Con la creciente popularidad de las arquitecturas basadas en eventos, algunas funciones ausentes en Google Pub/Sub pueden requerir ciertas soluciones alternativas. Queremos compartir nuestro enfoque para implementar deduplicación, mensajes diferidos y FIFO con servicios nativos de Google Cloud.
Este artículo se escribió en colaboración con Moshe Ohaion.

Introducción
La arquitectura basada en eventos está tan de moda hoy en día que juraría que hasta mi abuela la mencionó la otra noche durante la cena. Muchísimas arquitecturas de sistemas se apoyan en servicios de mensajería, ya sea como middleware orientado a mensajes o como sistema de ingesta y entrega de eventos para pipelines de analítica en streaming. Si trabajas en GCP (Google Cloud Platform), puedes aprovechar el servicio gestionado Google Pub/Sub como sistema de ingesta y entrega de eventos.
Si bien Google Pub/Sub ofrece funciones críticas como almacenamiento duradero de mensajes, entrega en tiempo real con alta disponibilidad, rendimiento consistente a escala y entrega "al menos una vez", como todo servicio de mensajería también tiene varias funciones ausentes que podrían inclinar la balanza hacia otras alternativas.
En este artículo queremos compartir contigo algunas formas sencillas de superar tres de estos "dealbreakers" sin renunciar a la opción nativa de GCP Pub/Sub.
Deduplicación
Pub/Sub garantiza la entrega "al menos una vez" (pero no exactamente una vez), lo que significa que es esperable que ocurran duplicados de manera ocasional, y esto puede generar varios problemas:
- Integridad de los datos: puedes terminar contando los datos dos veces.
- Invocación innecesaria de procesos, lo que puede afectar el rendimiento y el costo.
Las duplicaciones pueden ocurrir por dos razones distintas:
- La aplicación no confirmó (ack) el mensaje dentro del plazo establecido.
- Aunque el mensaje haya sido confirmado, Pub/Sub puede enviarlo más de una vez igualmente.
Respecto al primer caso, asumiendo que no olvidaste hacer ack a los mensajes en tu código:
- Si el tiempo de procesamiento de cada mensaje es consistentemente mayor que el ACK deadline de la suscripción, auméntalo para toda la suscripción.
- Si un mensaje específico tarda más en procesarse, puedes usar el método modify_ack_deadline sobre ese mensaje para extender su ack deadline del lado de la suscripción.
Cuando la duplicación se debe a la implementación interna de Pub/Sub (algo más raro), conviene canalizarlo primero a través de un componente que lo deduplique. Pub/Sub asigna un `message_id` único a cada mensaje, que sirve para detectar mensajes duplicados recibidos por el suscriptor.
Implementación con Firestore
Implementación con Redis (Memorystore)
Mi código del suscriptor
Mensajes diferidos
Google Pub/Sub no implementa ninguna lógica para la entrega diferida. Los mensajes se entregan lo más rápido posible.
La arquitectura basada en mensajes puede usarse para diferir la ejecución de código, evitando implementar lógica de suspensión y llamadas a wait() desde la propia app.
Entonces, ¿cómo implementar mensajes diferidos sin usar wait() en nuestro código?
Veamos nuestra solución a este problema:
Usamos la API de Cloud Tasks junto con Cloud Functions para crear tareas programadas que luego envían mensajes a la app de App Engine (elegimos App Engine como nuestro destino HTTP para Cloud Task).
Para crear una cola con el Cloud SDK, usa el siguiente comando gcloud:
gcloud tasks queues create delay-queue
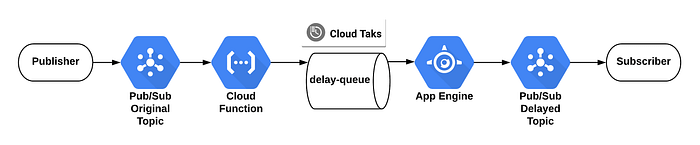
Diagrama de mensajería diferida
Voy a manejar dos topics en Pub/Sub:
- El topic de origen, que recibirá todos los mensajes del Publisher.
