usar una máquina de mayor categoría dentro de la misma familia se traduce en una mejora de ~30% en la velocidad de descarga. Raro, pero no tanto como obtener apenas 1/4 del throughput de escritura del SSD local en una VM absurdamente cara.
¿Qué está pasando?
Después de buscar bastante, no encontré respuestas, pero sí descubrí s5cmd, una herramienta diseñada para acelerar drásticamente las subidas y descargas en buckets de S3. Asegura correr 12 veces más rápido que los comandos equivalentes del AWS CLI (por ejemplo, aws s3 cp), en gran parte porque está escrita en Go, un lenguaje compilado, mientras que el AWS CLI está escrito en Python. Resulta que gsutil también está escrito en Python. ¿Será que gsutil está limitado por su elección de lenguaje, o simplemente está mal optimizado? Como los buckets de GCS pueden configurarse con interoperabilidad con la API de S3, ¿se podrán acelerar las subidas y descargas con s5cmd con solo usar una herramienta compilada?
Rendimiento de una VM Linux con s5cmd: archivos grandes
Costó un poco poner s5cmd a funcionar, sobre todo porque tuve que descubrir por las malas que la interoperabilidad de GCS no soporta la API de subida multipart de S3, y como esta herramienta está pensada solo para AWS, falla en subidas de archivos grandes en GCP. Hay que pasar -p=1000000, un argumento que fuerza a evitar la subida multipart. Consulta los issues #1 y #2 de s5cmd para más detalles.
Ten en cuenta que s5cmd también ofrece un parámetro -c para definir el número de partes/archivos que se transfieren en paralelo, con un valor predeterminado de 5.
Con esos dos argumentos en mente, hice los siguientes benchmarks de subida en Linux:
time s5cmd --endpoint-url https://storage.googleapis.com cp -c=1 -p=1000000 temp_30GB_file s3://doit-speed-test-bucket/
# n2-standard-4: 6m7.459s, 83.60 MB/s
# n2-standard-80: 6m50.272s, 74.88 MB/stime s5cmd --endpoint-url https://storage.googleapis.com cp -p=1000000 temp_30GB_file s3://doit-speed-test-bucket/
# n2-standard-4: 7m18.682s, 70.03 MB/s
# n2-standard-80: 6m48.380s, 75.22 MB/s
Como era de esperar, las subidas de archivos grandes rinden bastante peor que con gsutil al no contar con una estrategia de subida multipart. Vemos 75–85 MB/s de subida frente a los 200–600 MB/s de gsutil. Fijar la concurrencia en 1 frente al valor predeterminado de 5 apenas mejora el rendimiento. Así que, dado que s5cmd trata a AWS como ciudadano de primera y deja a GCP de lado, no podemos mejorar las subidas usando s5cmd.
A continuación, los benchmarks de descarga con s5cmd:
time s5cmd --endpoint-url https://storage.googleapis.com cp -c=1 -p=1000000 s3://doit-speed-test-bucket/temp_30GB_file .
# n2-standard-4: 1m56.170s, 264.44 MB/s
# n2-standard-80: 1m46.196s, 289.28 MB/stime s5cmd --endpoint-url https://storage.googleapis.com cp -c=1 s3://doit-speed-test-bucket/temp_30GB_file .
# n2-standard-4: 3m21.380s, 152.55 MB/s
# n2-standard-80: 3m45.414s, 136.28 MB/stime s5cmd --endpoint-url https://storage.googleapis.com cp -p=1000000 s3://doit-speed-test-bucket/temp_30GB_file .
# n2-standard-4: 2m33.148s, 200.59 MB/s
# n2-standard-80: 2m48.071s, 182.78 MB/stime s5cmd --endpoint-url https://storage.googleapis.com cp s3://doit-speed-test-bucket/temp_30GB_file .
