No mundo atual, movido a dados, conseguir buscar e recuperar informações com eficiência é fundamental. O Vertex AI Agent Builder, do Google Cloud, é uma ferramenta poderosa que combina a expertise do Google em busca e IA conversacional para criar aplicações de Gen AI. Um dos seus recursos mais recentes é o Search Tuning (ainda em Preview no momento em que escrevemos), que permite ajustar o modelo de busca para atender melhor às necessidades do seu setor ou da sua empresa.
Neste post, vamos explorar brevemente esse serviço (e indicar a documentação para você se aprofundar) e disponibilizar um script para fazer verificações preliminares nos dados, garantindo que você comece com o pé direito e que seus esforços de search tuning sigam no caminho certo.
O que é o Vertex AI Agent Builder?
Antes de mais nada: como desenvolvedores, a gente liga para nomes — e como pode ter sido difícil acompanhar a nomenclatura desses produtos, vamos esclarecer: lançado inicialmente como Gen App Builder, no início de 2023, foi rebatizado pouco depois como Vertex AI Search and Conversation e hoje atende pelo nome de Vertex AI Agent Builder.
Agora que esclarecemos isso e já sabemos como chamar o bicho, vamos ao que ele pode fazer por você!
O Vertex AI Agent Builder é a forma como o Google Cloud facilita ao máximo o uso de Gen AI por você e pelo seu negócio. Ele abstrai boa parte do trabalho braçal necessário para construir uma IA conversacional, uma experiência de busca semântica ou até mesmo um sistema de Retrieval Augmented Generation (RAG), e ajuda você a aproveitar os modelos de fundação de última geração e a tecnologia de busca mundialmente reconhecida do Google, fruto de 25 anos de desenvolvimento.
Comparado a outras ofertas do conjunto Vertex AI (como a API do Gemini 1.5 Pro ou o Vector Search), ele fica no lado mais gerenciado do espectro e, portanto, oferece menos personalização e flexibilidade — algo que você troca por um time-to-market mais rápido e por menos dependência de talentos internos escassos.
Dentro do Vertex AI Agent Builder, temos acesso aos Vertex AI Agents e ao Vertex AI Search:
- Os Vertex AI Agents oferecem uma forma fácil de construir interfaces conversacionais a partir de uma plataforma de compreensão de linguagem natural baseada em large language models (LLMs).
- Já o Vertex AI Search ajuda você a criar experiências de busca e recomendação com IA.
Hoje vamos focar no Vertex AI Search, já que é o produto que oferece o Search Tuning e para o qual apresentaremos um script de verificação de dados.
Para uma introdução completa, consulte a documentação aqui.
O que é o Vertex AI Search?
Dentro do Vertex AI Search, podemos construir apps de busca e apps de recomendação. Nosso foco hoje são os apps de busca.
Alguns dos principais recursos são:
- Compreensão de linguagem natural e busca semântica prontas para usar. A busca semântica entende o contexto e a intenção por trás de uma consulta. Já abordagens mais tradicionais, como a busca por palavras-chave, dependem da correspondência exata de termos específicos, sem entender o raciocínio ou o contexto por trás deles. Por exemplo, ao buscar "Quando a Apple anunciou o último iPhone?", a busca semântica vai entender que estamos falando da Apple Inc. e não da sua fruta favorita.
- Recursos nativos para entender sinônimos, corrigir grafia e sugerir buscas automaticamente.
- Sumarização com IA generativa e busca conversacional para documentos não estruturados. Por exemplo, podemos definir quais respostas são entregues:
- Busca (single-turn)
- Busca com resposta (single-turn com sumarização)
- Busca com follow-ups (multi-turn)
Em alto nível, configurar o Vertex AI Search envolve 2 etapas:
- Preparação: configuramos um data store e fazemos a ingestão dos nossos dados estruturados ou não estruturados. Eles são processados, divididos em chunks e transformados em embeddings junto com seus metadados. Tudo é armazenado para recuperação no Vector Database de alta performance do Google Cloud, chamado Vector Search. Você ainda tem algumas opções de personalização: pode trazer seu próprio schema, seus próprios embeddings (em Preview no momento em que escrevemos) e até customizar o parsing e o chunking.
- Runtime: é quando fazemos a consulta de fato, usando a entrada do usuário. O sistema recupera os documentos relevantes e gera uma resposta com base neles (se for o que você quer). Aqui também há espaço para personalização: você obviamente traz seus próprios prompts, pode definir controles para, por exemplo, filtrar os resultados retornados, e escolher se quer respostas curtas (snippets) ou parágrafos mais longos (extractive answers ou segmentos) nas respostas. Você não pode trazer seu próprio ranker, mas já já a gente fala mais sobre isso!
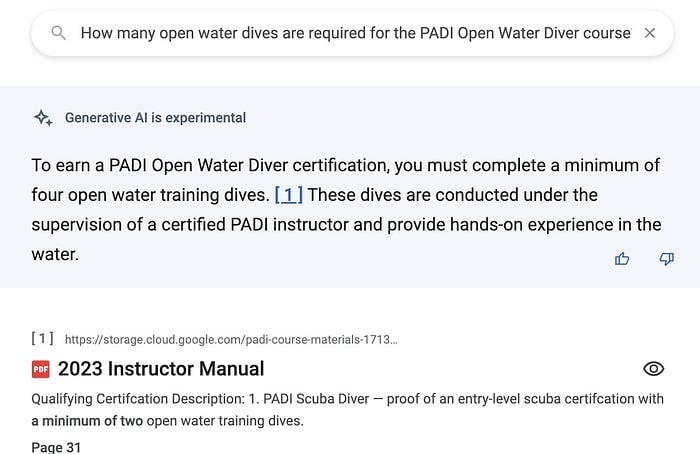
Exemplo de um segmento extrativo em um data store de dados não estruturados (PDF). Note que o número da página do arquivo original é incluído na referência. (captura ajustada por questões de espaço)
O que é Search Tuning?
