Descubre cómo funciona Amazon Aurora DSQL y si se ajusta a lo que necesitas. Conoce su arquitectura distribuida, los patrones de datos ideales y cómo rompe con las limitaciones de las bases de datos tradicionales.

Amazon Aurora DSQL (Distributed SQL) plantea un nuevo enfoque para las bases de datos relacionales: se apoya en una arquitectura SQL distribuida para ofrecer alta escalabilidad, disponibilidad robusta y soporte fluido para transacciones distribuidas. Adoptar Aurora DSQL pide más que entusiasmo (y sí, algo entusiasmado estoy; ya me pidieron bajarle el tono a este blog): exige entender bien cómo opera y si tus patrones de datos encajan con sus capacidades.
En este blog veremos cómo funciona Aurora DSQL, repasaremos los patrones de datos que mejor rinden en su entorno y analizaremos cómo saber si encaja con tus workloads.
¿Cómo funciona Aurora DSQL?
La fuerza de Aurora DSQL viene de su diseño innovador, que separa los componentes de la base de datos en servicios independientes y escalables. Apoyándose en la enorme velocidad y ancho de banda de las redes cloud modernas y en una arquitectura distribuida, Aurora DSQL logra un equilibrio entre escalabilidad, rendimiento y consistencia. Empecemos con un diagrama de arquitectura de alto nivel que muestra los 5 componentes de Aurora DSQL:
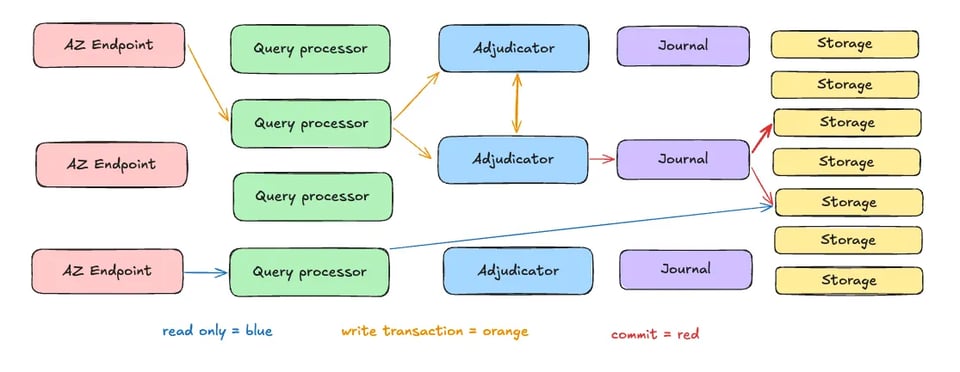
Arquitectura desagregada
Aurora DSQL separa la ejecución de consultas, la gestión de transacciones y el almacenamiento en servicios especializados:
- Capa de ejecución de consultas: ejecuta consultas SQL en paralelo y escala horizontalmente a medida que crece la demanda.
- Capa de gestión de transacciones: coordina las transacciones distribuidas con técnicas como el bloqueo optimista para garantizar la consistencia.
- Capa de almacenamiento: un sistema distribuido shared-nothing que replica los datos en varios nodos para asegurar durabilidad y tolerancia a fallos.
Cada servicio se diseñó para escalar de forma independiente, de modo que el sistema pueda manejar workloads de distinta intensidad sin cuellos de botella.
MicroVMs para aislar las transacciones
Aurora DSQL ejecuta cada transacción en su propia microVM, lo que brinda un aislamiento total. Esta arquitectura elimina la contención entre transacciones, sobre todo en estos casos:
- Workloads con muchas lecturas: las lecturas no provocan bloqueos ni generan undo logs, así que resultan ligeras y rápidas.
- Transacciones concurrentes: pueden ejecutarse al mismo tiempo sin interferir entre sí, lo que permite alta concurrencia.
Bloqueo optimista
El modelo de transacciones de Aurora DSQL se apoya en el bloqueo optimista:
- Las transacciones parten del supuesto de que la contención es mínima y solo verifican si hay conflictos en el momento del commit.
- Si se detecta un conflicto (por ejemplo, otra transacción modificó los mismos datos), la transacción falla y la aplicación debe reintentarla.
El bloqueo optimista rinde mejor con workloads de baja contención de escrituras, pero exige una lógica de reintento sólida cuando la contención es mayor.
El Adjudicator y el Journal
Hay componentes clave de la arquitectura que aseguran la consistencia y la durabilidad de Aurora DSQL:
- Adjudicator: impone un orden de commit globalmente consistente para las transacciones, resolviendo conflictos y manteniendo una consistencia fuerte.
- Journal: un log distribuido que registra los cambios de las transacciones, aportando durabilidad y permitiendo la recuperación ante fallos.
¿Qué patrones de datos funcionan mejor con Aurora DSQL?
Aurora DSQL se luce con ciertos patrones de datos, sobre todo aquellos que se alinean con su naturaleza distribuida y desagregada. Veamos en detalle los patrones que mejor encajan y cómo identificarlos en tu workload.
