LLM così roventi da bucarle il portafoglio
Ricorda i primi tempi del cloud? Il nostro grattacapo FinOps numero uno era la VM senza tag. Uno sviluppatore lanciava un server enorme, si dimenticava di etichettarlo e BAM! A fine mese ci ritrovavamo con una spesa non allocata fastidiosamente misteriosa. Era doloroso, certo, ma di solito il costo cresceva nell'arco di settimane.
Bene, si allacci la cintura. Il FinOps per l'AI è arrivato e sta per darle un bel colpo di frusta. Il nuovo buco nero dei costi non è un server in incognito, sono i token fuori controllo.
Quando un prompt non ottimizzato colpisce un LLM costoso 100 volte al secondo, il suo budget non si limita a perdere colpi… esplode. Stiamo parlando di picchi di costo che mandano in fumo il budget in poche ore, non in mesi.
La soluzione? Spostare il focus dal tagging dell'infrastruttura alla telemetria a livello applicativo. Dobbiamo tracciare il costo di ogni singolo token, in tempo reale.
Il discorso vale a maggior ragione per gli agenti AI — non i chatbot, in cui ogni sessione si lega facilmente a un utente specifico, ma gli agenti autonomi che potenzialmente lavorano per tutto il team.
FinOps per l'AI: la telemetria del cloud non basta
Il vecchio metodo per tracciare i costi — basato sulle fatture del cloud provider (Cost Explorer, Cost Management, ecc.) — è troppo lento e troppo grossolano per l'utilizzo delle API AI.
La tabella seguente mette a confronto il FinOps 1.0 con il FinOps per l'AI emergente:
| Caratteristica | FinOps Cloud iniziale | FinOps AI attuale (API)
|------------------|--------------------------------|----------------------------------------
| Unità di costo | Ora VM, GB di storage | Token di input, token di output
-------------------|--------------------------------|-----------------------------------------
| Driver di costo | Risorse inattive, | Efficienza del prompt,
| | egress di rete | scelta del modello
-------------------|--------------------------------|-----------------------------------------
| Visibilità costi | Log di fatturazione gior./orari| Telemetria per transazione in tempo reale
-------------------|--------------------------------|-----------------------------------------
| Strumento ottim. | Spegnimento dei server | - Riscrittura del prompt/codice
| | | - Selezione del modello in tempo reale
-------------------|--------------------------------|-----------------------------------------
Per gestire davvero i costi delle applicazioni AI non possiamo aspettare la fattura. Ci serve un'intelligenza FinOps integrata direttamente nello strato applicativo, in grado di rendicontare ogni singolo token inviato o ricevuto. Ed è qui che OpenTelemetry (OTel) ci viene in soccorso.
Tutorial: come strumentare il suo agente AI con OpenTelemetry
OpenTelemetry è un framework open-source che fornisce uno standard unico per la raccolta dei dati di osservabilità (tracce, metriche e log). Possiamo sfruttarne le funzionalità di tracing per incapsulare le chiamate agli LLM e iniettare il contesto FinOps di cui abbiamo bisogno.
L'esempio seguente mostra come implementare il tracciamento dell'allocazione dei costi FinOps per gli agenti AI utilizzando OpenTelemetry e l'Agent Development Kit (ADK) di Google.
Questo codice è la sua chiave d'accesso alla libertà FinOps. Garantisce che ogni token utilizzato dal suo agente AI venga immediatamente associato al giusto titolare di budget. Basta tirare a indovinare!
Il codice eseguibile è disponibile qui: https://github.com/antweiss/finops-ai-otel.
AVVISO IMPORTANTE: non adatto alla produzione!
In questo tutorial usiamo ConsoleSpanExporter per stampare i dati di traccia grezzi sul terminale. In un ambiente di produzione non lo farebbe MAI!
In produzione sostituirebbe l'exporter su console con un OTLP Exporter dedicato, che invia i dati a un servizio backend solido come:
- Google Cloud Trace: l'opzione nativa per gli utenti di Google Cloud.
- Un backend di osservabilità gestito: ad esempio Jaeger, Datadog o New Relic.
- Una piattaforma dedicata di gestione FinOps come DoiT Cloud Intelligence
Questi backend le permettono di interrogare e aggregare i dati ed eseguire report FinOps come: "Mostrami il numero totale di token utilizzati con finops.project_code uguale a 'BLOG-FINOPS-001' negli ultimi 30 giorni." Ecco come si trasforma una traccia in un report di costo!