# n2-standard-4: 1m46.378s, 288.78 MB/s
# n2-standard-80: 2m1.116s, 253.64 MB/s
¡Qué mejora tan notable! Aunque hay algo de variabilidad en el tiempo de descarga, parece que al omitir -c y -p y dejarlos en sus valores predeterminados se alcanza la velocidad óptima. No llegamos al throughput máximo de escritura de 350 MB/s, pero los ~289 MB/s en una n2-standard-4 están mucho más cerca de eso que los ~64 MB/s que entrega gsutil en la misma máquina. Es decir, una mejora de 4.5X en la velocidad de descarga con solo cambiar la herramienta de transferencia.
Resumiendo todo lo anterior para Linux:
- Como
s5cmdno puede habilitar subidas multipart con GCS, conviene seguir usandogsutilpara subir a GCS, siempre y cuando incluyas-o GSUtil:parallel_composite_upload_threshold=150M. s5cmdcon sus parámetros predeterminados deja agsutilmuy atrás en rendimiento de descarga. Con solo usar una herramienta de transferencia escrita en un lenguaje compilado se obtienen mejoras drásticas (4.5X) en el rendimiento.
Rendimiento de una VM Windows con gsutil: archivos grandes
Si pensaste que lo anterior no era lo suficientemente raro, abróchate el cinturón porque ahora nos vamos al fondo del abismo con Windows. Como, después de todo, el cliente de DoiT trabajaba con Windows Server, era hora de hacer benchmarking en ese sistema operativo. Ya empezaba a sospechar que el problema no estaba entre el teclado y la silla.
Una vez confirmado que, en Linux, gsutil funciona muy bien para subir con los parámetros correctos y s5cmd funciona muy bien para descargar con los predeterminados, era momento de probar estos comandos en Windows, donde una vez más me iba a sentir humillado por mi falta de experiencia con Powershell.
Tras un rato logré reunir benchmarks de una máquina n2-standard-4 con un SSD local conectado, corriendo sobre la imagen de VM de GCE "Windows Server version 1809 Datacenter Core for Containers, built on 20200813". Debido a las tarifas de licenciamiento por vCPU que cobra Windows Server, decidí no recopilar métricas de una n2-standard-80 en este experimento.
Una nota importante antes de entrar en las métricas:
La documentación de GCP sobre conectar SSDs locales recomienda que para "todos los Windows Servers" se use el driver SCSI para conectar el SSD local en vez del driver NVMe que típicamente se usa en Linux, ya que SCSI está mejor optimizado para alcanzar el máximo throughput. Provisioné dos VMs con un SSD local conectado, una vía NVMe y otra vía SCSI, decidido a comparar su rendimiento junto con las distintas herramientas y parámetros que venía investigando.
Estos son los benchmarks de velocidad de subida:
Measure-Command {gsutil cp temp_30GB_file gs://doit-speed-test-bucket/}
# NVMe: 3m50.064s, 133.53 MB/s
# SCSI: 4m7.256s, 124.24 MB/sMeasure-Command {gsutil -m cp temp_30GB_file gs://doit-speed-test-bucket/}
# NVMe: 3m59.462s, 128.29 MB/s
# SCSI: 3m34.013s, 143.54 MB/sMeasure-Command {gsutil -o GSUtil:parallel_composite_upload_threshold=150M cp temp_30GB_file gs://doit-speed-test-bucket/}
# NVMe: 5m54.046s, 86.77 MB/s
# SCSI: 6m13.929s, 82.15 MB/sMeasure-Command {gsutil -m -o GSUtil:parallel_composite_upload_threshold=150M cp temp_30GB_file gs://doit-speed-test-bucket/}
# NVMe: 5m55.751s, 86.40 MB/s
# SCSI: 5m58.078s, 85.79 MB/s

No hay palabras para transmitir lo que siento en este momento
Sin argumentos en gsutil, el throughput de subida es ~60% del que se logra en una máquina Linux. Cualquier combinación de argumentos empeora el rendimiento. Cuando se habilita la subida multipart —que en Linux generaba una mejora del 42% en la velocidad— la velocidad de subida cae un 35%. También notarás que cuando no se pasa -m y se deja a gsutil subir un solo archivo grande de forma más óptima, la subida desde el disco NVMe se completa más rápido que desde el SCSI, supuestamente con drivers más optimizados para Windows Servers. ¿Qué está pasando aquí?
