Scopra come funziona Amazon Aurora DSQL e se risponde alle sue esigenze. Vediamo l'architettura distribuita, i pattern di dati ideali e come questa soluzione supera i limiti dei database tradizionali.

Amazon Aurora DSQL (Distributed SQL) propone un nuovo approccio ai database relazionali: sfrutta un'architettura SQL distribuita per garantire scalabilità elevata, disponibilità solida e supporto nativo alle transazioni distribuite. Adottare Aurora DSQL non è solo questione di entusiasmo (e un po' di entusiasmo ce l'ho, tanto che mi è già stato chiesto di abbassare i toni in questo articolo): serve capire chiaramente come funziona e se i suoi pattern di dati ne valorizzano davvero le caratteristiche.
In questo articolo vedremo come funziona Aurora DSQL, quali sono i pattern di dati che meglio si prestano al suo ambiente e come capire se è la scelta giusta per i suoi workloads.
Come funziona Aurora DSQL?
La forza di Aurora DSQL nasce da un design innovativo, che scompone i componenti del database in servizi indipendenti e scalabili. Sfruttando la velocità e la banda del networking cloud moderno insieme a un'architettura distribuita, Aurora DSQL trova un equilibrio tra scalabilità, performance e coerenza. Partiamo da un diagramma architetturale ad alto livello che mostra i 5 componenti principali di Aurora DSQL:
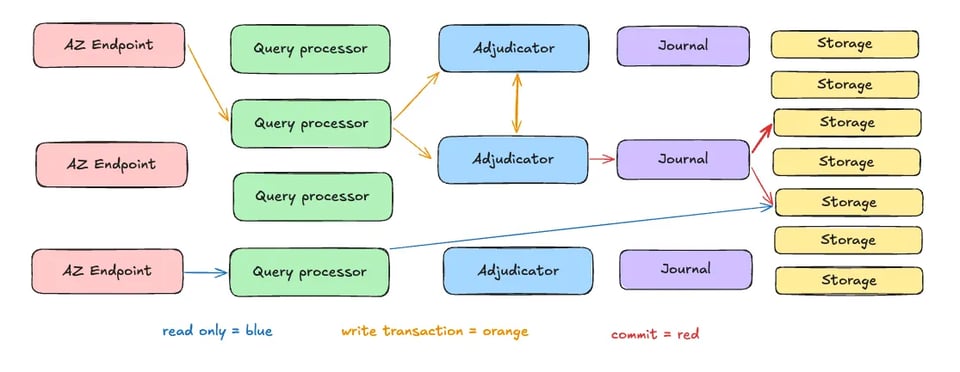
Architettura disaggregata
Aurora DSQL separa l'esecuzione delle query, la gestione delle transazioni e lo storage in servizi specializzati:
- Query Execution Layer: esegue le query SQL in parallelo, scalando orizzontalmente al crescere della domanda.
- Transaction Management Layer: coordina le transazioni distribuite con tecniche come l'optimistic locking per garantire la coerenza.
- Storage Layer: un sistema distribuito shared-nothing che replica i dati su più nodi per durabilità e tolleranza ai guasti.
Ogni servizio è progettato per scalare in modo autonomo, così il sistema gestisce workloads di intensità variabile senza colli di bottiglia.
MicroVM per l'isolamento delle transazioni
Aurora DSQL esegue ogni transazione in una propria microVM, garantendo un isolamento totale. Un'architettura che elimina la contesa tra transazioni, soprattutto per:
- Workloads a forte intensità di lettura: le letture non generano locking né undo log, e risultano leggere e veloci.
- Transazioni concorrenti: più transazioni vengono eseguite in parallelo senza interferenze, con un'elevata concorrenza.
Optimistic Locking
Il modello transazionale di Aurora DSQL si basa sull'optimistic locking:
- Le transazioni assumono una contesa minima e verificano i conflitti soltanto al momento del commit.
- Se viene rilevato un conflitto (ad esempio, un'altra transazione ha modificato gli stessi dati), la transazione fallisce e l'applicazione deve effettuare un nuovo tentativo.
L'optimistic locking dà il meglio con workloads a bassa contesa in scrittura, ma richiede una logica di retry solida negli scenari ad alta contesa.
Adjudicator e Journal
Due componenti architetturali chiave assicurano coerenza e durabilità in Aurora DSQL:
- Adjudicator: impone un ordine di commit globalmente coerente per le transazioni, risolvendo i conflitti e mantenendo una strong consistency.
- Journal: un log distribuito che registra le modifiche delle transazioni, garantendo durabilità e abilitando il recovery in caso di guasto.
Quali pattern di dati funzionano meglio con Aurora DSQL?
Aurora DSQL eccelle con specifici pattern di dati, in particolare con quelli affini alla sua natura distribuita e disaggregata. Vediamo da vicino i pattern che ne valorizzano i punti di forza e come riconoscerli nei suoi workloads.
