Découvrez le fonctionnement d'Amazon Aurora DSQL et son adéquation à vos besoins. Architecture distribuée, patterns de données idéaux et limites des bases traditionnelles repoussées : on fait le tour.

Amazon Aurora DSQL (Distributed SQL) propose une nouvelle approche des bases de données relationnelles : une architecture SQL distribuée pensée pour offrir une forte scalabilité, une disponibilité solide et une prise en charge fluide des transactions distribuées. Adopter Aurora DSQL ne se résume pas à un élan d'enthousiasme (et j'avoue être emballé ; on m'a déjà demandé de calmer le jeu dans ce billet) : il faut bien comprendre son fonctionnement et vérifier que vos patterns de données collent à ses capacités.
Dans cet article, nous allons décortiquer le fonctionnement d'Aurora DSQL, passer en revue les patterns de données qui s'y prêtent le mieux, et voir comment juger s'il convient à vos workloads.
Comment fonctionne Aurora DSQL ?
La puissance d'Aurora DSQL tient à une conception innovante qui désagrège les composants de la base en services indépendants et scalables. En tirant parti de la vitesse et de la bande passante massives des réseaux cloud modernes, et grâce à une architecture distribuée, Aurora DSQL trouve l'équilibre entre scalabilité, performance et cohérence. Commençons par un schéma d'architecture haut niveau présentant les 5 composants d'Aurora DSQL :
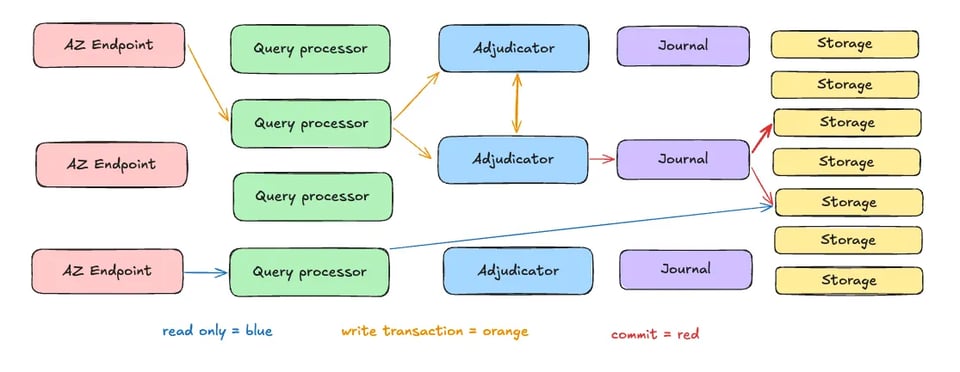
Une architecture désagrégée
Aurora DSQL sépare l'exécution des requêtes, la gestion des transactions et le stockage en services spécialisés :
- Couche d'exécution des requêtes : exécute les requêtes SQL en parallèle, avec une scalabilité horizontale qui suit la demande.
- Couche de gestion des transactions : coordonne les transactions distribuées via des techniques comme le verrouillage optimiste, garantissant la cohérence.
- Couche de stockage : un système distribué shared-nothing qui réplique les données sur plusieurs nœuds pour assurer la durabilité et la tolérance aux pannes.
Chaque service est conçu pour évoluer indépendamment, ce qui permet au système d'absorber des workloads d'intensité variable sans goulets d'étranglement.
Des microVM pour isoler les transactions
Aurora DSQL exécute chaque transaction dans sa propre microVM, pour une isolation totale. Cette architecture supprime la contention entre transactions, en particulier sur :
- Les workloads à dominante lecture : les lectures n'entraînent ni verrouillage ni génération de logs d'annulation, ce qui les rend légères et rapides.
- Les transactions concurrentes : plusieurs transactions s'exécutent simultanément sans interférence, pour une concurrence élevée.
Le verrouillage optimiste
Le modèle transactionnel d'Aurora DSQL repose sur le verrouillage optimiste :
- Les transactions partent du principe que la contention est minimale et ne vérifient les conflits qu'au moment du commit.
- Si un conflit est détecté (par exemple, une autre transaction a modifié les mêmes données), la transaction échoue et l'application doit la rejouer.
Le verrouillage optimiste donne le meilleur sur des workloads à faible contention en écriture, mais exige une logique de retry solide dans les scénarios à plus forte contention.
L'Adjudicator et le Journal
Deux composants architecturaux clés assurent la cohérence et la durabilité d'Aurora DSQL :
- Adjudicator : impose un ordre de commit globalement cohérent, arbitre les conflits et maintient une cohérence forte.
- Journal : un journal distribué qui enregistre les modifications transactionnelles, garantissant la durabilité et la reprise après incident.
Quels patterns de données conviennent le mieux à Aurora DSQL ?
Aurora DSQL excelle avec certains patterns de données, en particulier ceux qui épousent sa nature distribuée et désagrégée. Voici un tour d'horizon des patterns qui s'y épanouissent et de la façon de les repérer dans vos workloads.
