Le Spot VM di GCP sono una delle leve di costo più efficaci nel cloud: offrono fino al 91% di sconto rispetto al prezzo on-demand standard sfruttando la capacità in eccesso di Compute Engine che altrimenti resterebbe inutilizzata.
Il compromesso è noto: Compute Engine può richiamare le Spot VM in qualsiasi momento. Al momento della preemption, GCP invia un segnale di terminazione e avvia una finestra di shutdown best-effort di 30 secondi, entro la quale la VM può arrestarsi in modo controllato prima di essere terminata. Per i workloads che richiedono più tempo per il drain è inoltre disponibile in Preview un preavviso di preemption esteso a 120 secondi.
Ciò che finora è rimasto meno chiaro è se uno specifico tipo di macchina, in una determinata zona, sarà effettivamente disponibile quando serve.
Il problema: provisioning alla cieca
Gestire le Spot VM su larga scala è sempre stato frustrante, perché non esisteva un modo affidabile per verificare in anticipo la capacità di una zona. Si avviava il Managed Instance Group, si richiedeva la creazione o lo scaling, e solo dopo si scopriva se la zona disponeva di risorse sufficienti. Ogni problema di disponibilità emergeva sotto forma di provisioning fallito, lasciando ai team la scelta se attendere, riprovare o cercare alternative.
La scelta della zona soffriva dello stesso limite. La disponibilità non dipende solo dalla region, ma dalle singole zone al suo interno. Senza dati, i team ripiegavano sulle zone abituali invece che su quelle con più capacità disponibile.
Il risultato era un ciclo di feedback reattivo:
- Le richieste di provisioning fallite portavano alla luce i problemi di disponibilità solo dopo il fatto.
- La scelta della zona era una scommessa, non una decisione informata.
- La frequenza di preemption era opaca, senza alcun segnale sulla stabilità di un tipo di macchina in una data location.
- La pianificazione dei costi era difficile senza visibilità sui trend di prezzo affiancati al rischio di preemption.
Cosa è cambiato: segnali di disponibilità in tempo reale
GCP ha introdotto i segnali di disponibilità in tempo reale per le Spot VM tramite l'API advice.capacity, ora in Public Preview. Prima di procedere con il provisioning si possono interrogare due metriche chiave per uno specifico tipo di macchina e una specifica zona.
1. Punteggio di ottenibilità
Un valore numerico che indica la probabilità di successo della richiesta di creazione della Spot VM, sulla base della disponibilità di risorse attuale e dei tassi di successo recenti.
| Punteggio | Segnale |
|---|---|
0.7 – 1.0 |
Alto — probabilità di successo molto elevata |
0.4 – 0.6 |
Medio — moderatamente probabile; la creazione in blocco potrebbe essere soddisfatta solo in parte |
0.0 – 0.3 |
Basso — successo improbabile; valuti una zona, una region o un tipo di macchina diversi |
I punteggi di ottenibilità non sono garanzie. La capacità può variare tra il momento della query e quello del provisioning.
2. Uptime stimato
La durata minima prevista per cui la maggior parte delle Spot VM dovrebbe restare attiva prima della preemption, calcolata a partire dai pattern di utilizzo storici e attuali.
| Uptime stimato | Cosa significa |
|---|---|
| 60 minuti (3.600s) | Adatto a workloads batch di lunga durata che tollerano interruzioni occasionali |
| 10 minuti (600s) | Da usare solo per attività brevi o workloads con checkpoint frequenti |
| 1 minuto (60s) | Solo per test o attività non critiche; valuti una zona o un tipo di macchina diversi |
L'uptime stimato non è una garanzia. Le VM possono restare attive più o meno a lungo di quanto stimato.
Come utilizzare la funzionalità
Il Capacity Advisor della Console per Spot è il modo più rapido per ottenere una vista d'insieme: ottenibilità in tempo reale e tasso di preemption storico affiancati in un'unica interfaccia. La superficie gcloud distribuisce queste informazioni su comandi distinti, pensati per scripting e automazione.
Dalla Console (Capacity Advisor per Spot)
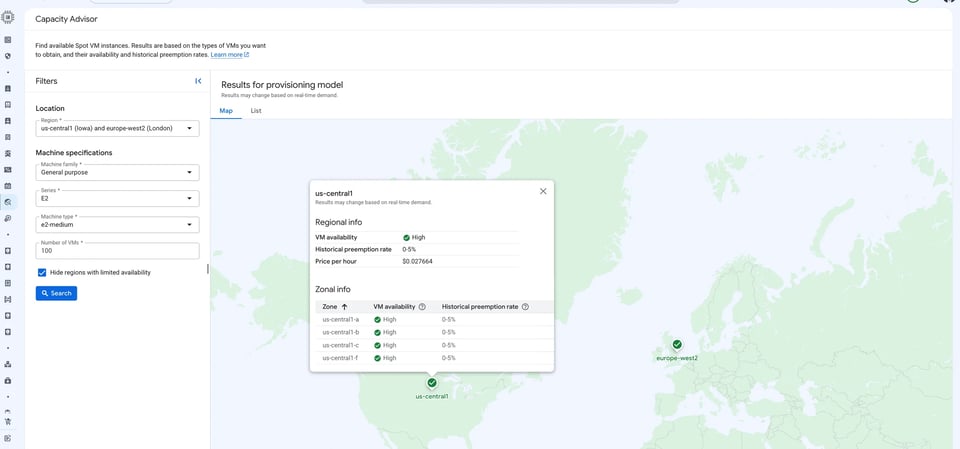
Acceda a Compute Engine → Capacity Advisor nella Console GCP. Selezioni region, famiglia di macchine, serie e tipo di macchina, quindi clicchi su Cerca.
