In un mondo sempre più guidato dai dati, saper cercare e recuperare le informazioni in modo efficiente è diventato cruciale. Vertex AI Agent Builder di Google Cloud è uno strumento potente che mette a frutto l’esperienza di Google nella ricerca e nell’AI conversazionale per realizzare applicazioni di Gen AI. Tra le funzionalità più recenti spicca Search Tuning (ancora in Preview al momento in cui scriviamo), che consente di affinare il modello di ricerca per rispondere meglio alle esigenze del proprio settore o della propria azienda.
In questo articolo presentiamo brevemente il servizio (rimandando alla documentazione ufficiale per ogni approfondimento) e mettiamo a disposizione uno script per i controlli preliminari sui dati, così da partire con il piede giusto e mantenere il search tuning sui binari.
Cos’è Vertex AI Agent Builder?
Partiamo dalle basi: dato che, da sviluppatori, ai nomi teniamo, e dato che stare al passo con le denominazioni di queste funzionalità non è stato semplice, facciamo chiarezza. Lanciato all’inizio del 2023 come Gen App Builder, è stato poco dopo ribattezzato Vertex AI Search and Conversation, fino a diventare oggi Vertex AI Agent Builder.
Ora che sappiamo come chiamare la bestia, vediamo cosa può fare per noi.
Con Vertex AI Agent Builder, Google Cloud rende davvero semplice per la sua azienda mettere a frutto la Gen AI. Il servizio elimina gran parte del lavoro di base necessario per costruire un’AI conversazionale, un’esperienza di ricerca semantica o persino un sistema di Retrieval Augmented Generation (RAG), e le permette di sfruttare i foundation model all’avanguardia di Google e la sua tecnologia di ricerca di fama mondiale, frutto di 25 anni di evoluzione.
Rispetto ad altre proposte della suite Vertex AI (come l’API Gemini 1.5 Pro o Vector Search), si colloca sul versante più managed: offre quindi minore personalizzazione e flessibilità, ma in cambio garantisce un time-to-market più rapido e riduce la necessità di competenze interne, spesso difficili da reperire.
All’interno di Vertex AI Agent Builder abbiamo accesso a Vertex AI Agents e Vertex AI Search:
- Vertex AI Agents consente di costruire facilmente interfacce utente conversazionali grazie a una piattaforma di natural language understanding basata su large language model (LLM).
- Vertex AI Search, invece, aiuta a creare esperienze di ricerca e di raccomandazione potenziate dall’AI.
Oggi ci concentriamo su Vertex AI Search, perché è il prodotto che offre Search Tuning e per il quale presentiamo lo script di verifica dei dati.
Per un’introduzione completa, le consigliamo di consultare la documentazione qui.
Cos’è Vertex AI Search?
All’interno di Vertex AI Search è possibile costruire search app e recommendation app. Oggi ci concentriamo sulle search app.
Tra le funzionalità principali troviamo:
- Natural language understanding e ricerca semantica pronti all’uso. La ricerca semantica coglie il contesto e l’intento dietro a una query. Approcci più tradizionali come la ricerca per parole chiave si basano invece sulla corrispondenza esatta di termini specifici, senza coglierne il significato o il contesto. Per esempio, alla query "Quando Apple ha annunciato l’ultimo iPhone?", la ricerca semantica capisce che stiamo parlando di Apple Inc. e non del suo frutto preferito.
- Capacità native di riconoscere sinonimi, correggere errori di ortografia e suggerire automaticamente le ricerche.
- Riassunti generati dall’AI e ricerca conversazionale per documenti non strutturati. Si può ad esempio decidere quali risposte restituire:
- Ricerca (single-turn)
- Ricerca con risposta (single-turn search con riassunto)
- Ricerca con follow-up (multi-turn search)
La configurazione di Vertex AI Search si articola, ad alto livello, in 2 fasi:
- Preparazione: si imposta un data store e si caricano i dati strutturati o non strutturati. I dati vengono elaborati, suddivisi in chunk e trasformati in embedding insieme ai relativi metadati. Vengono poi memorizzati per il recupero in Vector Search, il database vettoriale ad alte prestazioni di Google Cloud, descritto qui. Restano comunque alcune opzioni di personalizzazione: può portare il proprio schema, i propri embedding (in Preview al momento in cui scriviamo) e persino personalizzare parsing e chunking.
- Runtime: è la fase in cui si eseguono le query effettive a partire dall’input dell’utente. Il sistema recupera i documenti pertinenti e, se lo desidera, genera una risposta a partire da essi. Anche qui c’è margine di personalizzazione: può ovviamente portare i propri prompt, definire controlli per filtrare i risultati restituiti e scegliere se ottenere risposte brevi (snippet) o paragrafi più lunghi (extractive answer o segmenti) nelle risposte. Non può invece portare il proprio ranker, ma su questo torneremo più avanti.
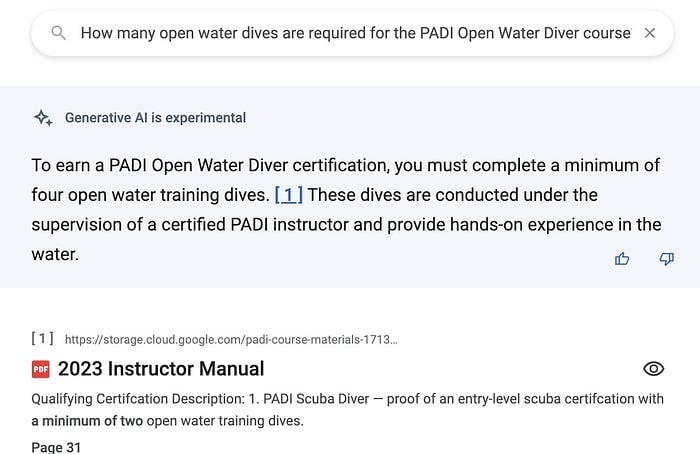
Esempio di un segmento estratto da un data store non strutturato (PDF). Si noti che il numero di pagina del file originale è incluso nel riferimento. (screenshot adattato per esigenze di spazio)
Cos’è Search Tuning?
