Avec la popularité croissante des architectures événementielles, certaines fonctionnalités manquantes de Google Pub/Sub imposent parfois de mettre en place des contournements. Nous avons voulu partager notre approche pour la déduplication, les messages différés et les solutions FIFO en nous appuyant sur des services natifs de Google Cloud.
Cet article a été co-écrit avec Moshe Ohaion.

Introduction
L'architecture événementielle est tellement en vogue ces temps-ci que je suis sûr d'avoir entendu ma grand-mère en parler à table l'autre soir. Beaucoup d'architectures système s'appuient sur des services de messagerie, que ce soit comme middleware orienté messages ou pour l'ingestion et la diffusion d'événements dans des pipelines d'analyse en streaming. Sur GCP (Google Cloud Platform), vous pouvez tirer parti du service managé Google Pub/Sub pour l'ingestion et la diffusion d'événements.
Si Google Pub/Sub propose des fonctionnalités essentielles comme le stockage durable des messages, la diffusion en temps réel à haute disponibilité, des performances constantes à grande échelle et une diffusion at-least-once, il présente, comme tout service de messagerie, plusieurs lacunes susceptibles de peser dans le choix d'une alternative.
Dans cet article, nous vous proposons quelques moyens simples de contourner trois de ces dealbreakers tout en restant sur le choix natif GCP Pub/Sub.
Déduplication
Pub/Sub garantit une diffusion at-least-once (mais pas exactly-once), ce qui signifie qu'il faut s'attendre à des doublons occasionnels et que cela peut soulever plusieurs problèmes :
- Intégrité des données — vous risquez de comptabiliser deux fois les mêmes données.
- Invocations de processus inutiles, avec un impact possible sur les performances et les coûts.
Les doublons peuvent survenir pour deux raisons :
- L'application n'a pas acquitté (ack) le message dans le délai imparti.
- Même si le message a été acquitté, Pub/Sub peut tout de même l'envoyer plusieurs fois.
Pour le premier cas, en supposant que vous n'ayez pas oublié d'acquitter les messages dans votre code :
- Si le temps de traitement de chaque message dépasse régulièrement le délai d'ACK de l'abonnement, augmentez-le pour l'ensemble de l'abonnement.
- Si un message précis demande plus de temps, utilisez la méthode modify_ack_deadline sur ce message pour prolonger son délai d'acquittement côté abonnement.
Lorsque la duplication résulte de l'implémentation interne de Pub/Sub (cas plus rare), il faut faire transiter le flux par un composant qui assure d'abord la déduplication. Pub/Sub attribue à chaque message un `message_id` unique, qui permet à l'abonné de détecter les doublons.
Implémentation Firestore
Implémentation Redis (Memorystore)
Mon code abonné
Messages différés
Google Pub/Sub n'implémente aucune logique de diffusion différée. Les messages sont diffusés aussi rapidement que possible.
L'architecture orientée messages permet de déclencher une exécution différée du code sans avoir à mettre en place une logique de suspension ni à appeler wait() depuis l'application.
Alors comment mettre en place des messages différés sans utiliser wait() dans notre code ?
Voyons notre solution :
Nous avons combiné l'API Cloud Tasks et Cloud Function pour créer des tâches programmées qui transmettent ensuite les messages à l'application App Engine (nous avons retenu App Engine comme cible HTTP de Cloud Task).
Pour créer une file d'attente avec le SDK Cloud, exécutez la commande gcloud suivante :
gcloud tasks queues create delay-queue
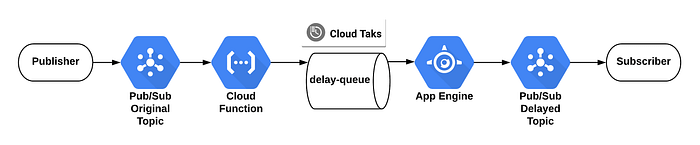
Schéma des messages différés
Je vais gérer deux topics dans Pub/Sub :
- Le topic d'origine, qui reçoit tous les messages du Publisher
- Le topic qui reçoit tous les messages différés.
