Erfahren Sie, wie Amazon Aurora DSQL funktioniert und ob es zu Ihren Anforderungen passt. Lernen Sie die verteilte Architektur kennen, ideale Datenmuster und wie DSQL klassische Datenbankgrenzen neu definiert.

Amazon Aurora DSQL (Distributed SQL) verfolgt einen neuen Ansatz für relationale Datenbanken: Eine verteilte SQL-Architektur sorgt für hohe Skalierbarkeit, robuste Verfügbarkeit und nahtlose Unterstützung verteilter Transaktionen. Aurora DSQL einzuführen, erfordert mehr als bloße Begeisterung (und ja, ich bin ein wenig begeistert – mir wurde bereits gesagt, ich solle in diesem Blog einen Gang zurückschalten). Es braucht ein klares Verständnis dafür, wie DSQL arbeitet und ob Ihre Datenmuster wirklich zu seinen Stärken passen.
In diesem Beitrag schauen wir uns an, wie Aurora DSQL funktioniert, beleuchten Datenmuster, die sich in dieser Umgebung besonders gut machen, und klären, woran Sie erkennen, ob es zu Ihren workloads passt.
Wie funktioniert Aurora DSQL?
Die Stärke von Aurora DSQL liegt im innovativen Design: Datenbankkomponenten werden in unabhängige, skalierbare Services entkoppelt. Dank der enormen Geschwindigkeit und Bandbreite moderner Cloud-Netzwerke und einer verteilten Architektur erreicht Aurora DSQL eine Balance aus Skalierbarkeit, Performance und Konsistenz. Beginnen wir mit einem Architekturüberblick, der die fünf zentralen Komponenten von Aurora DSQL zeigt:
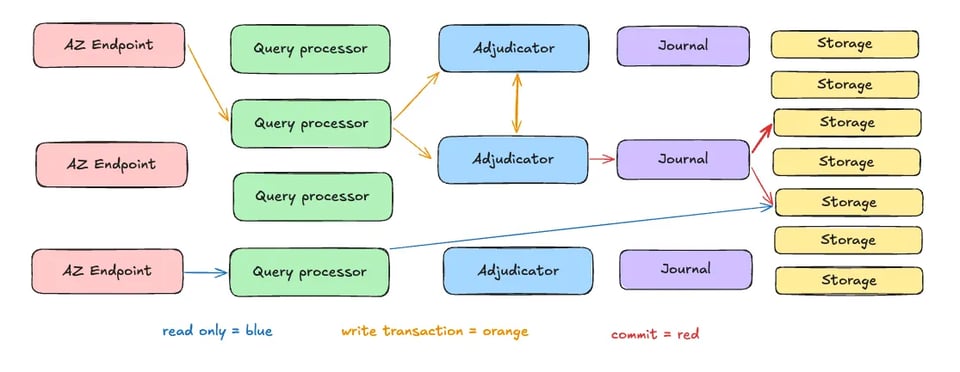
Entkoppelte Architektur
Aurora DSQL trennt Query-Ausführung, Transaktionsmanagement und Storage in spezialisierte Services:
- Query Execution Layer: Führt SQL-Abfragen parallel aus und skaliert horizontal mit steigender Last.
- Transaction Management Layer: Koordiniert verteilte Transaktionen mit Verfahren wie Optimistic Locking und sorgt so für Konsistenz.
- Storage Layer: Ein verteiltes Shared-Nothing-System repliziert Daten über mehrere Knoten – für Langlebigkeit und Ausfallsicherheit.
Jeder Service skaliert unabhängig, sodass das System workloads unterschiedlicher Intensität ohne Engpässe bewältigt.
MicroVMs zur Transaktionsisolation
Aurora DSQL führt jede Transaktion in einer eigenen microVM aus und sorgt so für vollständige Isolation. Diese Architektur eliminiert Konkurrenzsituationen zwischen Transaktionen – insbesondere bei:
- Read-heavy workloads: Lesezugriffe verursachen weder Locks noch Undo-Logs und sind dadurch leichtgewichtig und schnell.
