O problema
Muitas empresas querem aproveitar os benefícios do Vertex AI pelos seus recursos robustos e pela integração com o ecossistema do Google Cloud, em vez de simplesmente subir um endpoint em uma VM e fazer o deploy do modelo ali para gerar predições. Só que o impacto no custo é um obstáculo considerável e exige uma solução mais eficiente e econômica.
O cerne da questão é que o custo de fazer deploy de modelos no Vertex AI depende do tempo, independentemente do uso real dos recursos, conforme descrito na documentação de preços:
O AI Platform Prediction entrega predições do seu modelo executando uma série de máquinas virtuais ("nós").
Você é cobrado pelo tempo em que cada nó fica em execução para o seu modelo, incluindo:
1. Quando o nó está processando uma solicitação de predição online.
2. Quando o nó está em estado pronto para servir predições online.
O custo de um nó em execução por uma hora é uma node hour. Uma node hour representa o tempo em que uma máquina virtual fica executando seu job de predição ou aguardando em estado ativo (um endpoint com um ou mais modelos com deploy) para atender solicitações de predição ou explicação.
Quando as predições online são agendadas apenas em determinados intervalos do dia ou da semana, não conseguir escalar para zero nos períodos ociosos vira um problema sério. E o desafio fica ainda maior com modelos baseados em GPU, já que os custos podem disparar rapidamente.
O dilema do cliente
No nosso cenário, o cliente quer usar o Vertex AI para predições online do modelo de base Stable Diffusion (que exige GPU) durante o horário comercial em dias úteis — mais especificamente, cinco dias por semana, das 7h às 19h.
Em vez de 720 node hours, ele gostaria de pagar apenas pela utilização real, que é de 240 node hours (30%).
Solução proposta
Para resolver isso, vamos usar o Cloud Run jobs:
O Cloud Run jobs permite que desenvolvedores executem scripts longos, que rodam até a conclusão — tudo em uma plataforma serverless!
Se o seu código faz um trabalho e depois para (um script é um bom exemplo), você pode usar um Cloud Run job para executá-lo. Dá para rodar um job pela linha de comando com o gcloud CLI ou agendar um job recorrente.
Nossa abordagem prática tem três passos principais:
- Fazer o deploy do modelo em um endpoint de predição online do Vertex AI
- Gerar CloudRun jobs tanto para o deploy quanto para o undeploy do modelo nos Vertex AI Prediction Endpoints
- Criar o agendamento dos jobs
Deploy do modelo em um endpoint de predição
Usei o Vertex AI Model Garden para explorar e selecionar um modelo pré-treinado adequado às necessidades do cliente. O modelo stable-diffusion-2–1 parece atender aos requisitos. Ao escolher a opção 'Deploy' no console, o artefato do modelo é enviado para o Vertex AI Model Registry e, em seguida, recebe deploy em um endpoint de predição online.
Depois disso, testei o modelo com sucesso e fiz o undeploy manualmente.

Detalhes da versão do modelo no Model Garden
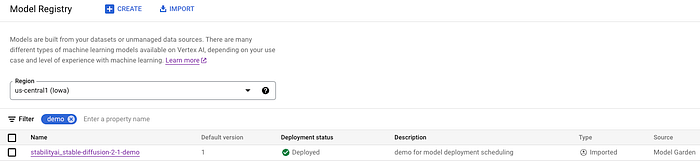
O modelo foi importado para o Model Registry
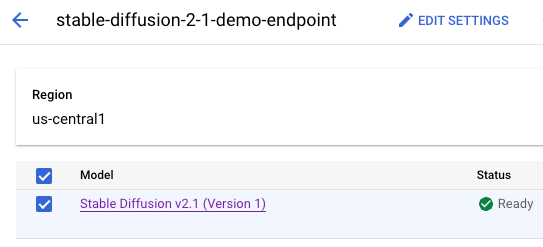
O contêiner do modelo recebe deploy no endpoint de predição online
Usando o Cloud Run para coordenar deploy e undeploy do modelo
Para controlar com precisão o deploy e o undeploy do nosso modelo de machine learning nos endpoints do Vertex AI, contamos com o CloudRun Job.
O Job tem a função de fazer deploy ou undeploy. Ele se apoia em um shell script com os comandos gcloud necessários para o deploy e o undeploy do modelo no endpoint de predição.
