Descubra como o Amazon Aurora DSQL funciona e se ele atende às suas necessidades. Conheça a arquitetura distribuída, os padrões de dados ideais e como ele rompe com as limitações dos bancos de dados tradicionais.

O Amazon Aurora DSQL (Distributed SQL) traz uma nova abordagem para bancos de dados relacionais: aproveita uma arquitetura SQL distribuída para entregar alta escalabilidade, disponibilidade robusta e suporte transparente a transações distribuídas. Adotar o Aurora DSQL pede mais do que entusiasmo (e confesso que estou um pouco animado; já me pediram para baixar o tom deste post) — pede um entendimento claro de como ele opera e se os seus padrões de dados realmente combinam com o que ele oferece.
Neste post, vamos nos aprofundar em como o Aurora DSQL funciona, explorar os padrões de dados que se dão bem nesse ambiente e ajudar você a decidir se ele faz sentido para os seus workloads.
Como o Aurora DSQL funciona?
A força do Aurora DSQL vem do seu design inovador, que desagrega os componentes do banco em serviços independentes e escaláveis. Combinando a enorme velocidade e largura de banda das redes modernas em nuvem com uma arquitetura distribuída, o Aurora DSQL equilibra escalabilidade, desempenho e consistência. Vamos começar com um diagrama de arquitetura em alto nível, mostrando os 5 componentes do Aurora DSQL:
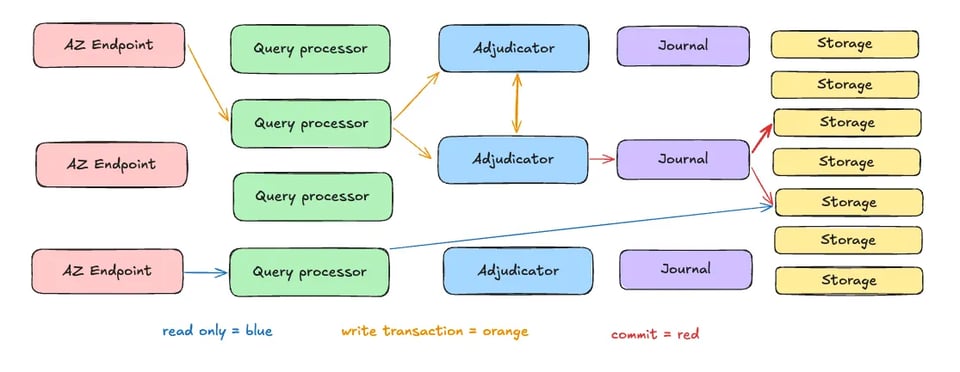
Arquitetura desagregada
O Aurora DSQL separa execução de consultas, gerenciamento de transações e armazenamento em serviços especializados:
- Camada de execução de consultas: roda consultas SQL em paralelo, escalando horizontalmente conforme a demanda cresce.
- Camada de gerenciamento de transações: coordena transações distribuídas usando técnicas como bloqueio otimista para garantir consistência.
- Camada de armazenamento: um sistema distribuído shared-nothing que replica os dados em vários nós, garantindo durabilidade e tolerância a falhas.
Cada serviço foi pensado para escalar de forma independente, garantindo que o sistema dê conta de workloads de intensidades variadas sem gargalos.
MicroVMs para isolamento de transações
O Aurora DSQL roda cada transação na sua própria microVM, oferecendo isolamento total. Essa arquitetura elimina contenção entre transações, principalmente em:
- Workloads com leitura intensa: as leituras não geram bloqueios nem logs de undo, ficando leves e rápidas.
- Transações concorrentes: várias transações rodam ao mesmo tempo sem interferir umas nas outras, viabilizando alta concorrência.
Bloqueio otimista
O modelo transacional do Aurora DSQL se apoia no bloqueio otimista:
- As transações partem do princípio de que há pouca contenção e só checam conflitos no momento do commit.
- Se um conflito for detectado (por exemplo, outra transação alterou os mesmos dados), a transação falha e a aplicação precisa tentar de novo.
O bloqueio otimista funciona melhor em workloads com baixa contenção de escrita, mas exige uma lógica de retry robusta em cenários de contenção mais alta.
O Adjudicator e o Journal
Componentes arquiteturais essenciais garantem a consistência e a durabilidade do Aurora DSQL:
- Adjudicator: impõe uma ordem de commit globalmente consistente para as transações, resolvendo conflitos e mantendo consistência forte.
- Journal: um log distribuído que registra as alterações de cada transação, oferecendo durabilidade e permitindo a recuperação em caso de falhas.
Quais padrões de dados funcionam melhor com o Aurora DSQL?
O Aurora DSQL se destaca com determinados padrões de dados, principalmente os que conversam com sua natureza distribuída e desagregada. Veja em mais detalhes os padrões que se dão bem nesse ambiente e como identificá-los nos seus workloads.