Cette Cloud Function doit être déclenchée par le topic d'origine et insérer une future cloud task dans la file :
Le code App Engine sera déclenché par Cloud Task après le délai et publiera le message sur le topic final :
File FIFO
Pub/Sub n'implémente pas encore de logique de diffusion ordonnée (FIFO, priorité).
Les messages sont diffusés aussi vite que possible, avec une préférence pour les plus anciens, mais sans garantie — quel joyeux bazar ! Cette conception rend Pub/Sub peu adapté comme déclencheur pour des workloads tels que des ETL complexes où l'ordre des étapes est essentiel.
Nous avons réussi à obtenir un comportement FIFO en nous appuyant sur Cloud Firestore pour conserver l'état de la file. Gardez à l'esprit que ce type de système n'est pas prévu pour absorber des flux à fort volume, car l'ordonnancement a un coût en matière de performances.
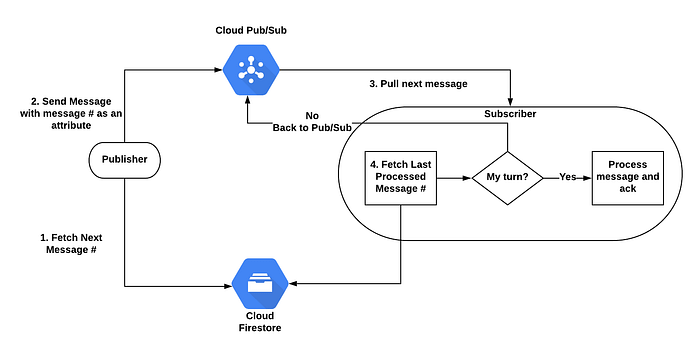
Schéma de flux FIFO
Cloud Firestore conserve deux compteurs :
- Le numéro de message — qui indique le numéro du prochain message. Chaque fois qu'un publisher envoie un message, il récupère ce numéro, l'incrémente de 1 et le transmet comme attribut du message. La valeur initiale est 1.
- Le dernier message traité — qui indique le numéro du dernier message traité. La valeur initiale est 0.
Pour chaque message, le publisher effectue les opérations suivantes :
P.S. Le publisher peut lever une exception Failed to commit transaction in 5 attempts lorsque plusieurs publishers travaillent intensivement en parallèle. Vous pouvez ajuster le paramètre de retry en passant l'argument max_attempts à l'appel de la méthode client.transaction().
L'abonné effectue les opérations suivantes :
Chaque message reçu correspond à l'un des trois cas suivants :
- Tous les messages précédents ont été traités : le message courant peut donc l'être à son tour (delta=1).
- Au moins un message précédent n'a pas encore été traité : le message doit donc retourner dans la file pour un traitement ultérieur (delta>1).
- Ce message a déjà été traité : il suffit donc de l'acquitter (delta<1). Comme évoqué, des messages antérieurs peuvent être retransmis pour diverses raisons.
Avertissement : l'implémentation actuelle garantit qu'aucun message ne sera traité avant que le précédent ne l'ait été au moins une fois. Cela signifie que, dans des cas extrêmes, un message dupliqué peut être traité en parallèle du message courant. Pour écarter totalement ce risque, intégrez la solution de déduplication présentée plus haut.
Code Firestore :
Pourquoi Firestore ?
Côté publisher, lorsqu'il n'y a qu'un seul publisher, le choix de la couche de persistance importe peu. En revanche, dès qu'il y a plusieurs publishers, cette couche doit être un système de stockage ACID, tel que Cloud Firestore. Chaque publisher doit lire et mettre à jour le compteur dans une même transaction afin d'éviter que deux messages portent le même numéro.
Côté abonné, il faut s'assurer qu'aucun autre abonné n'a modifié le compteur Last Message Processed avant d'écrire la nouvelle valeur.
J'espère que cet article vous sera utile. Vos commentaires et questions sont les bienvenus.