Con la diffusione sempre più ampia dell'architettura event-driven, alcune funzionalità assenti in Google Pub/Sub possono richiedere lo sviluppo di soluzioni alternative. Abbiamo deciso di condividere il nostro approccio a deduplica, messaggi ritardati e FIFO basato sui servizi nativi di Google Cloud.
Articolo scritto in collaborazione con Moshe Ohaion.

Introduzione
L'architettura event-driven è ormai così diffusa che giurerei di averne sentito parlare persino mia nonna l'altra sera a cena. Moltissime architetture di sistema fanno leva su servizi di messaggistica, sia come middleware orientato ai messaggi sia per l'ingestione e la consegna di eventi nelle pipeline di analisi in streaming. Su GCP (Google Cloud Platform) si può sfruttare il servizio gestito Google Pub/Sub proprio come sistema di ingestione e consegna degli eventi.
Google Pub/Sub offre funzionalità fondamentali come l'archiviazione durevole dei messaggi, la consegna in tempo reale ad alta disponibilità, prestazioni costanti su larga scala e la consegna at-least-once; come ogni servizio di messaggistica, però, presenta anche alcune lacune che possono pesare nella scelta di soluzioni alternative.
In questo articolo vogliamo condividere alcuni accorgimenti semplici per superare tre di questi "punti critici" senza rinunciare a Pub/Sub come scelta nativa su GCP.
Deduplica
Pub/Sub garantisce la consegna at-least-once (ma non exactly-once) dei messaggi: occasionali duplicati sono quindi da mettere in conto e possono generare diversi problemi:
- Integrità dei dati: si rischia di conteggiare due volte gli stessi dati.
- Invocazioni di processo superflue, con un impatto su prestazioni e costi.
I duplicati possono verificarsi per due motivi distinti:
- L'app non ha confermato (ack) il messaggio entro la deadline.
- Anche se il messaggio è stato confermato, Pub/Sub può comunque inviarlo più di una volta.
Per il primo caso, supponendo di non aver dimenticato di confermare i messaggi nel codice:
- Se il tempo di elaborazione di ciascun messaggio è sistematicamente superiore alla ACK deadline della subscription, conviene aumentarla per l'intera subscription.
- Se invece è un singolo messaggio a richiedere più tempo, si può ricorrere al metodo modify_ack_deadline su quel messaggio per estendere la sua ack deadline lato subscription.
Quando la duplicazione dipende dall'implementazione interna di Pub/Sub (caso più raro), conviene incanalare i messaggi attraverso un componente che si occupi della deduplica a monte. Pub/Sub assegna a ogni messaggio un `message_id` univoco, che il subscriber può usare per riconoscere i duplicati ricevuti.
Implementazione con Firestore
Implementazione con Redis (Memorystore)
Il codice del mio subscriber
Messaggi ritardati
Google Pub/Sub non implementa alcuna logica di consegna ritardata: i messaggi vengono consegnati il più rapidamente possibile.
Un'architettura message-driven si presta a generare un'esecuzione differita del codice senza dover implementare una logica di sospensione né invocare wait() all'interno dell'app.
Come si può quindi implementare il ritardo dei messaggi senza ricorrere a wait() nel codice?
Vediamo la nostra soluzione:
Abbiamo combinato l'API Cloud Tasks con una Cloud Function per creare task pianificati che inviano poi i messaggi all'applicazione App Engine (abbiamo scelto App Engine come target HTTP per Cloud Task).
Per creare una coda con il Cloud SDK è sufficiente il seguente comando gcloud:
gcloud tasks queues create delay-queue
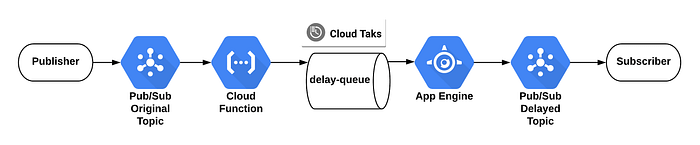
Diagramma dei messaggi ritardati
Gestiremo due topic in Pub/Sub:
- Il topic di origine, che riceverà tutti i messaggi dal Publisher.