El bajo rendimiento de subida en torno a 80–85 MB/s era exactamente el rango que estaba viendo el cliente de DoiT, así que al menos su problema era reproducible. Eliminando el argumento recomendado por GCP
-o GSUtil:parallel_composite_upload_threshold=150M en subidas de archivos grandes, el cliente podía evitar una penalización del 35% en el rendimiento. 🤷
Los benchmarks de descarga cuentan una historia aún más dramática:
Measure-Command {gsutil cp gs://doit-speed-test-bucket/temp_30GB_file .}
# NVMe 1st attempt: 11m39.426s, 43.92 MB/s
# NVMe 2nd attempt: 9m1.857s, 56.69 MB/s
# SCSI 1st attempt: 8m54.462s, 57.48 MB/s
# SCSI 2nd attempt: 10m1.023s, 51.05 MB/sMeasure-Command {gsutil -m cp gs://doit-speed-test-bucket/temp_30GB_file .}
# NVMe 1st attempt: 8m52.537s, 57.69 MB/s
# NVMe 2nd attempt: 22m4.824s, 23.19 MB/s
# NVMe 3rd attempt: 8m50.202s, 57.94 MB/s
# SCSI 1st attempt: 7m29.502s, 68.34 MB/s
# SCSI 2nd attempt: 9m9.652s, 55.89 MB/s
No logré obtener benchmarks de descarga consistentes por lo siguiente:
- Cada operación de descarga se quedaba colgada hasta 2 minutos antes de iniciarse
- La descarga arrancaba y avanzaba a unos 68–70 MB/s, hasta que…
- A veces se pausaba de nuevo durante un tiempo indefinido
Este ciclo de colgarse y reanudar la descarga continuaba una y otra vez, haciendo que los promedios de velocidad en la misma VM con el mismo disco oscilaran entre 23 MB/s y 58 MB/s. Era una locura tratar de determinar si NVMe o SCSI eran más óptimos para descargas con estos cuelgues aleatorios y prolongados. Más adelante volvemos a este veredicto.
Rendimiento de una VM Windows con s5cmd: archivos grandes
Frustrado con el rendimiento errático y disparatado de las descargas con gsutil, pasé rápidamente a s5cmd: ¿quizás podría resolver o reducir el impacto de los cuelgues?
Veamos primero los benchmarks de subida con s5cmd:
Measure-Command {s5cmd --endpoint-url https://storage.googleapis.com cp -c=1 -p=1000000 temp_30GB_file s3://doit-speed-test-bucket/}
# NVMe: 6m21.780s, 80.46 MB/s
# SCSI: 7m14.162s, 70.76 MB/sMeasure-Command {s5cmd --endpoint-url https://storage.googleapis.com cp -p=1000000 temp_30GB_file s3://doit-speed-test-bucket/}
# NVMe: 12m56.066s, 39.58 MB/s
# SCSI: 8m12.255s, 62.41 MB/s
Igual que en Linux, la subida con s5cmd se ve limitada por la imposibilidad de usar subidas multipart. El rendimiento con concurrencia en 1 es comparable al alcanzado por la misma herramienta en una máquina Linux, pero con la concurrencia en su valor predeterminado de 5 se producen caídas (y oscilaciones) drásticas. La severidad del impacto de la concurrencia llama la atención, pero como el rendimiento de subida de s5cmd sigue siendo notablemente peor que el de gsutil (lo cual es raro, dado que ninguno de los dos usa subidas multipart en este caso), tampoco queremos usar s5cmd para subir; mejor ignoremos esa rareza de la concurrencia.
