Les Spot VMs GCP sont l'un des leviers de réduction de coûts les plus efficaces sur le cloud — jusqu'à 91 % de remise sur les tarifs on-demand standards, en exploitant la capacité excédentaire de Compute Engine qui resterait autrement inutilisée.
La contrepartie est bien connue : Compute Engine peut récupérer les Spot VMs à tout moment. Lors d'une préemption, GCP envoie un signal de terminaison et amorce une fenêtre d'arrêt best-effort de 30 secondes pour permettre à la VM de s'arrêter proprement avant sa terminaison. Un préavis de préemption de 120 secondes est également disponible en Preview pour les workloads qui ont besoin de plus de temps pour se vider.
Ce qui restait flou — jusqu'à récemment — c'était de savoir si un type de machine donné dans une zone donnée serait effectivement disponible au moment voulu.
Le problème : provisionner à l'aveugle
Gérer des Spot VMs à grande échelle était frustrant, faute de moyen fiable de vérifier au préalable la capacité d'une zone. Vous lanciez votre Managed Instance Group, demandiez une création ou un scaling, et ne découvriez qu'après coup si la zone disposait des ressources nécessaires. Tout problème de disponibilité se traduisait par un échec de provisionnement, laissant les équipes hésiter entre attendre, réessayer ou chercher une alternative.
Le choix des zones souffrait du même travers. La disponibilité ne dépend pas seulement de la région, mais des zones individuelles au sein de celle-ci. Sans données, les équipes se rabattaient sur les zones habituelles plutôt que sur celles offrant la plus grande capacité disponible.
Résultat : une boucle de feedback purement réactive :
- Les échecs de provisionnement révélaient les problèmes de disponibilité après coup seulement.
- Le choix des zones relevait de la supposition plutôt que d'une décision éclairée.
- La fréquence des préemptions restait opaque, sans aucun signal sur la stabilité d'un type de machine dans un emplacement donné.
- La planification budgétaire était difficile faute de visibilité sur l'évolution des prix et sur le risque de préemption.
Ce qui change : des signaux de disponibilité en temps réel
GCP a introduit des signaux de disponibilité en temps réel pour les Spot VMs via l'API advice.capacity, désormais en Public Preview. Avant de vous engager dans un provisionnement, vous pouvez interroger deux indicateurs clés pour un type de machine et une zone donnés.
1. Score d'obtenabilité
Valeur numérique indiquant la probabilité que votre demande de création de Spot VM aboutisse, calculée à partir de la disponibilité actuelle des ressources et des taux de succès récents.
| Score | Signal |
|---|---|
0.7 – 1.0 |
Élevé — très forte probabilité de succès |
0.4 – 0.6 |
Moyen — probabilité modérée ; une création en masse peut n'être que partiellement satisfaite |
0.0 – 0.3 |
Faible — succès improbable ; envisagez une autre zone, région ou un autre type de machine |
Les scores d'obtenabilité ne sont pas des garanties. La capacité peut évoluer entre le moment de la requête et celui du provisionnement.
2. Uptime estimé
Durée minimale pendant laquelle la plupart de vos Spot VMs devraient fonctionner avant préemption, calculée à partir des schémas d'utilisation historiques et actuels.
| Uptime estimé | Signification |
|---|---|
| 60 minutes (3 600 s) | Adapté aux workloads batch de longue durée qui tolèrent des interruptions occasionnelles |
| 10 minutes (600 s) | À réserver aux tâches courtes ou aux workloads avec checkpoints fréquents |
| 1 minute (60 s) | Uniquement pour des tests ou des travaux non critiques ; envisagez une autre zone ou un autre type de machine |
L'uptime estimé n'est pas une garantie. Les VMs peuvent fonctionner plus ou moins longtemps que prévu.
Utiliser la fonctionnalité
Le Capacity Advisor de la Console pour Spot est le moyen le plus rapide d'obtenir une vue combinée — obtenabilité en temps réel et taux de préemption historique côte à côte, dans une même interface. La CLI gcloud répartit ces informations sur des commandes distinctes, adaptées au scripting et à l'automatisation.
Via la Console (Capacity Advisor pour Spot)
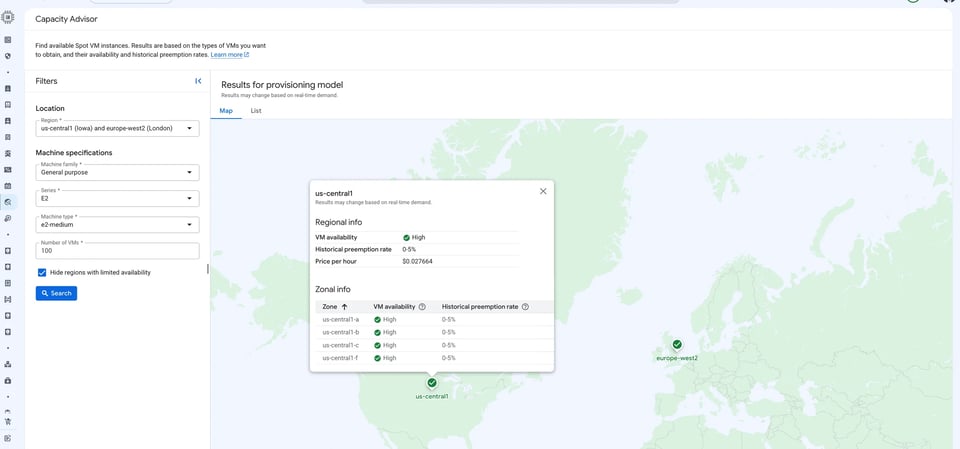
Rendez-vous dans Compute Engine → Capacity Advisor dans la Console GCP. Sélectionnez votre région, votre famille de machines, votre série et votre type de machine, puis cliquez sur Search.