1. Workloads à forte concurrence
Aurora DSQL est idéal pour les applications comptant de nombreux utilisateurs ou processus concurrents :
- Plateformes e-commerce : transactions simultanées pour les mises à jour de stock, les achats et l'activité utilisateur.
- Réseaux sociaux : gestion des likes, des commentaires et des interactions pour des millions d'utilisateurs actifs.
- Applications SaaS : prise en charge de plusieurs clients aux workloads isolés sur une même infrastructure de base de données.
Pour vérifier si votre workload colle à ce pattern :
- Examinez votre pic d'utilisateurs concurrents et l'activité des requêtes.
- Vérifiez si la contention (par exemple, plusieurs processus écrivant sur les mêmes données) reste gérable avec un verrouillage optimiste.
2. Applications à dominante lecture
Comme les lectures dans Aurora DSQL ne provoquent ni verrous ni génération d'annulation, les workloads à dominante lecture s'y comportent particulièrement bien. Quelques exemples :
- Dashboards et analytics : applications où les données en temps réel sont bien plus consultées qu'écrites.
- Plateformes de diffusion de contenu : applications de streaming ou d'actualité, où les utilisateurs consomment essentiellement du contenu.
Pour évaluer votre ratio lecture/écriture :
- Analysez les logs de requêtes pour mesurer la part des lectures par rapport aux écritures.
- Utilisez les performance insights d'Aurora ou vos outils de monitoring pour mesurer la latence et le débit des requêtes de lecture.
3. Accès aux données géographiquement distribué
La nature distribuée d'Aurora DSQL en fait un excellent choix pour les applications à audience mondiale :
- Plateformes de jeu : jeux multijoueurs où des joueurs de différentes régions interagissent en temps réel.
- Outils collaboratifs : partage de documents ou messageries instantanées exigeant un accès faible latence d'un continent à l'autre.
Pour identifier ce pattern :
- Cartographiez votre base d'utilisateurs et déterminez si des requêtes sensibles à la latence proviennent de plusieurs régions.
- Évaluez si une base de données centralisée pose des problèmes de latence pour les utilisateurs éloignés.
4. Workloads d'écriture à faible contention
Le verrouillage optimiste d'Aurora DSQL prend tout son sens lorsque la contention en écriture est faible. Quelques exemples :
- Données partitionnées : applications dont les écritures sont naturellement isolées sur des partitions spécifiques, par exemple par utilisateur ou par tenant.
- Journalisation d'événements : systèmes où les événements sont écrits indépendamment, avec un recouvrement minimal.
Pour vérifier l'adéquation de votre workload :
- Analysez les opérations d'écriture afin de voir si elles ciblent souvent les mêmes lignes ou objets.
- Repérez les opportunités naturelles de partitionnement dans votre schéma (par exemple, sharding par ID utilisateur ou par tenant).
5. Hybrid Transactional and Analytical Processing (HTAP)
Les applications mêlant requêtes transactionnelles et analytiques profitent de la capacité d'Aurora DSQL à gérer efficacement les deux :
- Dashboards financiers : combiner mises à jour transactionnelles en temps réel et synthèses analytiques.
- Systèmes de gestion des stocks : autoriser les mises à jour opérationnelles tout en offrant une visibilité immédiate sur les niveaux de stock.
Pour confirmer ce pattern :
- Identifiez les workloads qui combinent mises à jour en temps réel et requêtes analytiques.
- Assurez-vous que les requêtes analytiques de longue durée peuvent être optimisées pour tenir dans le timeout de requête de 5 minutes d'Aurora DSQL.
Aurora DSQL est-il fait pour vous ?
Aurora DSQL est un système de base de données puissant pour les applications modernes qui doivent évoluer horizontalement sans sacrifier la cohérence. Il excelle sur les workloads à forte concurrence, à dominante lecture, partitionnables et distribués mondialement. Il peut toutefois imposer une conception soignée du schéma et de la logique applicative pour composer avec certaines limites, comme le verrouillage optimiste et les timeouts de requêtes.
En analysant vos patterns de données à l'aune des atouts d'Aurora DSQL, vous pourrez déterminer si cette base de données distribuée innovante correspond à vos besoins. Avec la bonne conception, Aurora DSQL offre à votre application une scalabilité, des performances et une résilience hors pair.
Des questions pour déployer Aurora DSQL dans votre organisation ?
Si vous vous demandez encore comment exploiter ces enseignements pour tirer parti d'Aurora DSQL — ou de toute autre solution de données GCP ou AWS — au sein de votre organisation, nous sommes là pour vous accompagner.
Chez DoiT, notre équipe est exclusivement composée d'ingénieurs seniors. Nous sommes spécialisés dans le conseil cloud avancé, la conception d'architectures et le débogage. Que vous prépariez vos premiers pas avec les bases de données distribuées, que vous optimisiez un système existant ou que vous résolviez des problèmes complexes, nous vous apportons des conseils d'experts sur mesure.
Contactez-nous dès aujourd'hui pour libérer tout le potentiel de votre infrastructure cloud.