- Parallelen Transaktionen: Mehrere Transaktionen laufen gleichzeitig, ohne sich gegenseitig zu stören – das ermöglicht hohe Nebenläufigkeit.
Optimistic Locking
Das Transaktionsmodell von Aurora DSQL setzt auf Optimistic Locking:
- Transaktionen gehen von minimaler Konkurrenz aus und prüfen erst beim Commit auf Konflikte.
- Wird ein Konflikt erkannt (z. B. weil eine andere Transaktion dieselben Daten geändert hat), schlägt die Transaktion fehl und die Anwendung muss einen Retry auslösen.
Optimistic Locking spielt seine Stärken bei workloads mit geringer Schreib-Konkurrenz aus – bei höherer Konkurrenz brauchen Sie eine robuste Retry-Logik.
Adjudicator und Journal
Zwei zentrale Architekturkomponenten gewährleisten Konsistenz und Langlebigkeit von Aurora DSQL:
- Adjudicator: Erzwingt eine global konsistente Commit-Reihenfolge für Transaktionen, löst Konflikte auf und sichert starke Konsistenz.
- Journal: Ein verteiltes Log, das Transaktionsänderungen protokolliert – für Persistenz und Recovery nach Ausfällen.
Welche Datenmuster passen am besten zu Aurora DSQL?
Aurora DSQL spielt seine Stärken bei bestimmten Datenmustern aus – vor allem bei solchen, die zu seiner verteilten und entkoppelten Natur passen. Hier ein genauerer Blick auf die Muster, die wirklich profitieren, und wie Sie sie in Ihrem Workload erkennen.
1. Workloads mit hoher Nebenläufigkeit
Aurora DSQL eignet sich ideal für Anwendungen mit vielen parallelen Nutzern oder Prozessen, etwa:
- E-Commerce-Plattformen: gleichzeitige Transaktionen für Bestandsaktualisierungen, Käufe und Nutzeraktivität.
- Social-Media-Anwendungen: Likes, Kommentare und Interaktionen über Millionen aktiver Nutzer hinweg.
- SaaS-Anwendungen: mehrere Kunden mit isolierten workloads auf gemeinsamer Datenbank-Infrastruktur.
So prüfen Sie, ob Ihr Workload zu diesem Muster passt:
- Werfen Sie einen Blick auf Ihre Spitzenwerte gleichzeitiger Nutzer und das Query-Aufkommen.
- Analysieren Sie, ob Konkurrenz (z. B. mehrere Prozesse, die in dieselben Daten schreiben) mit Optimistic Locking beherrschbar bleibt.
2. Leselastige Anwendungen
Da Lesezugriffe in Aurora DSQL weder Locks noch Undo-Logs erzeugen, performen read-heavy workloads außergewöhnlich gut. Beispiele:
- Dashboards und Analytics: Anwendungen, in denen Echtzeit-Daten häufiger gelesen als geschrieben werden.
- Content-Delivery-Plattformen: Streaming- oder Nachrichten-Apps, in denen Nutzer überwiegend Inhalte konsumieren.
So bewerten Sie Ihr Lese-Schreib-Verhältnis:
- Werten Sie Query-Logs aus, um den Anteil von Lese- gegenüber Schreiboperationen zu bestimmen.
- Nutzen Sie Auroras Performance Insights oder Datenbank-Monitoring-Tools, um Latenz und Durchsatz von Lese-Queries zu messen.
3. Geografisch verteilter Datenzugriff
Die verteilte Natur von Aurora DSQL passt hervorragend zu Anwendungen mit globaler Nutzerschaft:
- Gaming-Plattformen: Multiplayer-Spiele, in denen Spieler aus verschiedenen Regionen in Echtzeit interagieren.