Les vues Map et List affichent les signaux de disponibilité par région et par zone, ainsi que les taux de préemption historiques et les prix Spot actuels. Pour comparer simultanément la disponibilité entre plusieurs séries, types de machines et régions, préférez cette vue Console à la CLI.
La capture ci-dessous montre us-central1 interrogée pour une Spot VM e2-medium — disponibilité élevée et taux de préemption historique de 0 à 5 % dans les quatre zones (us-central1-a, -b, -c, -f), à un prix Spot actuel de 0,027664 $/h.
Via gcloud
Disponibilité en temps réel et uptime estimé :
gcloud beta compute advice capacity \ --provisioning-model=SPOT \ --instance-selection-machine-types=MACHINE_TYPES \ --target-distribution-shape=TARGET_DISTRIBUTION_SHAPE \ --size=SIZE \ --region=REGIONLa réponse contient le score obtainability et la valeur estimatedUptime pour la configuration demandée.
Exemple de sortie :
recommendations:- scores: estimatedUptime: 3600s obtainability: 0.9 shards: - instanceCount: 10 machineType: e2-medium provisioningModel: SPOT zone: https://www.googleapis.com/compute/beta/projects/chimbuc-playground/zones/us-central1-fTaux de préemption historique et tarification :
La commande capacity-history renvoie les taux de préemption quotidiens et l'historique des prix pour un type de machine et une zone donnés :
gcloud beta compute advice capacity-history \ --provisioning-model=SPOT \ --machine-type=e2-medium \ --types=PREEMPTION,PRICE \ --region=us-central1Exemple de sortie :
location: https://www.googleapis.com/compute/beta/projects/chimbuc-playground/regions/us-central1machineType: e2-mediumpreemptionHistory:- interval: endTime: '2026-06-23T07:00:00Z' startTime: '2026-03-25T07:00:00Z' preemptionRate: 0.0priceHistory:- interval: endTime: '2026-04-12T07:00:00Z' startTime: '2026-04-08T07:00:00Z' listPrice: currencyCode: USD nanos: 26752000- interval: endTime: '2026-06-16T07:00:00Z' startTime: '2026-04-12T07:00:00Z' listPrice: currencyCode: USD nanos: 27664000Utilisez capacity pour éclairer le choix de la zone et du type de machine avant provisionnement ; utilisez capacity-history pour évaluer la stabilité à plus long terme et la volatilité des prix lors de la conception d'une architecture de workload ou de la budgétisation FinOps.
Limites
- La disponibilité des TPU ne peut pas être interrogée via l'API
advice.capacity. - Les AI zones sont incluses par défaut dans les recommandations — vérifiez qu'elles sont bien activées pour votre projet avant d'exploiter ces recommandations.
- Pour interroger la disponibilité des VMs GPU N1 ou des disques Local SSD non rattachés par défaut à un type de machine, utilisez directement l'API REST.
- Les scores et estimations d'uptime ne sont pas des garanties ; la capacité peut évoluer entre le moment de la requête et celui de la création.
Bonnes pratiques
Comparez plusieurs types de machines. Si votre workload est flexible, comparez les résultats entre configurations — par exemple
100 × n1-standard-2contre50 × n1-standard-4. Retenez la configuration qui équilibre obtenabilité et uptime estimé selon vos besoins.Comparez plusieurs emplacements. Si votre workload peut s'exécuter dans plusieurs régions ou zones, vérifiez la disponibilité de chacune. À uptime estimé équivalent entre deux régions, privilégiez celle qui affiche le score d'obtenabilité le plus élevé.
Répartissez sur plusieurs zones. Avec une distribution
ANYouBALANCEDdans un MIG régional, l'API peut recommander de répartir les VMs entre plusieurs zones pour maximiser le succès de la création — par exemple 90 VMs dans une zone et 10 dans une autre, plutôt que 100 dans une seule.Réévaluez régulièrement. La disponibilité Spot évolue avec la demande à l'échelle de GCP. Intégrez un contrôle périodique de disponibilité à la gestion de vos MIG ou au cycle de revue de vos node pools GKE.
Synthèse
Provisionner des Spot VMs sans vérifier la disponibilité au préalable revient à conduire sans carte. L'API advice.capacity vous met cette carte entre les mains. Aucune bonne raison de sauter cette étape.
Avant de rédiger un instance template, avant de lancer terraform apply, avant de scaler un MIG — lancez la vérification. Elle vous dit si la zone pourra effectivement vous fournir des VMs, et combien de temps elles sont susceptibles de tenir. Ce signal doit guider votre choix de zone, votre choix de type de machine et votre intervalle de checkpoint.
Les Spot VMs restent l'un des meilleurs leviers d'économies sur GCP. La remise de 91 % est bien réelle. Le risque de préemption l'est tout autant — mais c'est désormais un risque connu et interrogeable, plus une inconnue.
Interrogez d'abord. Décidez sur signal. Concevez en fonction de l'uptime. Réévaluez à mesure que la demande évolue.