Criando os CloudRun Jobs
Para criar os CloudRun jobs, seguimos estes passos:
- Definir os parâmetros do modelo de modo que correspondam aos valores configurados no deploy inicial no endpoint:
MODEL_NAME,MACHINE_TYPE,ACCELERATOR_TYPE,ENDPOINT_NAME
Esses parâmetros devem ser ajustados conforme o seu uso.
2. Criar os CloudRun Jobs para deploy e undeploy do modelo nos endpoints do Vertex AI. A criação do job é feita com o gcloud run jobs, usando a opção de deploy a partir do código-fonte (-source), que constrói o contêiner, faz upload para o Artifact Registry e implanta os jobs no Cloud Run.
3. Criar um trigger no scheduler para executar os jobs conforme a configuração, usando o gcloud para agendamento de jobs. Esse recurso permite definir agendamentos precisos, garantindo que a atividade dos recursos esteja alinhada com os intervalos específicos das predições online ao longo do dia e da semana.
O repositório vertex-ai-mng-deploy no GitHub pode ser usado para gerar os jobs de DEPLOY e UNDEPLOY do modelo no endpoint do Vertex AI. O repositório contém:
1. CreateCloudRunJobs.sh para criação dos Cloud Run jobs
2. MngModelDeploy.sh para deploy/undeploy do modelo no endpoint do Vertex AI
3. Um Dockerfile para criar um contêiner que inclui o script MngModelDeploy.sh.
Este é o CreateCloudRunJobs.sh:
#!/bin/bash -xv
#A number that will be used for the id of the model deployment
ENDPOINT_NAME="stabilityai_stable-diffusion-endpoint"
MODEL_NAME="stable-diffusion-2-1"
MACHINE_TYPE="g2-standard-8"
ACCELERATOR_TYPE="nvidia-l4"
PROJECT=$(gcloud config get-value project)
PROJECT_NUMBER=$(gcloud projects describe "$PROJECT" --format="value(projectNumber)")
REGION=us-central1
DEPLOY_JOB_NAME=deploy-model-$MODEL_NAME
UNDEPLOY_JOB_NAME=undeploy-model-$MODEL_NAME
TIME_ZONE='UTC'
DEPLOY_SCHEDULE="0 7 * * *"
UN_DEPLOY_SCHEDULE="0 19 * * *"
#create a job for model deploy
gcloud run jobs deploy $DEPLOY_JOB_NAME --region=$REGION --source vertex-ai-mng-deploy \
--task-timeout=1800 --command "./MngModelDeploy.sh" \
--args DEPLOY,$ENDPOINT_NAME,$MODEL_NAME,$MACHINE_TYPE,$ACCELERATOR_TYPE \
--set-env-vars RUN_DEBUG=true,REGION=$REGION
#describe the job created
gcloud run jobs --region=$REGION describe $DEPLOY_JOB_NAME
#create a job for model undeploy
gcloud run jobs deploy $UNDEPLOY_JOB_NAME --region=$REGION --source vertex-ai-mng-deploy \
--task-timeout=180 --command "./MngModelDeploy.sh" \
--args UNDEPLOY,$ENDPOINT_NAME,$MODEL_NAME --set-env-vars RUN_DEBUG=true,REGION=$REGION
#describe the job created
gcloud run jobs --region=$REGION describe $UNDEPLOY_JOB_NAME
Agendamento dos Jobs:
O trigger do scheduler do CloudRun Jobs é fundamental para agendar esses processos de deploy e undeploy no endpoint do Vertex AI. Ele permite definir agendamentos precisos, garantindo que a atividade dos recursos esteja alinhada com os intervalos específicos das predições online ao longo do dia ou da semana.
