Com a ascensão das arquiteturas orientadas a eventos, alguns recursos que faltam no Google Pub/Sub podem exigir a criação de soluções alternativas. Resolvemos compartilhar nossa abordagem para Deduplicação, Mensagens Agendadas e FIFO usando serviços nativos do Google Cloud.
Artigo escrito em coautoria com Moshe Ohaion.

Introdução
A arquitetura orientada a eventos virou assunto tão recorrente que tenho certeza de que ouvi até a minha avó comentar a respeito num jantar desses. Inúmeros sistemas usam serviços de mensageria, seja como middleware orientado a mensagens, seja para ingestão e entrega de eventos em pipelines de streaming analytics. No GCP (Google Cloud Platform), você pode tirar proveito do serviço gerenciado Google Pub/Sub para essa ingestão e entrega de eventos.
Embora o Google Pub/Sub entregue recursos críticos como armazenamento durável de mensagens, entrega em tempo real com alta disponibilidade, desempenho consistente em escala e entrega at-least-once, como qualquer serviço de mensageria, ele também deixa a desejar em alguns pontos que podem pesar na hora de avaliar alternativas.
Neste artigo, queremos mostrar formas simples de contornar três desses "impeditivos" sem abrir mão do GCP Pub/Sub como escolha nativa.
Deduplicação
O Pub/Sub garante entrega at-least-once (e não exactly-once), o que significa que duplicatas eventuais são esperadas e podem causar diversos problemas:
- Integridade dos dados — você pode acabar contando os mesmos dados duas vezes.
- Invocação desnecessária de processos, o que pode impactar desempenho e custo.
As duplicações podem acontecer por dois motivos:
- O app não confirmou (ack) a mensagem dentro do prazo.
- Mesmo que a mensagem tenha sido confirmada (ack), o Pub/Sub ainda pode enviá-la mais de uma vez.
No primeiro caso, presumindo que você não esqueceu de fazer ack das mensagens no código:
- Se o tempo de processamento de cada mensagem é consistentemente maior que o ACK deadline da subscription, aumente esse valor para a subscription inteira.
- Se uma mensagem específica demora mais para ser processada, use o método modify_ack_deadline nessa mensagem para estender o ack deadline dela do lado da subscription.
Quando a duplicação decorre da implementação interna do Pub/Sub (mais raro), encaminhe a mensagem antes por um componente que faça a deduplicação. O Pub/Sub atribui um `message_id` único a cada mensagem, e ele pode ser usado para detectar duplicatas recebidas pelo subscriber.
Implementação com Firestore
Implementação com Redis (Memorystore)
Meu código do subscriber
Mensagens Agendadas
O Google Pub/Sub não implementa nenhuma lógica de entrega com atraso. As mensagens são entregues o mais rápido possível.
É possível usar a arquitetura orientada a mensagens para gerar execução de código com atraso, evitando implementar uma lógica de suspensão e chamar wait() de dentro do app.
Mas como implementar mensagens agendadas sem usar wait() no código?
Veja a nossa solução:
Combinamos a Cloud Tasks API com uma Cloud Function para criar tarefas agendadas que, depois, fazem push de mensagens para o app no App Engine (escolhemos o App Engine como HTTP target do Cloud Task).
Para criar uma fila usando o Cloud SDK, rode o seguinte comando gcloud:
gcloud tasks queues create delay-queue
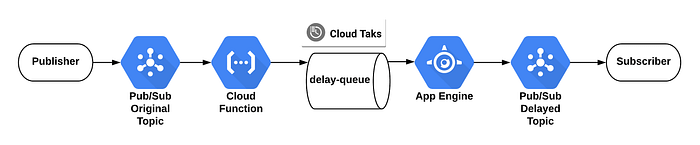
Diagrama de Mensagens Agendadas
Vou gerenciar dois tópicos no Pub/Sub:
- O tópico de origem, que recebe todas as mensagens do publisher.
- O tópico que recebe todas as mensagens com atraso.
Esta Cloud Function deve ser acionada pelo tópico de origem e inserir uma cloud task futura na fila:
O código no App Engine é acionado pelo Cloud Task após o atraso e publica a mensagem no tópico final:
Fila FIFO
O Pub/Sub ainda não implementa lógica de entrega ordenada (FIFO, prioridade).
As mensagens são entregues o mais rápido possível, dando preferência às mais antigas, mas sem garantia alguma — uma bela bagunça! Esse design torna o Pub/Sub problemático para servir de gatilho em workloads como ETLs complexos, em que a ordem das etapas importa.
Conseguimos habilitar o comportamento FIFO usando o Cloud Firestore para guardar o estado da fila. Vale lembrar que esse tipo de sistema não foi pensado para streams de alto volume, já que ordenar tem seu custo em desempenho.
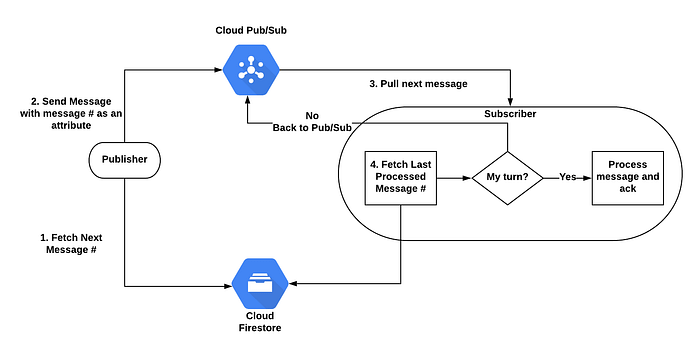
Diagrama de Fluxo FIFO
O Cloud Firestore vai manter dois contadores:
- O número da mensagem — indicando qual é o próximo número. Sempre que um publisher envia uma mensagem, ele lê o número, incrementa em 1 e o envia como atributo da mensagem. O valor inicial é 1.
- A última mensagem processada — indicando o número da última mensagem processada. O valor inicial é 0.
Para cada mensagem, o publisher executa o seguinte:
P.S.: o publisher pode lançar a exceção "Failed to commit transaction in 5 attempts" se vários publishers trabalharem em paralelo de forma intensa. Dá para controlar o parâmetro de retry passando o argumento max_attempts na chamada do método client.transaction().
O subscriber executa o seguinte:
Cada mensagem que chega tem três caminhos possíveis:
- Todas as mensagens anteriores foram processadas, então a mensagem atual pode ser processada (delta=1).
- Pelo menos uma mensagem anterior ainda não foi processada, então a mensagem volta para a fila e é processada depois (delta>1).
- Esta mensagem já foi processada, então basta fazer o ack dela (delta<1). Como já comentamos, mensagens anteriores podem ser retransmitidas por diversos motivos.
Aviso: a implementação atual garante que cada mensagem só seja processada depois que a anterior tiver sido processada ao menos uma vez. Em casos extremos, isso pode levar a uma situação em que uma mensagem duplicada é processada em paralelo à atual. Para eliminar esse cenário por completo, integre a solução de deduplicação que apresentei antes.
Código do Firestore:
Por que Firestore?
No lado do publisher, quando há apenas um publisher, tanto faz a camada de persistência. Já com múltiplos publishers, a camada de persistência precisa ser um sistema de armazenamento ACID, como o Cloud Firestore. Cada publisher precisa fazer get e set do contador em uma única transação para evitar que dois publishers enviem mensagens com o mesmo número.
No lado do subscriber, é preciso garantir que outros subscribers não tenham alterado o contador da Última Mensagem Processada antes que ele defina o novo valor.
Espero que este post seja útil para você. Fico no aguardo dos seus comentários e dúvidas.