Step 1 e 2: prepararsi all'esecuzione
La procedura la conosce già! Cloni il repo, installi le dipendenze e imposti la sua API key.
git clone https://github.com/antweiss/finops-ai-otel.git
cd finops-ai-otel
pip install -r requirements.txt
export GEMINI_API_KEY="YOUR_API_KEY_HERE"
Step 3: esegua il codice e veda scorrere i token!
Quando esegue il file agent.py, il superpotere FinOps si attiva all'interno della funzione run_finops_session.
python agent.py
Come entrano in gioco i tag FinOps (analisi del codice)
L'obiettivo è incapsulare l'intera attività dell'agente in uno Span OpenTelemetry personalizzato che porti con sé i dettagli del nostro budget.
Avvio dello Span FinOps:
with tracer.start_as_current_span("adk-agent-session") as span:
Tutto il trucco è in questa riga! Avviamo uno span e lo dichiariamo span attivo corrente. Qualsiasi codice successivo strumentato con OTel (come le chiamate LLM interne dell'ADK di Google) creerà automaticamente i propri span come figli di questo span padre attivo.
Aggiunta dei metadati FinOps (tag):
span.set_attribute("finops.team_id", team_id)
span.set_attribute("finops.project_code", project_code)
È qui che iniettiamo i dettagli del centro di costo! Poiché gli span interni dell'ADK (che contengono i conteggi dei token) sono figli di questo span, il suo backend di tracing registrerà tutto l'utilizzo dei token direttamente sotto finops.project_code. Allocazione risolta!
Le metriche FinOps fondamentali
def setup_opentelemetry_tracer():
"""Configures the Tracer to output to the console for a runnable demo."""
# 1. Create a TracerProvider
provider = TracerProvider()
# 2. Add a simple processor that exports traces to the console
# This shows the raw trace data and attributes!
provider.add_span_processor(SimpleSpanProcessor(ConsoleSpanExporter()))
# 3. Set it as the global provider
trace.set_tracer_provider(provider)
return trace.get_tracer("finops.adk.agent")
L'output di ConsoleSpanExporter è il suo report di costo immediato. Cerchi lo span annidato della chiamata LLM per ottenere il quadro completo e fatturabile (gli attributi finops.* sono impostati dal codice di esempio, mentre gli attributi e le metriche llm.* arrivano dall'LLMAgent dell'ADK):
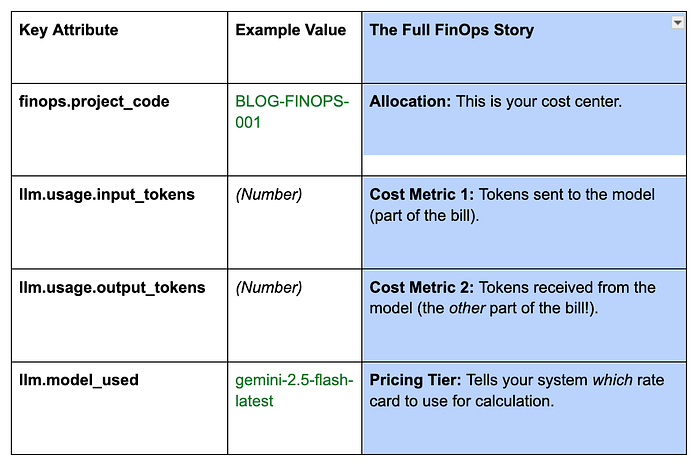
FinOps avanzato: propagazione degli span nei flussi multi-agente
E nei workflow complessi, in cui un agente delega il lavoro a un altro? È qui che la potenza di OpenTelemetry dà il meglio di sé.
- Nel modello OTel, quando un agente (il padre) chiama un altro agente o tool (il figlio), il contesto di traccia dello span padre viene propagato automaticamente lungo la catena di chiamate.
- L'intera sequenza di agenti e tool viene eseguita all'interno del contesto dello Span FinOps iniziale.
- Significa che un unico tag FinOps di alto livello copre tutta la complessa coreografia multi-step degli agenti: ottiene un report di costo unificato e verificabile per l'intero workflow! Questa funzionalità è ereditata dalla strumentazione OTel standard utilizzata dall'ADK.
Link
Per approfondire le fondamenta che rendono possibile questa soluzione FinOps:
Conferma il supporto nativo e integrato dell'ADK per la strumentazione OpenTelemetry.
Getting Started with OpenTelemetry
Illustra i principi alla base di Span, Context e Context Propagation.
Descrive in dettaglio i tipi di agenti (LlmAgent, SequentialAgent) che traggono vantaggio da questo tracing.
Nel prossimo articolo vedremo come introdurre guardrail di costo efficaci per le sue applicazioni AI.