E se la qualità dei risultati di ricerca non la convince fino in fondo? Per i data store non strutturati può ricorrere a Search Tuning (in Preview al momento in cui scriviamo). Se i dati su cui vuole effettuare ricerche sono molto specifici della sua azienda, un modello generico potrebbe avere difficoltà a fornire un retrieval accurato. Possiamo aiutarla; e per farlo basta fornire al modello un po’ di dati.
Come si usa Search Tuning?
Più nello specifico, dovrà preparare 3 dataset di training, eventualmente 4:
- Training query: sono le query di ricerca che si aspetta di ricevere dagli utenti del suo sistema. Per esempio:
Qual è il rapporto massimo studenti/istruttore per le immersioni in acque confinate?
2. Extractive segment: sono frammenti tratti dai documenti del data store (il suo corpus). Alcuni segmenti dovranno rispondere ad alcune delle query definite sopra, altri no: entrambi hanno il loro scopo, ovvero rinforzare positivamente o negativamente il modello. Inoltre questi segmenti devono essere sufficientemente lunghi. Per esempio:
## Rapporti
### Acque confinate 10:1 — È possibile aggiungere quattro studenti subacquei per ogni assistente certificato.
### Acque libere 8:1 — È possibile aggiungere due studenti subacquei per ogni assistente certificato
3. Relevance score: queste etichette di training mettono in relazione le query con gli extractive segment tramite un punteggio (numero intero non negativo): 0 indica che il segmento non è pertinente alla query e, più alto è il punteggio, più il segmento è pertinente per quella query. Per esempio:
In questo caso il relevance score sarebbe
1, perché il segmento è pertinente alla domanda posta.
4. (Opzionale) Test label: questi dati sono analoghi ai relevance score, ma vengono utilizzati per valutare le prestazioni del modello ottimizzato. Se non li forniamo, Search Tuning utilizzerà il 20% delle query delle training label definite al punto 3.
Cosa potrebbe andare storto?
Questi dati vanno forniti come file e devono rispettare una formattazione specifica e determinati requisiti. Alcuni dei nostri clienti hanno però riscontrato problemi nell’uso del servizio, ricevendo un Error Code 13 con il messaggio "Internal error encountered. Please try again. If the issue persists, please contact our support team."
La causa di fondo era che non tutti i file rispettavano i requisiti indicati nella documentazione, ma sfortunatamente il messaggio di errore non lo faceva capire. Niente paura: DoiT è qui per aiutarla. Abbiamo sviluppato alcuni semplici controlli che permettono di individuare in anticipo i file mal formattati ed evitare l’errore. Lo script è disponibile su GitHub e si esegue così:
python search_tuning_checks.py.py <corpus_path> <query_path> <scoring_path>`.
Un esempio di output potrebbe essere:
General dataset checks
- - - - - - - - - - -
Number of segments in Corpus file that don't have a match in Scoring file: 6030
Number of segments in Scoring file that don't have a match in Corpus file: 1551
Number of queries in Query file that don't have a match in Scoring file: 0
Number of queries in Scoring file that don't have a match in Query file: 0
Documentation dataset checks
- - - - - - - - - - - - - -
Training query requirements met: ✅ met
|___ Subcheck: At least one extractive segment per query: ✅ met
|___ Subcheck: At least 10 000 additional extractive segments: ✅ met
Extractive segment requirements met: ✅ met
Relevance score requirements met: ✅ met
|___ Subcheck: At least 100 segments that contain query answers: ✅ met
|___ Subcheck: At least 10 000 random segments: ❌ not met
|___ Subcheck: At least 10 000 segments with 0 as score: ✅ met
Corpus file requirements met: ❌ not met
Query file requirements met: ✅ met
|___ Subcheck: Same ids in query and scoring data: ✅ met
|___ Subcheck: Column 'score' contains non-negative integer values: ✅ met
Training labels requirements met: ✅ met
I `general data checks` si limitano a verificare l’integrità dei dati forniti: controllano che tutti gli ID dei segmenti corrispondano a uno score, da un lato, e che tutti gli ID delle query corrispondano a uno score, dall’altro.
I `documentation dataset checks` eseguono i seguenti controlli, descritti nella documentazione di Google Cloud:
- Sui dati di training in generale (i primi 3 controlli)
- Sul file Corpus
- Sul file Query
- Sul file delle Training label
Vale la pena assicurarsi di ottenere ‘✅’ ovunque prima di inviare i file, perché il ciclo di feedback può durare diverse ore.
In questo articolo abbiamo esplorato Vertex AI Agent Builder di Google Cloud, soffermandoci sulla funzionalità Search Tuning all’interno di Vertex AI Search. Search Tuning consente di affinare i modelli di ricerca per ottenere maggiore accuratezza e pertinenza. Il processo richiede dataset specifici: training query, extractive segment e relevance score. Per affrontare i tipici problemi di formattazione che possono generare errori, abbiamo presentato uno script Python utile a effettuare i controlli preliminari sui dati. Lo strumento aiuta ad assicurarsi che i dataset soddisfino i requisiti necessari prima dell’invio, con un risparmio di tempo e una maggiore efficacia delle attività di search tuning.
Sta riscontrando altri problemi? Visiti doit.com/services e scopra come possiamo aiutarla.