Il problema
Molte aziende vogliono cogliere i vantaggi di Vertex AI grazie alle sue funzionalità avanzate e all'integrazione nativa con l'ecosistema Google Cloud, senza limitarsi a creare un endpoint su una VM e fare il deploy del modello lì per le predizioni. I costi, però, rappresentano un ostacolo non trascurabile e impongono di trovare una soluzione più efficiente ed economica.
Il punto critico è che il costo del deploy dei modelli su Vertex AI dipende dal tempo, a prescindere dall'effettivo utilizzo delle risorse, come spiega la documentazione sui prezzi:
AI Platform Prediction eroga le predizioni del suo modello eseguendo un certo numero di macchine virtuali ("nodi").
Le viene addebitato il tempo in cui ciascun nodo è in esecuzione per il modello, ovvero:
1. Quando il nodo sta elaborando una richiesta di predizione online.
2. Quando il nodo è in stato pronto per servire predizioni online.
Il costo di un nodo in esecuzione per un'ora è pari a una node hour. Una node hour rappresenta il tempo in cui una macchina virtuale esegue il job di predizione o resta in stato attivo (un endpoint con uno o più modelli in deploy) in attesa di gestire richieste di predizione o di spiegazione.
Se le predizioni online vengono eseguite solo in determinate fasce orarie del giorno o della settimana, l'impossibilità di scalare a zero nei periodi di inattività diventa un problema rilevante. La situazione peggiora ulteriormente con i modelli basati su GPU, dove i costi crescono molto rapidamente.
Il caso del cliente
Nel nostro scenario, un cliente vuole utilizzare Vertex AI per le predizioni online del modello fondazionale Stable Diffusion (che richiede GPU) durante il normale orario lavorativo: cinque giorni a settimana, dalle 7:00 alle 19:00.
Anziché pagare 720 node hours, vorrebbe pagare solo l'utilizzo effettivo, ovvero 240 node hours (il 30%).
La soluzione proposta
Per risolvere il problema ricorriamo ai Cloud Run jobs:
I Cloud Run jobs permettono agli sviluppatori di eseguire script lunghi, run-to-completion, su una piattaforma serverless!
Se il suo codice esegue un'attività e poi si arresta (uno script ne è un esempio tipico), può affidarsi a un Cloud Run job per lanciarlo. Può eseguire un job da riga di comando con la gcloud CLI oppure pianificare un job ricorrente.
Il nostro approccio pragmatico si articola in tre passaggi principali:
- Eseguire il deploy del modello su un endpoint di predizione online di Vertex AI
- Generare Cloud Run jobs per il deploy e l'undeploy del modello sugli endpoint di Vertex AI Prediction
- Pianificare l'esecuzione dei job
Deploy del modello su un endpoint di predizione
Ho usato Vertex AI Model Garden per cercare e selezionare un modello pre-addestrato adatto alle esigenze del cliente. Il modello stable-diffusion-2–1 sembra rispondere ai requisiti. Scegliendo l'opzione 'Deploy' dalla console, l'artefatto del modello viene caricato nel Vertex AI Model Registry e poi sottoposto a deploy su un endpoint di predizione online.
Successivamente ho testato il modello con esito positivo e ne ho fatto manualmente l'undeploy.

Dettagli della versione del modello in Model Garden
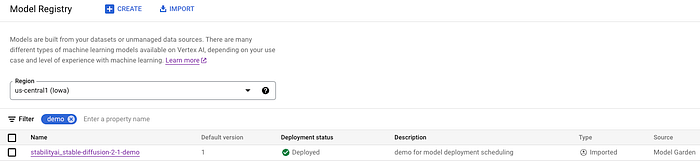
Il modello è stato importato nel Model Registry
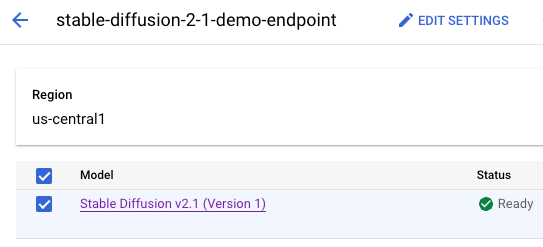
Il container del modello è in deploy sull'endpoint di predizione online
Coordinare deploy e undeploy del modello con Cloud Run
Per gestire con precisione il deploy e l'undeploy del nostro modello di machine learning sugli endpoint Vertex AI ci affidiamo a un Cloud Run Job.
