LLMs tão quentes que abrem um buraco no seu bolso
Lembra dos primeiros dias da nuvem? Nossa maior dor de cabeça em FinOps era a VM sem tag. Um dev subia um servidor enorme, esquecia de etiquetar e PUM! No fim do mês, lá estava aquele gasto não alocado, misterioso e irritante. Doía, claro, mas o custo costumava se acumular ao longo de semanas.
Pois é, segura essa. FinOps para IA chegou e vai te dar um tranco. O novo buraco negro de custos não é um servidor escondido — são os tokens fora de controle.
Quando um prompt mal otimizado bate em um LLM caro 100 vezes por segundo, seu orçamento não vaza… ele explode. Estamos falando de picos de custo capazes de estourar o orçamento em horas, não em meses.
A solução? Precisamos tirar o foco da marcação de infraestrutura e colocar na telemetria em nível de aplicação. Precisamos rastrear o custo de cada token, em tempo real.
Isso é especialmente importante quando falamos em agentes de IA — não os chatbots, em que cada sessão se associa facilmente a um usuário específico, mas um agente autônomo que potencialmente trabalha para o time inteiro.
FinOps para IA: telemetria de nuvem não basta
O jeito antigo de acompanhar custos — usando faturas dos provedores de nuvem (Cost Explorer, Cost Management etc.) — é lento demais e pouco granular para o uso de APIs de IA.
A tabela abaixo compara o FinOps 1.0 com o FinOps para IA que está surgindo:
| Recurso | FinOps inicial da nuvem | FinOps atual para IA (API)
|------------------|--------------------------------|----------------------------------------
| Unidade de custo | Hora de VM, GB de armazenamento| Token de entrada, token de saída
-------------------|--------------------------------|-----------------------------------------
| Driver de custo | Recursos ociosos, | Eficiência do prompt,
| | tráfego de saída de rede | escolha do modelo
-------------------|--------------------------------|-----------------------------------------
| Visibilidade | Logs de cobrança diários/horários | Telemetria por transação em tempo real
-------------------|--------------------------------|-----------------------------------------
| Otimização | Desligar servidores | - Reescrever o prompt/código
| | | - Seleção de modelo em tempo real
-------------------|--------------------------------|-----------------------------------------
Para gerenciar de verdade os custos de aplicações de IA, não dá para esperar a fatura chegar. Precisamos de inteligência FinOps embarcada na própria camada de aplicação, reportando cada token enviado ou recebido. É aí que entra o OpenTelemetry (OTel) para nos salvar.
Tutorial: instrumentando seu agente de IA com OpenTelemetry
O OpenTelemetry é um framework open source que oferece um padrão único para coletar dados de observabilidade (traces, métricas e logs). Podemos usar seus recursos de tracing para envolver nossas chamadas a LLMs e injetar o contexto FinOps essencial.
O exemplo a seguir mostra como implementar o rastreamento de alocação de custos FinOps para agentes de IA usando OpenTelemetry e o Agent Development Kit (ADK) do Google.
Esse código é a sua chave para a liberdade FinOps. Ele garante que cada token consumido pelo seu agente de IA seja imediatamente marcado com o dono do orçamento correto. Chega de adivinhação!
O código completo, pronto para rodar, está aqui: https://github.com/antweiss/finops-ai-otel.
AVISO IMPORTANTE: não use em produção!
Neste tutorial, usamos o ConsoleSpanExporter para imprimir os dados brutos do trace no seu terminal. Em produção, você NUNCA faria isso!
Em vez disso, você trocaria o exporter de console por um OTLP Exporter dedicado, que envia os dados para um serviço de backend robusto, como:
- Google Cloud Trace: a opção nativa para quem usa o Google Cloud.
- Um backend de observabilidade gerenciado: como Jaeger, Datadog ou New Relic.
- Uma plataforma dedicada de gestão FinOps, como o DoiT Cloud Intelligence
Esses backends permitem consultar e agregar os dados, gerando relatórios FinOps como: "Mostre o total de tokens usados em que finops.project_code seja 'BLOG-FINOPS-001' nos últimos 30 dias." É assim que você transforma um trace em um relatório de custos!
Passos 1 e 2: prepare-se para rodar
Você já conhece o procedimento! Clone o repositório, instale as dependências e configure sua chave de API.
git clone https://github.com/antweiss/finops-ai-otel.git
cd finops-ai-otel
pip install -r requirements.txt
export GEMINI_API_KEY="YOUR_API_KEY_HERE"
Passo 3: rode o código e veja os tokens jorrarem!