E se você não estiver 100% satisfeito com a qualidade dos resultados de busca? Você pode recorrer ao recurso de Search Tuning (em Preview no momento em que escrevemos) para seus data stores não estruturados. Digamos que os dados em que você quer buscar sejam muito específicos da sua empresa — isso pode dificultar uma recuperação precisa por parte de um modelo padrão. Mas a gente pode ajudar; e para isso, basta alimentá-lo com alguns dados!
Como usar o Search Tuning?
Mais especificamente, você precisará trazer 3 — e potencialmente 4 — conjuntos de dados de treinamento:
- Training queries: são as consultas de busca que você espera que seus usuários façam ao seu sistema. Por exemplo:
Qual é a proporção máxima de aluno por instrutor para mergulhos em águas confinadas?
2. Extractive segments: são trechos extraídos dos documentos no data store (o seu corpus). Alguns segmentos vão responder a algumas das consultas definidas acima, outros não (ambos têm seu papel: reforçar o modelo de forma positiva e de forma negativa). Esses segmentos também precisam ser longos o suficiente. Por exemplo:
## Proporções
### Águas Confinadas 10:1 — Pode-se adicionar quatro mergulhadores aprendizes por assistente certificado.
### Águas Abertas 8:1 — Pode-se adicionar dois mergulhadores aprendizes por assistente certificado
3. Relevance scores: esses rótulos de treinamento relacionam as consultas com os segmentos extrativos por meio de uma pontuação (inteiro não negativo), em que 0 indica que o segmento não é relevante para a consulta — quanto maior a pontuação, mais relevante é o segmento para uma determinada consulta. Por exemplo:
Nesse caso, a pontuação de relevância seria
1, já que o segmento é relevante para a pergunta feita.
4. (Opcional) Test labels: esses dados são parecidos com os relevance scores, mas servem para avaliar o desempenho do modelo ajustado. Se você não fornecer esses dados, o Search Tuning vai usar 20% das consultas dos rótulos de treinamento definidos no item 3.
O que pode dar errado?
Esses dados são fornecidos como arquivos e exigem formatação específica, além de atender a alguns requisitos. Alguns dos nossos clientes estavam enfrentando problemas ao tentar usar o serviço, recebendo um Error Code 13 com a mensagem "Internal error encountered. Please try again. If the issue persists, please contact our support team."
A causa raiz acabou sendo que nem todos os arquivos atendiam aos requisitos descritos na documentação, mas, infelizmente, a mensagem de erro não revelava essa informação. Não se desespere; DoiT ao resgate! Codamos algumas verificações simples que ajudam você a identificar arquivos mal formatados logo de cara e evitar o erro. O script está disponível no GitHub e é tão simples de rodar quanto:
python search_tuning_checks.py.py <corpus_path> <query_path> <scoring_path>`.
Uma saída de exemplo poderia ser mais ou menos assim:
General dataset checks
- - - - - - - - - - -
Number of segments in Corpus file that don't have a match in Scoring file: 6030
Number of segments in Scoring file that don't have a match in Corpus file: 1551
Number of queries in Query file that don't have a match in Scoring file: 0
Number of queries in Scoring file that don't have a match in Query file: 0
Documentation dataset checks
- - - - - - - - - - - - - -
Training query requirements met: ✅ met
|___ Subcheck: At least one extractive segment per query: ✅ met
|___ Subcheck: At least 10 000 additional extractive segments: ✅ met
Extractive segment requirements met: ✅ met
Relevance score requirements met: ✅ met
|___ Subcheck: At least 100 segments that contain query answers: ✅ met
|___ Subcheck: At least 10 000 random segments: ❌ not met
|___ Subcheck: At least 10 000 segments with 0 as score: ✅ met
Corpus file requirements met: ❌ not met
Query file requirements met: ✅ met
|___ Subcheck: Same ids in query and scoring data: ✅ met
|___ Subcheck: Column 'score' contains non-negative integer values: ✅ met
Training labels requirements met: ✅ met
Os `general data checks` apenas fazem uma verificação de integridade dos dados fornecidos: se todos os IDs dos segmentos correspondem a uma pontuação, de um lado, e se todos os IDs das consultas correspondem a uma pontuação, do outro.
Já os `documentation dataset checks` executam as seguintes verificações descritas na documentação do Google Cloud:
- Para os dados de treinamento em geral (3 primeiras verificações)
- Para o arquivo Corpus
- Para o arquivo Query
- Para o arquivo Training labels
Vale a pena garantir um '✅' em tudo antes de enviar seus arquivos, já que o ciclo de feedback pode levar algumas horas!
Este artigo explorou o Vertex AI Agent Builder, do Google Cloud, com foco no recurso Search Tuning dentro do Vertex AI Search. O Search Tuning permite ajustar modelos de busca para ganhar precisão e relevância. O processo exige conjuntos de dados específicos: training queries, extractive segments e relevance scores. Para resolver problemas comuns de formatação que podem causar erros, apresentamos um script em Python que ajuda nas verificações preliminares dos dados. Essa ferramenta pode garantir que seus conjuntos de dados atendam aos requisitos antes do envio, economizando tempo e melhorando a eficácia dos seus esforços de search tuning.
Está enfrentando outros problemas? Acesse doit.com/services e descubra como podemos ajudar!