Pasemos a los benchmarks de descarga con s5cmd:
Measure-Command {s5cmd --endpoint-url https://storage.googleapis.com cp -c=1 -p=1000000 s3://doit-speed-test-bucket/temp_30GB_file .}
# NVMe 1st attempt: 2m17.954s, 222.68 MB/s
# NVMe 2nd attempt: 1m44.718s, 293.36 MB/s
# SCSI 1st attempt: 3m9.581s, 162.04 MB/s
# SCSI 2nd attempt: 1m52.500s, 273.07 MB/sMeasure-Command {s5cmd --endpoint-url https://storage.googleapis.com cp -c=1 s3://doit-speed-test-bucket/temp_30GB_file .}
# NVMe 1st attempt: 3m18.006s, 155.15 MB/s
# NVMe 2nd attempt: 4m2.792s, 126.53 MB/s
# SCSI 1st attempt: 3m37.126s, 141.48 MB/s
# SCSI 2nd attempt: 4m9.657s, 123.05 MB/sMeasure-Command {s5cmd --endpoint-url https://storage.googleapis.com cp -p=1000000 s3://doit-speed-test-bucket/temp_30GB_file .}
# NVMe 1st attempt: 2m17.151s, 223.99 MB/s
# NVMe 2nd attempt: 1m47.217s, 286.52 MB/s
# SCSI 1st attempt: 4m39.120s, 110.06 MB/s
# SCSI 2nd attempt: 1m42.159s, 300.71 MB/sMeasure-Command {s5cmd --endpoint-url https://storage.googleapis.com cp s3://doit-speed-test-bucket/temp_30GB_file .}
# NVMe 1st attempt: 2m48.714s, 182.08 MB/s
# NVMe 2nd attempt: 2m41.174s, 190.60 MB/s
# SCSI 1st attempt: 2m35.480s, 197.58 MB/s
# SCSI 2nd attempt: 2m40.483s, 191.42 MB/s
Si bien hay algunos cuelgues y variabilidad en las descargas como con gsutil, s5cmd vuelve a ser mucho más rápido que gsutil en descargas. Además, los cuelgues fueron de menor duración o menor frecuencia. Aun así, esos extraños cuelgues siguen siendo un problema ocasional.
A diferencia de cómo logré el máximo rendimiento en una VM Linux omitiendo -c y -p, aquí el rendimiento óptimo parece haberse alcanzado al incluir ambos con -c=1 -p=1000000. Es difícil afirmar con certeza que esa sea la configuración más óptima por culpa de los cuelgues aleatorios que afectan los benchmarks, pero parece funcionar bastante bien con esos argumentos. Igual que con gsutil, también es difícil determinar si NVMe o SCSI están mejor optimizados debido a los cuelgues.
Para entender mejor las velocidades de descarga en NVMe y SCSI con los argumentos óptimos de s5cmd, escribí una función que reporta el tiempo de ejecución promedio, mínimo y máximo de 20 descargas repetidas, con la idea de promediar los cuelgues momentáneos:
Measure-CommandAvg {s5cmd --endpoint-url https://storage.googleapis.com cp -c=1 -p=1000000 s3://doit-speed-test-bucket/temp_30GB_file .}
### With 20 sample downloads
# NVMe:
# Avg: 1m48.014s, 284.41 MB/s
# Min: 1m23.411s, 368.30 MB/s
# Max: 3m10.989s, 160.85 MB/s
# SCSI:
# Avg: 1m47.737s, 285.14 MB/s
# Min: 1m24.784s, 362.33 MB/s
# Max: 4m44.807s, 107.86 MB/s
Sigue habiendo variabilidad en cuánto tarda la misma descarga en completarse, pero queda claro que SCSI no aporta una ventaja sobre NVMe en general para descargas de archivos grandes, a pesar de ser supuestamente el driver ideal para un SSD local en una VM Windows.
Validemos también si las subidas son más rápidas vía NVMe usando la misma función de promediado en 20 subidas repetidas:
Measure-CommandAvg {gsutil cp temp_30GB_file gs://doit-speed-test-bucket/}
# NVMe:
# Avg: 3m23.216s, 151.17 MB/s
# Min: 2m31.169s, 203.22 MB/s
# Max: 4m13.943s, 121.42 MB/s
# SCSI:
# Avg: 5m1.570s, 101.87 MB/s
# Min: 3m2.649s, 168.19 MB/s
# Max: 35m3.276s, 14.61 MB/s
Esto valida lo que ya mostraban las corridas individuales: NVMe podría ser más rápido que SCSI para subidas. En este caso, con veinte corridas repetidas, NVMe es bastante más rápido.