1. Workloads ad alta concorrenza
Aurora DSQL è ideale per applicazioni con molti utenti o processi concorrenti, ad esempio:
- Piattaforme e-commerce: gestione di transazioni simultanee per aggiornamenti di magazzino, acquisti e attività degli utenti.
- Applicazioni di social media: gestione di like, commenti e interazioni su milioni di utenti attivi.
- Applicazioni SaaS: supporto a più clienti con workloads isolati pur condividendo la stessa infrastruttura di database.
Per capire se i suoi workloads rientrano in questo pattern:
- Verifichi i picchi di utenti concorrenti e l'attività di query.
- Valuti se la contesa (ad esempio più processi che scrivono sugli stessi dati) sia gestibile con l'optimistic locking.
2. Applicazioni a forte intensità di lettura
Poiché in Aurora DSQL le letture non generano lock né undo, i workloads a forte intensità di lettura offrono performance eccezionali. Alcuni esempi:
- Dashboard e analytics: applicazioni in cui gli aggiornamenti dei dati in tempo reale vengono consultati molto più spesso di quanto vengano scritti.
- Piattaforme di content delivery: applicazioni di streaming o di news in cui gli utenti per lo più consumano contenuti.
Per valutare il rapporto tra letture e scritture:
- Monitori i log delle query per misurare la percentuale di operazioni di lettura rispetto alle scritture.
- Utilizzi i performance insights di Aurora o gli strumenti di monitoraggio del database per misurare latenza e throughput delle query di lettura.
3. Accesso ai dati distribuito geograficamente
La natura distribuita di Aurora DSQL la rende perfetta per applicazioni rivolte a un pubblico globale:
- Piattaforme di gaming: giochi multiplayer in cui giocatori di regioni diverse interagiscono in tempo reale.
- Strumenti di collaborazione: condivisione di documenti o chat che richiedono accesso a bassa latenza tra continenti.
Per riconoscere questo pattern:
- Mappi la base utenti dal punto di vista geografico e verifichi se le query sensibili alla latenza provengono da più regioni.
- Valuti se un database centralizzato genera problemi di latenza per gli utenti più distanti.
4. Workloads di scrittura a bassa contesa
L'optimistic locking di Aurora DSQL brilla quando la contesa in scrittura è bassa. Alcuni esempi:
- Dati partizionati: applicazioni in cui le scritture sono per natura isolate su partizioni specifiche, come gli aggiornamenti per utente o per tenant.
- Event logging: sistemi in cui gli eventi vengono scritti in modo indipendente, con sovrapposizioni minime.
Per capire se i suoi workloads sono adatti:
- Analizzi le operazioni di scrittura per verificare se interessano spesso le stesse righe o gli stessi oggetti.
- Cerchi nello schema opportunità naturali di partizionamento (ad esempio sharding per user ID o per tenant).
5. Hybrid Transactional and Analytical Processing (HTAP)
Le applicazioni che combinano query transazionali e analitiche traggono vantaggio dalla capacità di Aurora DSQL di gestire in modo efficiente entrambi i workloads:
- Dashboard finanziarie: uniscono aggiornamenti di transazioni in tempo reale a sintesi analitiche.
- Sistemi di gestione del magazzino: consentono aggiornamenti operativi e, allo stesso tempo, offrono insight immediati sui livelli di stock.
Per confermare questo pattern:
- Identifichi i workloads che combinano aggiornamenti in tempo reale e query analitiche.
- Verifichi che le query analitiche di lunga durata possano essere ottimizzate per rientrare nel timeout di query di 5 minuti di Aurora DSQL.
Aurora DSQL fa al caso suo?
Aurora DSQL è un database potente per le applicazioni moderne che devono scalare orizzontalmente mantenendo la coerenza. Dà il meglio con workloads ad alta concorrenza, a forte intensità di lettura, partizionabili e distribuiti a livello globale. Va però messo in conto che limiti come l'optimistic locking e i timeout delle query richiedono una progettazione attenta dello schema e della logica applicativa.
Analizzando i suoi pattern di dati e confrontandoli con i punti di forza di Aurora DSQL potrà capire se questo innovativo database distribuito è la scelta giusta. Con il design corretto, Aurora DSQL offre alla sua applicazione scalabilità, performance e resilienza senza pari.
Domande su come integrare Aurora DSQL nella sua organizzazione?
Se si sta ancora chiedendo come tradurre questi spunti in valore concreto con Aurora DSQL — o con qualsiasi altra soluzione dati GCP o AWS — siamo qui per aiutarla.
In DoiT il nostro team è composto esclusivamente da Engineers senior. Siamo specializzati in consulenza cloud avanzata, progettazione architetturale e servizi di debugging. Che si tratti di muovere i primi passi con i database distribuiti, ottimizzare un sistema esistente o risolvere problemi complessi, offriamo consulenza esperta e su misura.
Ci contatti oggi stesso e la aiuteremo a sfruttare appieno il potenziale della sua infrastruttura cloud.