Il Job si occupa del deploy o dell'undeploy ed esegue uno shell script che contiene i comandi gcloud necessari per gestire il modello sull'endpoint di predizione.
Creare i Cloud Run Jobs
Per creare i Cloud Run jobs procediamo così:
- Specifichiamo i parametri del modello, allineandoli ai valori configurati durante il primo deploy del modello sull'endpoint:
MODEL_NAME,MACHINE_TYPE,ACCELERATOR_TYPE,ENDPOINT_NAME
Sostituisca questi parametri in base al proprio caso d'uso.
2. Creiamo i Cloud Run Jobs per il deploy e l'undeploy del modello sugli endpoint di Vertex AI. La creazione del job avviene tramite gcloud run jobs con l'opzione di deploy from source (-source): viene costruito il container, caricato su Artifact Registry e infine viene eseguito il deploy dei job su Cloud Run.
3. Creiamo un trigger di scheduling per eseguire i job secondo la configurazione, sfruttando gcloud per la pianificazione del job. Questa funzionalità consente di definire pianificazioni precise, allineando l'attività delle risorse agli intervalli di tempo dedicati alle predizioni online nell'arco della giornata o della settimana.
Il repository GitHub vertex-ai-mng-deploy consente di generare sia il job DEPLOY sia il job UNDEPLOY per il modello sull'endpoint Vertex AI. Contiene:
1. CreateCloudRunJobs.sh, per la creazione dei Cloud Run job
2. MngModelDeploy.sh, per il deploy/undeploy del modello sull'endpoint Vertex AI
3. Un Dockerfile per costruire un container che include lo script MngModelDeploy.sh.
Ecco CreateCloudRunJobs.sh:
#!/bin/bash -xv
#A number that will be used for the id of the model deployment
ENDPOINT_NAME="stabilityai_stable-diffusion-endpoint"
MODEL_NAME="stable-diffusion-2-1"
MACHINE_TYPE="g2-standard-8"
ACCELERATOR_TYPE="nvidia-l4"
PROJECT=$(gcloud config get-value project)
PROJECT_NUMBER=$(gcloud projects describe "$PROJECT" --format="value(projectNumber)")
REGION=us-central1
DEPLOY_JOB_NAME=deploy-model-$MODEL_NAME
UNDEPLOY_JOB_NAME=undeploy-model-$MODEL_NAME
TIME_ZONE='UTC'
DEPLOY_SCHEDULE="0 7 * * *"
UN_DEPLOY_SCHEDULE="0 19 * * *"
#create a job for model deploy
gcloud run jobs deploy $DEPLOY_JOB_NAME --region=$REGION --source vertex-ai-mng-deploy \
--task-timeout=1800 --command "./MngModelDeploy.sh" \
--args DEPLOY,$ENDPOINT_NAME,$MODEL_NAME,$MACHINE_TYPE,$ACCELERATOR_TYPE \
--set-env-vars RUN_DEBUG=true,REGION=$REGION
#describe the job created
gcloud run jobs --region=$REGION describe $DEPLOY_JOB_NAME
#create a job for model undeploy
gcloud run jobs deploy $UNDEPLOY_JOB_NAME --region=$REGION --source vertex-ai-mng-deploy \
--task-timeout=180 --command "./MngModelDeploy.sh" \
--args UNDEPLOY,$ENDPOINT_NAME,$MODEL_NAME --set-env-vars RUN_DEBUG=true,REGION=$REGION
#describe the job created
gcloud run jobs --region=$REGION describe $UNDEPLOY_JOB_NAME
Pianificazione dei Job:
Il trigger di scheduling dei Cloud Run Jobs è il fulcro della pianificazione dei processi di deploy e undeploy sull'endpoint Vertex AI. Permette di definire pianificazioni precise, allineando l'attività delle risorse alle finestre dedicate alle predizioni online nel corso della giornata o della settimana.