Por lo tanto, en VMs Windows, y a contramano de la documentación de GCP, no solo conviene evitar -o GSUtil:parallel_composite_upload_threshold=150M con gsutil al subir a GCS, sino también evitar SCSI y preferir NVMe como driver de SSD local para mejorar las subidas y, posiblemente, las descargas. También se observa que tanto en descargas como en subidas hay pausas frecuentes e impredecibles que van de 1–2 minutos hasta 10–30 minutos.
¿Qué le digo al cliente…?
Llegado a este punto, le expliqué al cliente que existen limitaciones de transferencia de datos inherentes al uso de una VM Windows; sin embargo, era posible mitigarlas en parte:
- Dejando los argumentos opcionales en sus valores predeterminados para subidas de archivos grandes con
gsutil cp, a pesar de que la documentación de GCP sugiera lo contrario - Usando
s5cmd -c=1 -p=1000000en lugar degsutilpara descargas - Usando el driver NVMe en lugar de SCSI para el almacenamiento SSD local con el fin de mejorar tanto las subidas como, posiblemente, las descargas, a pesar de que la documentación de GCP sugiera lo contrario
También le comenté al cliente que las subidas y descargas mejorarían drásticamente si se evitaban por completo los cuelgues de Windows: bastaba con mover los datos a una máquina Linux mediante snapshots de disco y luego ejecutar las operaciones de sincronización con GCS desde un disco conectado a Linux. Esa terminó siendo la forma más rápida de obtener el throughput esperado entre una VM de GCE y GCS, y dejó al cliente satisfecho, aunque frustrado con los problemas de rendimiento sin sentido de su Windows Server.
Mi conclusión de la experiencia fue esta: gsutil no solo está lamentablemente poco optimizado para operaciones en Windows servers, sino que además parece haber un problema de fondo en la capacidad de GCS para transferir datos hacia y desde Windows, ya que tanto gsutil como s5cmd presentan retrasos y cuelgues en descargas y subidas.
El problema del cliente quedó resuelto… y, sin embargo, mi curiosidad seguía sin saciarse. ¿Qué otros saqueos de ancho de banda me esperaban al intentar transferir muchos archivos pequeños en lugar de unos pocos archivos grandes?
Rendimiento de una VM Linux con gsutil: archivos pequeños
Volviendo a Linux, dividí el archivo grande de 30 GB en 50K (bueno, 50.001) archivos:
mkdir parts
split -b 644245 temp_30GB_file
mv x* parts/
Y procedí a hacer benchmarking del rendimiento de subida con gsutil:
nohup bash -c 'time gsutil cp -r parts/* gs://doit-speed-test-bucket/smallparts/' &
# n2-standard-4: 71m30.420s, 7.16 MB/s
# n2-standard-80: 69m32.803s, 7.36 MB/snohup bash -c 'time gsutil -m cp -r parts/* gs://doit-speed-test-bucket/smallparts/' &
# n2-standard-4: 9m7.045s, 56.16 MB/s
# n2-standard-80: 3m41.081s, 138.95 MB/s
Como era de esperar, pasar -m para activar la subida paralela y multihilo de archivos mejora drásticamente la velocidad: no intentes subir una carpeta grande de archivos sin él. Cuantas más vCPUs tenga tu máquina, más subidas de archivos podrás hacer en simultáneo.
A continuación, los benchmarks de descarga con gsutil:
nohup bash -c 'time gsutil cp -r gs://doit-speed-test-bucket/smallparts/ parts/' &
# n2-standard-4: 61m24.516s, 8.34 MB/s
# n2-standard-80: 56m54.841s, 9.00 MB/snohup bash -c 'time gsutil -m cp -r gs://doit-speed-test-bucket/smallparts/ parts/' &
# n2-standard-4: 7m42.249s, 66.46 MB/s
# n2-standard-80: 3m38.421s, 140.65 MB/s
Una vez más, pasar -m es indispensable: no intentes descargar una carpeta grande de archivos sin él. Igual que con las subidas, el rendimiento de gsutil mejora con subidas paralelas usando -m y muchas vCPUs disponibles.