1. Workloads de alta concurrencia
Aurora DSQL es ideal para aplicaciones con muchos usuarios o procesos concurrentes, como:
- Plataformas de e-commerce: gestión simultánea de transacciones para actualizar inventario, procesar compras y registrar la actividad de los usuarios.
- Aplicaciones de redes sociales: manejo de likes, comentarios e interacciones de millones de usuarios activos.
- Aplicaciones SaaS: soporte para múltiples clientes con workloads aislados que comparten la misma infraestructura de base de datos.
Para identificar si tu workload encaja en este patrón:
- Revisa tus picos de usuarios concurrentes y la actividad de consultas.
- Analiza si la contención (por ejemplo, varios procesos escribiendo sobre los mismos datos) se puede manejar con bloqueo optimista.
2. Aplicaciones con muchas lecturas
Como en Aurora DSQL las lecturas no generan bloqueos ni undo, los workloads dominados por lecturas rinden excepcionalmente bien. Algunos ejemplos:
- Dashboards y analítica: aplicaciones donde los datos se consultan en tiempo real con mucha más frecuencia de lo que se escriben.
- Plataformas de distribución de contenido: aplicaciones de streaming o de noticias donde los usuarios principalmente consumen contenido.
Para evaluar tu proporción de lecturas y escrituras:
- Monitorea los logs de consultas y mira qué porcentaje corresponde a operaciones de lectura frente a escrituras.
- Usa los performance insights de Aurora u otras herramientas de monitoreo para medir la latencia y el throughput de las consultas de lectura.
3. Acceso a datos distribuido geográficamente
La naturaleza distribuida de Aurora DSQL la convierte en una gran opción para aplicaciones con usuarios globales:
- Plataformas de gaming: juegos multijugador donde jugadores de distintas regiones interactúan en tiempo real.
- Herramientas de colaboración: aplicaciones de chat o de compartición de documentos que requieren acceso de baja latencia entre continentes.
Para identificar este patrón:
- Mapea tu base de usuarios geográficamente y determina si las consultas sensibles a la latencia provienen de varias regiones.
- Evalúa si una base de datos centralizada está provocando problemas de latencia para los usuarios más lejanos.
4. Workloads de escritura con baja contención
El bloqueo optimista de Aurora DSQL se luce cuando la contención de escrituras es baja. Algunos ejemplos:
- Datos particionados: aplicaciones donde las escrituras quedan naturalmente aisladas en particiones específicas, como actualizaciones por usuario o por tenant.
- Logging de eventos: sistemas donde los eventos se escriben de forma independiente y con mínima superposición.
Para verificar si tu workload encaja:
- Analiza las operaciones de escritura y revisa si suelen apuntar a las mismas filas u objetos.
- Busca oportunidades de partición natural en tu esquema (por ejemplo, sharding por ID de usuario o por tenant).
5. Procesamiento híbrido transaccional y analítico (HTAP)
Las aplicaciones que combinan consultas transaccionales y analíticas aprovechan la capacidad de Aurora DSQL para manejar ambos workloads con eficiencia:
- Dashboards financieros: combinan actualizaciones de transacciones en tiempo real con resúmenes analíticos.
- Sistemas de inventario: permiten actualizaciones operativas y, al mismo tiempo, ofrecen visibilidad inmediata de los niveles de stock.
Para confirmar este patrón:
- Identifica workloads que combinen actualizaciones en tiempo real con consultas analíticas.
- Asegúrate de que las consultas analíticas de larga duración se puedan optimizar para entrar en el timeout de consulta de 5 minutos de Aurora DSQL.
¿Es Aurora DSQL la opción adecuada para ti?
Aurora DSQL es un sistema de base de datos potente para aplicaciones modernas que necesitan escalar horizontalmente sin perder consistencia. Se luce con workloads de alta concurrencia, dominados por lecturas, particionables y distribuidos globalmente. Eso sí, puede requerir un diseño cuidadoso del esquema y de la lógica de aplicación para manejar limitaciones como el bloqueo optimista y los timeouts de consulta.
Al analizar tus patrones de datos y alinearlos con las fortalezas de Aurora DSQL, podrás determinar si esta innovadora base de datos distribuida es la opción correcta para ti. Con el diseño adecuado, Aurora DSQL puede ofrecer una escalabilidad, un rendimiento y una resiliencia sin igual para tu aplicación.
¿Tienes preguntas sobre cómo aplicar Aurora DSQL en tu organización?
Si todavía te preguntas cómo aplicar estas ideas para sacarle el máximo partido a Aurora DSQL —o a cualquier otra solución de datos en GCP o AWS— en tu organización, estamos para ayudarte.
En DoiT contamos exclusivamente con talento senior de Engineering. Nos especializamos en consultoría cloud avanzada, diseño arquitectónico y servicios de debugging. Ya sea que estés planeando tus primeros pasos con bases de datos distribuidas, optimizando un sistema existente o resolviendo problemas complejos, te damos asesoría experta y a la medida.
Escríbenos hoy y deja que te ayudemos a aprovechar todo el potencial de tu infraestructura cloud.