L'ultima parte dello script CreateCloudRunJobs.sh gestisce la creazione dei job di scheduling (tramite Cloud Scheduler):
#create a schedule for deploy
gcloud scheduler jobs create http scheduler-$DEPLOY_JOB_NAME \
--location $REGION \
--schedule="$DEPLOY_SCHEDULE" --time-zone=$TIME_ZONE \
--uri="https://$REGION-run.googleapis.com/apis/run.googleapis.com/v1/namespaces/$PROJECT/jobs/$DEPLOY_JOB_NAME:run" \
--http-method POST \
--oauth-service-account-email "$PROJECT_NUMBER"[email protected]
#create a schedule for undeploy
gcloud scheduler jobs create http scheduler-$DEPLOY_JOB_NAME \
--location $REGION \
--schedule="$UN_DEPLOY_SCHEDULE" --time-zone=$TIME_ZONE \
--uri="https://$REGION-run.googleapis.com/apis/run.googleapis.com/v1/namespaces/$PROJECT/jobs/$DEPLOY_JOB_NAME:run" \
--http-method POST \
--oauth-service-account-email "$PROJECT_NUMBER"[email protected]
Deploy e undeploy del modello
Lo script MngModelDeploy.sh viene eseguito dal Job e, in base all'argomento di input ACTION, ne determina il comportamento, stabilendo se eseguire il deploy o l'undeploy del modello:
Job di deploy del modello e relativo comando:
nadav@cloudshell:~$ gcloud run jobs describe deploy-model-stable-diffusion-2-1 --region=us-central1
✔ Job deploy-model-stable-diffusion-2-1 in region us-central1
Executed 6 times
Last executed 2024-01-30T08:06:22.875396Z with execution deploy-model-stable-diffusion-2-1-sr7kk
Image: us-central1-docker.pkg.dev/nadav/cloud-run-source-deploy/deploy-model-stable-diffusion-2-1@sha256:328c1117422af347be0906b0e4d27211ca764559e2405e8832d30d2f55158974
Tasks: 1
Command: ./MngModelDeploy.sh
Args: DEPLOY stabilityai_stable-diffusion-endpoint stable-diffusion-2-1 g2-standard-8 nvidia-l4
Memory: 512Mi
CPU: 1000m
Task Timeout: 30m
Max Retries: 3
Parallelism: No limit
Service account: [email protected]
Env vars:
REGION us-central1
RUN_DEBUG true
if [ "$ACTION" == "DEPLOY" ]; then
# Model deploy (takes time)
MODEL_ID=$(gcloud ai models list --region=$REGION \
--filter="DISPLAY_NAME:$MODEL_NAME" --format="value(MODEL_ID)")
echo "Deploying model..."
gcloud ai endpoints deploy-model "$ENDPOINT_ID" --region=$REGION \
--model="$MODEL_ID" --display-name="$MODEL_NAME"\
--machine-type="$MACHINE_TYPE" --accelerator=count=1,type="$ACCELERATOR_TYPE"
fi
Job di undeploy del modello e relativo comando:
nadav@cloudshell$ gcloud run jobs describe undeploy-model-stable-diffusion-2-1 --region=us-central1
✔ Job undeploy-model-stable-diffusion-2-1 in region us-central1
Executed 6 times
Last executed 2024-01-30T08:04:57.205233Z with execution undeploy-model-stable-diffusion-2-1-kgrrc
Image: us-central1-docker.pkg.dev/nadav/cloud-run-source-deploy/undeploy-model-stable-diffusion-2-1@sha256:b1a8de6919205191feab7e4bed5d98fba9b40ecc9cb6cdae5a5fda550a54f612
Tasks: 1
Command: ./MngModelDeploy.sh
Args: UNDEPLOY stabilityai_stable-diffusion-endpoint stable-diffusion-2-1
Memory: 512Mi
CPU: 1000m
Task Timeout: 3m
Max Retries: 3
Parallelism: No limit
Service account: [email protected]
Env vars:
REGION us-central1
RUN_DEBUG true
if [ "$ACTION" == "UNDEPLOY" ]; then
echo "Un-deploying model..."
DEPLOY_MODEL_ID=$(gcloud ai endpoints describe "$ENDPOINT_ID" --region=$REGION \
--format=json | \
jq --arg ml_name "$MODEL_NAME" \
-r '.deployedModels[] | select(.displayName == $ml_name).id')
gcloud ai endpoints undeploy-model "$ENDPOINT_ID" --region=$REGION \
--deployed-model-id="$DEPLOY_MODEL_ID"
fi
Conclusioni
La soluzione proposta — Vertex AI affiancato a Cloud Run per deploy e scheduling — offre un modo concreto ed efficace per evitare il consumo inutile di risorse nei periodi di inattività, con risparmi significativi sui costi.
Affrontando in modo mirato le strutture di costo basate sul tempo, le aziende possono sfruttare appieno il potenziale di Vertex AI senza rinunciare all'efficienza finanziaria.