No encontré nada fuera de lo común en Linux con descargas y subidas masivas de archivos pequeños usando gsutil.
Rendimiento de una VM Linux con s5cmd: archivos pequeños
Ya quedó claro que s5cmd no debe usarse para subir archivos a GCS, así que solo reportaré los benchmarks de descarga en Linux:
nohup bash -c 'time s5cmd --endpoint-url https://storage.googleapis.com cp s3://doit-speed-test-bucket/smallparts/* parts/' &
# n2-standard-4: 1m19.531s, 386.26 MB/s
# n2-standard-80: 1m31.592s, 335.40 MB/snohup bash -c 'time s5cmd --endpoint-url https://storage.googleapis.com cp -c=80 s3://doit-speed-test-bucket/smallparts/* parts/' &
# n2-standard-80: 1m29.837s, 341.95 MB/s
En la máquina n2-standard-4 vemos un aumento de 6.9X en la velocidad de descarga masiva de archivos pequeños frente a gsutil. Tiene sentido, entonces, usar s5cmd tanto para descargar muchos archivos pequeños como para descargar archivos grandes.
No se observó nada fuera de lo común en Linux con descargas masivas de archivos pequeños usando s5cmd.
Rendimiento de una VM Windows con s5cmd: archivos pequeños (y pruebas adicionales con archivos grandes)
Como s5cmd es bastante más rápido que gsutil en descargas en cualquier sistema operativo, solo consideraré s5cmd para los benchmarks de descarga en Windows con archivos pequeños:
Measure-CommandAvg {s5cmd --endpoint-url https://storage.googleapis.com cp s3://doit-speed-test-bucket/smallparts/* parts/}
# NVMe:
# Avg: 2m39.540s, 192.55 MB/s
# Min: 2m35.323s, 197.78 MB/s
# Max: 2m44.260s, 187.02 MB/s
# SCSI:
# Avg: 2m45.431s, 185.70 MB/s
# Min: 2m40.785s, 191.06 MB/s
# Max: 2m50.930s, 179.72 MB/s
Vemos que descargar 50K archivos pequeños a una VM Windows rinde mejor y de forma más predecible que descargar archivos mucho más grandes. NVMe le saca a SCSI apenas un pelito.
Hay una llamativa consistencia y ausencia de cuelgues prolongados con la sincronización de datos en este caso, frente a los comandos de copia de archivos grandes individuales que vimos antes. Solo para confirmar plenamente que la tendencia a colgarse es más probable con archivos grandes, corrí la función de promediado sobre 20 descargas repetidas del archivo de 30 GB:
Measure-CommandAvg {s5cmd --endpoint-url https://storage.googleapis.com cp -p=1000000 s3://doit-speed-test-bucket/temp_30GB_file .}
### With 20 sample downloads
# NVMe:
# Avg: 3m3.770s, 167.17 MB/s
# Min: 1m34.901s, 323.70 MB/s
# Max: 10m34.575s, 48.41 MB/s
# SCSI:
# Avg: 2m20.131s, 219.22 MB/s
# Min: 1m31.585s, 335.43 MB/s
# Max: 3m43.215s, 137.63 MB/s
Vemos que el tiempo de descarga en Windows con NVMe va de 1m37s a 10m35s, mientras que con 50K archivos pequeños en el mismo sistema operativo el tiempo solo varía entre 2m35s y 2m44s. Por lo tanto, parece haber un problema específico de Windows o de GCS con las transferencias de archivos grandes en una VM Windows.
Nota también que el tiempo promedio de descarga en NVMe es aproximadamente un 73% más largo (3m3s vs. 1m46s) que al correr s5cmd en Linux.
Sería tentador decir que SCSI podría ser más ventajoso que NVMe para descargas masivas de archivos pequeños según los resultados anteriores, pero con los cuelgues aleatorios distorsionando el promedio me quedo con NVMe como driver preferido, dada su efectividad probada al subir archivos pequeños en masa (ver más abajo) y su rendimiento equiparable al descargar archivos grandes, como ya se mostró.