- El topic que recibirá todos los mensajes diferidos.
Esta Cloud Function debe activarse desde el topic de origen e insertar una cloud task futura en la cola:
El código de App Engine se activará desde Cloud Task tras el retraso y publicará el mensaje en el topic final:
Cola FIFO
Pub/Sub aún no implementa ninguna lógica para la entrega ordenada (FIFO, prioridad).
Los mensajes se entregan lo más rápido posible, dando preferencia a los más antiguos, pero esto no está garantizado: ¡vaya lío! Este diseño hace que Pub/Sub sea problemático como disparador de workloads como ETLs complejos, donde el orden de los pasos es importante.
Logramos habilitar el comportamiento FIFO usando Cloud Firestore para guardar el estado de la cola. Ten en cuenta que este tipo de sistemas no está pensado para manejar streams de alto volumen, ya que el ordenamiento tiene un costo en términos de rendimiento.
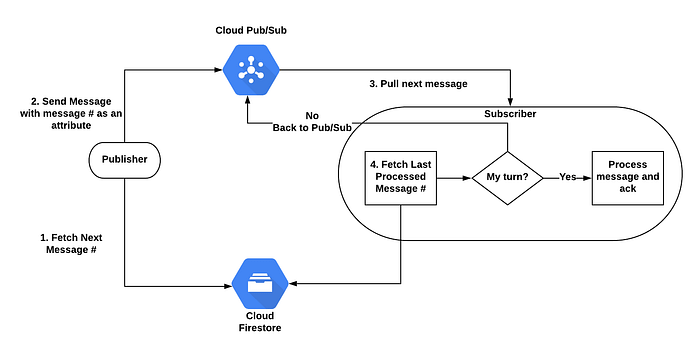
Diagrama de flujo FIFO
Cloud Firestore mantendrá dos contadores:
- El número de mensaje: indica cuál es el próximo número de mensaje. Cada vez que un publisher envía un mensaje, obtiene el número, lo incrementa en 1 y lo envía como atributo del mensaje. El valor inicial es 1.
- El último mensaje procesado: indica el número del último mensaje que se procesó. El valor inicial es 0.
Por cada mensaje, el publisher hace lo siguiente:
P.D. El publisher podría lanzar la excepción "Failed to commit transaction in 5 attempts" cuando varios publishers trabajan intensivamente en paralelo. Puedes controlar el parámetro de reintento pasando un argumento max_attempts al método client.transaction().
El suscriptor hace lo siguiente:
Cada mensaje que llega tiene tres opciones:
- Todos los mensajes anteriores se procesaron, así que el mensaje actual puede procesarse (delta=1).
- Al menos un mensaje anterior aún no se procesó, por lo que el mensaje debe volver a la cola para procesarse más tarde (delta>1).
- Este mensaje ya se procesó, así que solo hace falta hacerle ack (delta<1). Como ya comentamos, los mensajes anteriores podrían retransmitirse por diversas razones.
Aviso: La implementación actual garantiza que un mensaje no se procese antes de que el anterior se haya procesado al menos una vez. Esto significa que, en casos extremos, puede darse una situación en la que un mensaje duplicado se procese en paralelo al mensaje actual. Para evitar este estado por completo, debes integrar la solución de deduplicación que presenté antes.
Código de Firestore:
¿Por qué Firestore?
Del lado del publisher, cuando solo hay uno, no importa demasiado qué capa de persistencia elijas. Si hay varios publishers, la capa de persistencia debe ser un sistema de almacenamiento ACID, como Cloud Firestore. Cada publisher debe obtener y actualizar el contador en una sola transacción para evitar que varios publishers envíen mensajes con el mismo número.
Del lado del suscriptor, este debe asegurarse de que otros suscriptores no hayan modificado el contador de Último Mensaje Procesado antes de establecer el nuevo valor.
Espero que este post te resulte útil. Quedo atento a tus comentarios y a cualquier duda que tengas.