- Collaboration-Tools: Dokumenten-Sharing oder Chat-Anwendungen, die kontinentübergreifend niedrige Latenzen verlangen.
So erkennen Sie dieses Muster:
- Verorten Sie Ihre Nutzerbasis geografisch und prüfen Sie, ob latenzempfindliche Queries aus mehreren Regionen kommen.
- Bewerten Sie, ob eine zentralisierte Datenbank für entfernte Nutzer Latenzprobleme verursacht.
4. Schreib-Workloads mit geringer Konkurrenz
Optimistic Locking in Aurora DSQL glänzt, wenn die Schreib-Konkurrenz gering ist. Beispiele:
- Partitionierte Daten: Anwendungen, in denen Schreibzugriffe von Natur aus auf bestimmte Partitionen beschränkt sind – etwa pro Nutzer oder Mandant.
- Event Logging: Systeme, in denen Ereignisse unabhängig voneinander mit minimaler Überschneidung geschrieben werden.
So prüfen Sie, ob Ihr Workload passt:
- Analysieren Sie Schreiboperationen darauf, ob sie häufig dieselben Zeilen oder Objekte betreffen.
- Suchen Sie in Ihrem Schema nach natürlichen Partitionierungsmöglichkeiten (z. B. Sharding nach Nutzer- oder Mandanten-ID).
5. Hybrid Transactional and Analytical Processing (HTAP)
Anwendungen, die transaktionale und analytische Queries verbinden, profitieren davon, dass Aurora DSQL beide workloads effizient bedient:
- Finanz-Dashboards: Echtzeit-Transaktionsupdates kombiniert mit analytischen Auswertungen.
- Bestandssysteme: operative Updates bei gleichzeitiger Echtzeit-Sicht auf Lagerbestände.
So bestätigen Sie dieses Muster:
- Identifizieren Sie workloads, die sowohl Echtzeit-Updates als auch analytische Queries umfassen.
- Stellen Sie sicher, dass langlaufende Analyse-Queries so optimiert werden können, dass sie innerhalb des 5-minütigen Query-Timeouts von Aurora DSQL bleiben.
Ist Aurora DSQL das Richtige für Sie?
Aurora DSQL ist ein leistungsstarkes Datenbanksystem für moderne Anwendungen, die horizontal skalieren müssen, ohne an Konsistenz zu verlieren. Es brilliert bei workloads mit hoher Nebenläufigkeit, leselastigen Profilen, partitionierbaren Daten und globaler Verteilung. Allerdings erfordern Einschränkungen wie Optimistic Locking und Query-Timeouts ein durchdachtes Schema-Design und eine entsprechende Anwendungslogik.
Wenn Sie Ihre Datenmuster analysieren und mit den Stärken von Aurora DSQL abgleichen, lässt sich klar entscheiden, ob diese innovative verteilte Datenbank zu Ihren Anforderungen passt. Mit dem richtigen Design liefert Aurora DSQL eine außergewöhnliche Skalierbarkeit, Performance und Resilienz für Ihre Anwendung.
Fragen dazu, wie Aurora DSQL in Ihrem Unternehmen funktioniert?
Sie überlegen noch, wie sich diese Erkenntnisse konkret nutzen lassen, um Aurora DSQL – oder eine andere Datenlösung in GCP oder AWS – in Ihrem Unternehmen erfolgreich einzusetzen? Wir unterstützen Sie gern.
Bei DoiT arbeiten ausschließlich erfahrene Senior Engineers. Wir sind spezialisiert auf anspruchsvolle Cloud-Beratung, Architektur-Design und Debugging-Services. Ob erste Schritte mit verteilten Datenbanken, die Optimierung bestehender Systeme oder das Lösen komplexer Probleme – wir liefern maßgeschneiderte Expertise, die zu Ihrer Situation passt.
Sprechen Sie uns an und holen Sie das volle Potenzial aus Ihrer Cloud-Infrastruktur heraus.