Rendimiento de una VM Windows con gsutil: archivos pequeños
A continuación, las métricas para subir muchos archivos pequeños desde una VM Windows:
Measure-CommandAvg {gsutil -q -m cp -r parts gs://doit-speed-test-bucket/smallparts/}
# NVMe:
# Avg: 16m36.562s, 30.83 MB/s
# Min: 16m22.914s, 31.25 MB/s
# Max: 17m0.299s, 30.11 MB/s
# SCSI:
# Avg: 17m29.591s, 29.27 MB/s
# Min: 17m5.236s, 29.96 MB/s
# Max: 18m3.469s, 28.35 MB/s
NVMe vuelve a superar a SCSI, y las velocidades siguen siendo bastante más bajas que en una máquina Linux. En Linux, las subidas masivas de archivos pequeños tardan unos 9m7s, lo que hace que el tiempo promedio de subida en Windows con NVMe (16m36s) sea aproximadamente un 82% más lento que en Linux.
Reproducibilidad del benchmark
Si quieres correr tus propios benchmarks para replicar mis hallazgos, abajo están los scripts de shell y Powershell que utilicé, junto con comentarios que resumen el throughput observado:
Conclusiones sobre el uso efectivo de herramientas de transferencia
En definitiva, hay mucha más complejidad de la que debería para determinar cuál es el mejor método para transferir datos entre VMs de GCE —con datos en un SSD local— y GCS.

Las diferencias de rendimiento entre los distintos sistemas operativos de GCE y GCS están relacionadas de algún modo, lo sé
Los Windows servers sufren caídas drásticas tanto en velocidades de descarga como de subida por motivos aún desconocidos, en comparación con los mejores comandos equivalentes en una máquina Linux. Estas caídas son sustanciales, normalmente entre 70 y 80% más lentas que el mejor comando equivalente en Linux. Las transferencias de archivos grandes se ven afectadas con mayor severidad que las de muchos archivos pequeños.
Por eso, si necesitas migrar TBs de datos o archivos especialmente grandes desde Windows a GCS de manera urgente, conviene esquivar estos problemas tomando un snapshot de disco, conectando un disco creado a partir de ese snapshot a una máquina Linux y subiendo los datos desde ese sistema operativo.
Más allá de los problemas de Windows server, la herramienta de transferencia de datos predeterminada gsutil, disponible en las VMs de GCE, resulta inadecuada para descargas de alto throughput en cualquier sistema operativo. Al usar s5cmd en su lugar, puedes lograr mejoras de varias veces en la velocidad de descarga.
Para ayudarte a navegar la enorme variedad de herramientas y argumentos, aquí va un resumen de mis recomendaciones para maximizar el throughput según los benchmarks cubiertos en este artículo:
Linux — Descarga
- Un solo archivo grande:
s5cmd --endpoint-url https://storage.googleapis.com cp s3://your_bucket/your_file . - Múltiples archivos, pequeños o grandes:
s5cmd --endpoint-url https://storage.googleapis.com cp s3://your_bucket/path* your_path/
Linux — Subida
- Un solo archivo grande:
gsutil -o GSUtil:parallel_composite_upload_threshold=150M cp your_file gs://your_bucket/ - Múltiples archivos, pequeños o grandes:
gsutil -m -o GSUtil:parallel_composite_upload_threshold=150M cp -r your_path/ gs://your_bucket/
Windows Server — Descarga
- Usa NVMe, no SCSI, para conectar un SSD local
- Un solo archivo grande:
s5cmd --endpoint-url https://storage.googleapis.com cp -c=1 -p=1000000 s3://your_bucket/your_file . - Múltiples archivos, pequeños o grandes:
s5cmd --endpoint-url https://storage.googleapis.com cp s3://your_bucket/path* your_path/
Windows Server — Subida
- Usa NVMe, no SCSI, para conectar un SSD local
- Un solo archivo grande:
gsutil cp your_file gs://your_bucket/ - Múltiples archivos, pequeños o grandes:
gsutil -m cp -r your_path/ gs://your_bucket/your_path/