Le viste Mappa ed Elenco mostrano i segnali di disponibilità per region e per zona, insieme ai tassi di preemption storici e ai prezzi Spot attuali. Per confrontare la disponibilità di più serie, tipi di macchina e region in parallelo, usi questa vista della console anziché la CLI.
Lo screenshot qui sotto mostra us-central1 interrogata per una Spot VM e2-medium: disponibilità Alta e tasso di preemption storico dello 0–5% in tutte e quattro le zone (us-central1-a, -b, -c, -f), al prezzo Spot corrente di $0.027664/hr.
Tramite gcloud
Disponibilità in tempo reale e uptime stimato:
gcloud beta compute advice capacity \ --provisioning-model=SPOT \ --instance-selection-machine-types=MACHINE_TYPES \ --target-distribution-shape=TARGET_DISTRIBUTION_SHAPE \ --size=SIZE \ --region=REGIONLa risposta include il punteggio obtainability e l'estimatedUptime per la configurazione richiesta.
Esempio di output:
recommendations:- scores: estimatedUptime: 3600s obtainability: 0.9 shards: - instanceCount: 10 machineType: e2-medium provisioningModel: SPOT zone: https://www.googleapis.com/compute/beta/projects/chimbuc-playground/zones/us-central1-fTasso di preemption storico e prezzi:
Il comando capacity-history restituisce i tassi di preemption giornalieri e lo storico dei prezzi per un tipo di macchina e una zona specifici:
gcloud beta compute advice capacity-history \ --provisioning-model=SPOT \ --machine-type=e2-medium \ --types=PREEMPTION,PRICE \ --region=us-central1Esempio di output:
location: https://www.googleapis.com/compute/beta/projects/chimbuc-playground/regions/us-central1machineType: e2-mediumpreemptionHistory:- interval: endTime: '2026-06-23T07:00:00Z' startTime: '2026-03-25T07:00:00Z' preemptionRate: 0.0priceHistory:- interval: endTime: '2026-04-12T07:00:00Z' startTime: '2026-04-08T07:00:00Z' listPrice: currencyCode: USD nanos: 26752000- interval: endTime: '2026-06-16T07:00:00Z' startTime: '2026-04-12T07:00:00Z' listPrice: currencyCode: USD nanos: 27664000Usi capacity per orientare la scelta di zona e tipo di macchina prima del provisioning; usi capacity-history per valutare stabilità di lungo periodo e volatilità dei prezzi quando progetta l'architettura dei workloads o pianifica il budgeting FinOps.
Limiti
- La disponibilità delle TPU non è interrogabile tramite l'API
advice.capacity. - Le AI zones sono incluse di default nelle raccomandazioni: verifichi che siano abilitate sul suo progetto prima di dare seguito a tali raccomandazioni.
- Per interrogare la disponibilità di N1 GPU VM o di dischi Local SSD non collegati di default a un tipo di macchina, usi direttamente le REST API.
- Punteggi e stime di uptime non sono garanzie: la capacità può cambiare tra il momento della query e quello della creazione.
Best practice
Confronti tra tipi di macchina. Se il workload è flessibile, confronti gli output di configurazioni diverse — ad esempio
100 × n1-standard-2vs50 × n1-standard-4. Scelga la configurazione che, per le sue esigenze, bilancia meglio ottenibilità e uptime stimato.Confronti tra location. Se il workload può girare in più region o zone, verifichi la disponibilità di ciascuna. A parità di uptime stimato tra due region, preferisca quella con il punteggio di ottenibilità più alto.
Distribuisca su più zone. Con una distribution shape
ANYoBALANCEDin un MIG regionale, l'API può suggerire di suddividere le VM tra più zone per massimizzare il successo della creazione — ad esempio 90 VM in una zona e 10 in un'altra, invece di concentrarne 100 in un'unica zona.Ripeta i controlli periodicamente. La disponibilità Spot varia con la domanda a livello GCP. Integri un controllo periodico nel ciclo di gestione dei MIG o di revisione dei node pool GKE.
In sintesi
Fare provisioning di Spot VM senza verificarne prima la disponibilità è come mettersi in viaggio senza mappa. L'API advice.capacity le mette quella mappa in mano. Non c'è alcun buon motivo per saltare la query.
Prima di scrivere un instance template, prima di eseguire terraform apply, prima di scalare un MIG, faccia il controllo. Le dirà se la zona sarà in grado di fornire VM e per quanto tempo è probabile che restino attive. Quel segnale deve guidare la scelta della zona, del tipo di macchina e dell'intervallo di checkpoint.
Le Spot VM restano una delle migliori leve di costo su GCP. Lo sconto del 91% è reale. Anche il rischio di preemption lo è, ma oggi è un rischio noto e interrogabile, non più cieco.
Interroghi prima. Scelga in base al segnale. Progetti in funzione dell'uptime. Rivaluti al variare della domanda.