- Il topic che riceverà tutti i messaggi ritardati.
Questa Cloud Function dovrà essere innescata dal topic di origine e accodare un cloud task pianificato:
Il codice di App Engine verrà attivato da Cloud Task al termine del ritardo e pubblicherà il messaggio sul topic finale:
Coda FIFO
Pub/Sub non implementa ancora alcuna logica di consegna ordinata (FIFO o per priorità).
I messaggi vengono consegnati il più rapidamente possibile, con una preferenza per quelli più vecchi, ma senza alcuna garanzia: un bel pasticcio! Questo design rende Pub/Sub problematico come trigger per workloads come ETL complessi, in cui l'ordine dei passaggi è cruciale.
Siamo riusciti ad abilitare un comportamento FIFO sfruttando Cloud Firestore per memorizzare lo stato della coda. Va però tenuto presente che soluzioni di questo tipo non sono pensate per flussi ad alto volume: l'ordinamento ha un costo in termini di prestazioni.
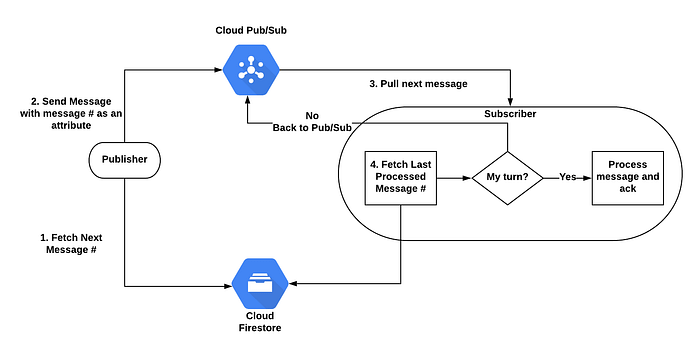
Diagramma del flusso FIFO
Cloud Firestore manterrà due contatori:
- Il numero del messaggio, che indica il prossimo numero da assegnare. Ogni volta che un publisher invia un messaggio, legge il valore, lo incrementa di 1 e lo allega al messaggio come attributo. Valore iniziale: 1.
- L'ultimo messaggio elaborato, che indica il numero dell'ultimo messaggio processato. Valore iniziale: 0.
Per ciascun messaggio, il publisher esegue le operazioni seguenti:
P.S. Il publisher potrebbe sollevare l'eccezione "Failed to commit transaction in 5 attempts" quando più publisher lavorano in parallelo a ritmo intenso. È possibile regolare il parametro di retry passando un argomento max_attempts alla chiamata client.transaction().
Il subscriber esegue le operazioni seguenti:
Ogni messaggio in arrivo rientra in tre possibili scenari:
- Tutti i messaggi precedenti sono già stati elaborati, quindi il messaggio corrente può essere processato (delta=1).
- Almeno uno dei messaggi precedenti non è ancora stato elaborato: il messaggio deve tornare in coda per un'elaborazione successiva (delta>1).
- Il messaggio è già stato elaborato: basta confermarlo (delta<1). Come abbiamo visto, i messaggi precedenti possono essere ritrasmessi per vari motivi.
Disclaimer: l'implementazione attuale garantisce che ogni messaggio non venga elaborato prima che il precedente sia stato elaborato almeno una volta. Significa che, in casi estremi, un messaggio duplicato potrebbe essere elaborato in parallelo al messaggio corrente. Per scongiurare del tutto questo scenario è necessario integrare la soluzione di deduplica presentata in precedenza.
Codice Firestore:
Perché Firestore?
Lato publisher, se il publisher è uno solo, la scelta del livello di persistenza è di fatto irrilevante. Con più publisher, invece, il livello di persistenza deve essere un sistema di archiviazione ACID come Cloud Firestore. Ogni publisher deve leggere e impostare il contatore in un'unica transazione, per evitare che due publisher inviino messaggi con lo stesso numero.
Lato subscriber, occorre assicurarsi che nessun altro subscriber abbia modificato il contatore Last Message Processed prima di impostare il nuovo valore.
Ci auguriamo che questo articolo vi sia utile. Restiamo a disposizione per commenti e domande.