1. Workloads de alta concorrência
O Aurora DSQL é ideal para aplicações com muitos usuários ou processos concorrentes, como:
- Plataformas de e-commerce: lidando com transações simultâneas de atualização de estoque, compras e atividade do usuário.
- Aplicações de redes sociais: gerenciando curtidas, comentários e interações entre milhões de usuários ativos.
- Aplicações SaaS: atendendo a vários clientes com workloads isolados, mas compartilhando a mesma infraestrutura de banco de dados.
Para identificar se o seu workload se encaixa nesse padrão:
- Observe o número de usuários simultâneos no pico e a atividade de consultas.
- Veja se a contenção (por exemplo, vários processos escrevendo nos mesmos dados) é gerenciável com bloqueio otimista.
2. Aplicações com leitura intensa
Como as leituras no Aurora DSQL não geram bloqueios nem registros de undo, workloads com leitura intensa têm desempenho excepcional. Alguns exemplos:
- Dashboards e analytics: aplicações em que dados em tempo real são consultados com mais frequência do que atualizados.
- Plataformas de distribuição de conteúdo: aplicações de streaming ou de notícias em que os usuários, na maior parte do tempo, só consomem conteúdo.
Para avaliar a sua proporção entre leitura e escrita:
- Monitore os logs de consultas para verificar o percentual de leituras em relação às escritas.
- Use os performance insights do Aurora ou ferramentas de monitoramento do banco para medir latência e throughput das consultas de leitura.
3. Acesso a dados geograficamente distribuído
A natureza distribuída do Aurora DSQL o torna uma ótima opção para aplicações que atendem usuários no mundo todo:
- Plataformas de games: jogos multiplayer em que jogadores de diferentes regiões interagem em tempo real.
- Ferramentas de colaboração: aplicações de compartilhamento de documentos ou chat que exigem acesso de baixa latência entre continentes.
Para identificar esse padrão:
- Mapeie sua base de usuários geograficamente e veja se as consultas sensíveis à latência partem de várias regiões.
- Avalie se um banco centralizado está causando problemas de latência para usuários distantes.
4. Workloads de escrita com baixa contenção
O bloqueio otimista do Aurora DSQL brilha quando a contenção de escrita é baixa. Por exemplo:
- Dados particionados: aplicações em que as escritas estão naturalmente isoladas em partições específicas, como atualizações por usuário ou por tenant.
- Registro de eventos: sistemas em que os eventos são gravados de forma independente, com pouca sobreposição.
Para verificar se o seu workload se encaixa:
- Analise as operações de escrita e veja se elas atingem com frequência as mesmas linhas ou objetos.
- Procure oportunidades naturais de particionamento no seu schema (por exemplo, sharding por ID de usuário ou tenant).
5. Processamento híbrido transacional e analítico (HTAP)
Aplicações que combinam consultas transacionais e analíticas se beneficiam da capacidade do Aurora DSQL de lidar com os dois tipos de workloads com eficiência:
- Dashboards financeiros: unindo atualizações de transações em tempo real a resumos analíticos.
- Sistemas de estoque: permitindo atualizações operacionais e, ao mesmo tempo, oferecendo insights imediatos sobre os níveis de estoque.
Para confirmar esse padrão:
- Identifique workloads que envolvam tanto atualizações em tempo real quanto consultas analíticas.
- Garanta que as consultas analíticas de longa duração possam ser otimizadas para caber dentro do timeout de 5 minutos por consulta do Aurora DSQL.
O Aurora DSQL é a escolha certa para você?
O Aurora DSQL é um banco de dados poderoso para aplicações modernas que precisam escalar horizontalmente sem abrir mão da consistência. Ele se destaca em workloads de alta concorrência, com leitura intensa, particionáveis e geograficamente distribuídos. Em contrapartida, pode exigir um design cuidadoso de schema e da lógica da aplicação para lidar com limitações como o bloqueio otimista e os timeouts de consulta.
Analisando seus padrões de dados e cruzando-os com os pontos fortes do Aurora DSQL, dá para concluir se esse banco distribuído inovador é a escolha certa para você. Com o design adequado, o Aurora DSQL pode entregar escalabilidade, desempenho e resiliência incomparáveis para a sua aplicação.
Tem dúvidas sobre como tirar proveito do Aurora DSQL na sua organização?
Se você ainda está tentando entender como aplicar esses insights para tirar o máximo do Aurora DSQL — ou de qualquer outra solução de dados do GCP ou da AWS — na sua organização, a gente pode ajudar.
Na DoiT, nosso time é formado exclusivamente por talentos sêniores de engenharia. Somos especializados em consultoria avançada em nuvem, design de arquitetura e serviços de debugging. Quer você esteja planejando os primeiros passos com bancos de dados distribuídos, otimizando um sistema existente ou resolvendo problemas complexos, oferecemos orientação especializada e sob medida para o seu cenário.
Fale com a gente hoje mesmo e deixe nosso time ajudar você a explorar todo o potencial da sua infraestrutura de nuvem.