A última parte do script CreateCloudRunJobs.sh contém a criação dos jobs de agendamento (usando o Cloud Scheduler):
#create a schedule for deploy
gcloud scheduler jobs create http scheduler-$DEPLOY_JOB_NAME \
--location $REGION \
--schedule="$DEPLOY_SCHEDULE" --time-zone=$TIME_ZONE \
--uri="https://$REGION-run.googleapis.com/apis/run.googleapis.com/v1/namespaces/$PROJECT/jobs/$DEPLOY_JOB_NAME:run" \
--http-method POST \
--oauth-service-account-email "$PROJECT_NUMBER"[email protected]
#create a schedule for undeploy
gcloud scheduler jobs create http scheduler-$DEPLOY_JOB_NAME \
--location $REGION \
--schedule="$UN_DEPLOY_SCHEDULE" --time-zone=$TIME_ZONE \
--uri="https://$REGION-run.googleapis.com/apis/run.googleapis.com/v1/namespaces/$PROJECT/jobs/$DEPLOY_JOB_NAME:run" \
--http-method POST \
--oauth-service-account-email "$PROJECT_NUMBER"[email protected]
Deploy e undeploy do modelo
O script MngModelDeploy.sh é executado pelo Job e, dependendo do argumento de entrada ACTION, define o que o Job vai fazer: deploy ou undeploy do modelo.
Job e comando de deploy do modelo:
nadav@cloudshell:~$ gcloud run jobs describe deploy-model-stable-diffusion-2-1 --region=us-central1
✔ Job deploy-model-stable-diffusion-2-1 in region us-central1
Executed 6 times
Last executed 2024-01-30T08:06:22.875396Z with execution deploy-model-stable-diffusion-2-1-sr7kk
Image: us-central1-docker.pkg.dev/nadav/cloud-run-source-deploy/deploy-model-stable-diffusion-2-1@sha256:328c1117422af347be0906b0e4d27211ca764559e2405e8832d30d2f55158974
Tasks: 1
Command: ./MngModelDeploy.sh
Args: DEPLOY stabilityai_stable-diffusion-endpoint stable-diffusion-2-1 g2-standard-8 nvidia-l4
Memory: 512Mi
CPU: 1000m
Task Timeout: 30m
Max Retries: 3
Parallelism: No limit
Service account: [email protected]
Env vars:
REGION us-central1
RUN_DEBUG true
if [ "$ACTION" == "DEPLOY" ]; then
# Model deploy (takes time)
MODEL_ID=$(gcloud ai models list --region=$REGION \
--filter="DISPLAY_NAME:$MODEL_NAME" --format="value(MODEL_ID)")
echo "Deploying model..."
gcloud ai endpoints deploy-model "$ENDPOINT_ID" --region=$REGION \
--model="$MODEL_ID" --display-name="$MODEL_NAME"\
--machine-type="$MACHINE_TYPE" --accelerator=count=1,type="$ACCELERATOR_TYPE"
fi
Job e comando de undeploy do modelo:
nadav@cloudshell$ gcloud run jobs describe undeploy-model-stable-diffusion-2-1 --region=us-central1
✔ Job undeploy-model-stable-diffusion-2-1 in region us-central1
Executed 6 times
Last executed 2024-01-30T08:04:57.205233Z with execution undeploy-model-stable-diffusion-2-1-kgrrc
Image: us-central1-docker.pkg.dev/nadav/cloud-run-source-deploy/undeploy-model-stable-diffusion-2-1@sha256:b1a8de6919205191feab7e4bed5d98fba9b40ecc9cb6cdae5a5fda550a54f612
Tasks: 1
Command: ./MngModelDeploy.sh
Args: UNDEPLOY stabilityai_stable-diffusion-endpoint stable-diffusion-2-1
Memory: 512Mi
CPU: 1000m
Task Timeout: 3m
Max Retries: 3
Parallelism: No limit
Service account: [email protected]
Env vars:
REGION us-central1
RUN_DEBUG true
if [ "$ACTION" == "UNDEPLOY" ]; then
echo "Un-deploying model..."
DEPLOY_MODEL_ID=$(gcloud ai endpoints describe "$ENDPOINT_ID" --region=$REGION \
--format=json | \
jq --arg ml_name "$MODEL_NAME" \
-r '.deployedModels[] | select(.displayName == $ml_name).id')
gcloud ai endpoints undeploy-model "$ENDPOINT_ID" --region=$REGION \
--deployed-model-id="$DEPLOY_MODEL_ID"
fi
Conclusão
Em resumo, usar o Vertex AI em conjunto com o CloudRun para deploy e agendamento é uma forma prática e eficaz de evitar consumo desnecessário de recursos em períodos ociosos, gerando uma economia expressiva.
Ao atacar os desafios específicos das estruturas de custo baseadas em tempo, as empresas conseguem extrair todo o potencial do Vertex AI sem abrir mão da eficiência financeira.