Quando você executa o arquivo agent.py, o superpoder FinOps é ativado dentro da função run_finops_session.
python agent.py
Como as tags FinOps entram no jogo (o passo a passo do código)
O objetivo é envolver toda a atividade do agente em um Span personalizado do OpenTelemetry, que carrega os detalhes do orçamento.
Iniciando o Span FinOps:
with tracer.start_as_current_span("adk-agent-session") as span:
É essa linha que faz toda a mágica! Iniciamos um span e o declaramos como o span ativo atual. Qualquer código subsequente também instrumentado com OTel (como as chamadas internas de LLM do Google ADK) cria automaticamente seus próprios spans como filhos desse span pai ativo.
Adicionando os metadados FinOps (tags):
span.set_attribute("finops.team_id", team_id)
span.set_attribute("finops.project_code", project_code)
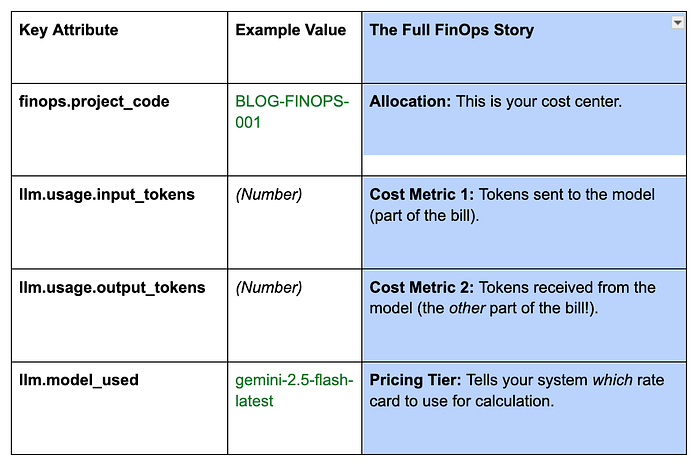
Injetamos os detalhes do centro de custo bem aqui! Como os spans internos do ADK (que contêm a contagem de tokens) são filhos desse span, seu backend de tracing vai mostrar todo o uso de tokens diretamente abaixo do finops.project_code. Alocação resolvida!
As métricas FinOps essenciais
def setup_opentelemetry_tracer():
"""Configures the Tracer to output to the console for a runnable demo."""
# 1. Create a TracerProvider
provider = TracerProvider()
# 2. Add a simple processor that exports traces to the console
# This shows the raw trace data and attributes!
provider.add_span_processor(SimpleSpanProcessor(ConsoleSpanExporter()))
# 3. Set it as the global provider
trace.set_tracer_provider(provider)
return trace.get_tracer("finops.adk.agent")
A saída do ConsoleSpanExporter é o seu relatório de custos imediato. Procure pelo span aninhado da chamada ao LLM para ver o quadro completo e faturável (os atributos finops.* são definidos pelo código de exemplo, enquanto os atributos e métricas llm.* vêm do LLMAgent do ADK):
FinOps avançado: propagando spans em fluxos multiagente
E quando temos fluxos complexos, em que um agente delega trabalho a outro? É aí que o poder do OpenTelemetry brilha.
- No modelo do OTel, quando um agente (o pai) chama outro agente ou ferramenta (o filho), o contexto do trace do span pai é automaticamente propagado por toda a cadeia de chamadas.
- Toda a sequência de agentes e ferramentas é executada dentro do contexto do Span FinOps inicial.
- Ou seja, sua única tag FinOps de nível superior cobre toda a coreografia complexa e de várias etapas entre os agentes — você ganha um relatório de custos unificado e auditável para o workflow inteiro! Esse recurso é herdado da instrumentação padrão do OTel usada pelo ADK.
Links
Para se aprofundar nas bases que tornam essa solução FinOps possível:
Confirma o suporte nativo do ADK à instrumentação com OpenTelemetry.
Primeiros passos com o OpenTelemetry
Explica os princípios fundamentais de Spans, Context e Context Propagation.
Detalha os tipos de agentes (LlmAgent, SequentialAgent) que se beneficiam desse tracing.
No próximo post, vamos mostrar como implementar guardrails de custo eficazes para suas aplicações de IA.