Quando si carica un file di oltre 5 MB su un bucket AWS S3, l'SDK o la CLI di AWS suddivide automaticamente il caricamento in più richieste HTTP PUT. È una soluzione più efficiente, permette di riprendere i caricamenti e — se una delle parti non va a buon fine — viene ricaricata senza interrompere l'avanzamento complessivo.

Non lasciare residui dopo i caricamenti su AWS S3
I multipart upload nascondono però un'insidia:
Se il caricamento si interrompe prima che l'oggetto sia stato trasferito per intero, le parti già caricate continuano a essere fatturate finché non vengono eliminate.
Il risultato è un aumento dei costi di storage che spesso passa inosservato.
Continua a leggere per scoprire come individuare le parti già caricate e come ridurre i costi quando ci sono multipart upload incompleti.
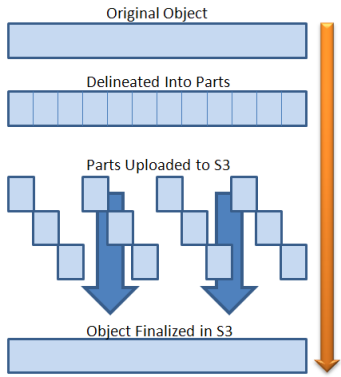
Immagine tratta dal post di Jeff Barr
Come trovare le parti caricate nella Console AWS S3?
Ed è qui che la cosa si fa interessante: questi oggetti non sono visibili nella Console AWS S3.
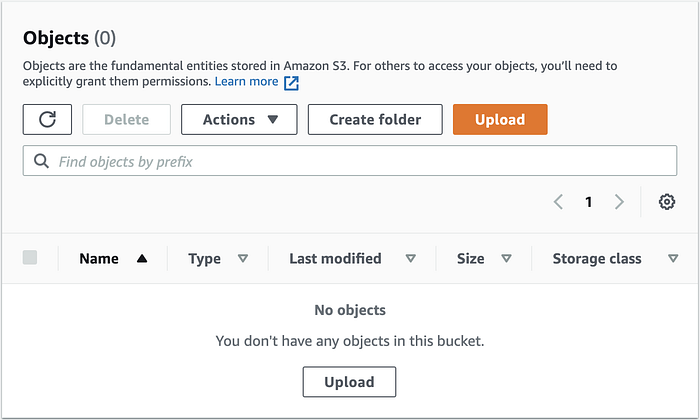
Per scrivere questo articolo ho creato un bucket S3 e caricato un file da 100 GB, interrompendo il processo dopo i primi 40 GB.
Aprendo la Console S3, il bucket risultava contenere 0 oggetti e la console non mostrava i 40 GB già trasferiti (multipart).
Cliccando poi sulla scheda Metrics, la dimensione del bucket risultava di 40 GB.
Possono volerci diverse ore prima che le metriche aggiornate vengano visualizzate.
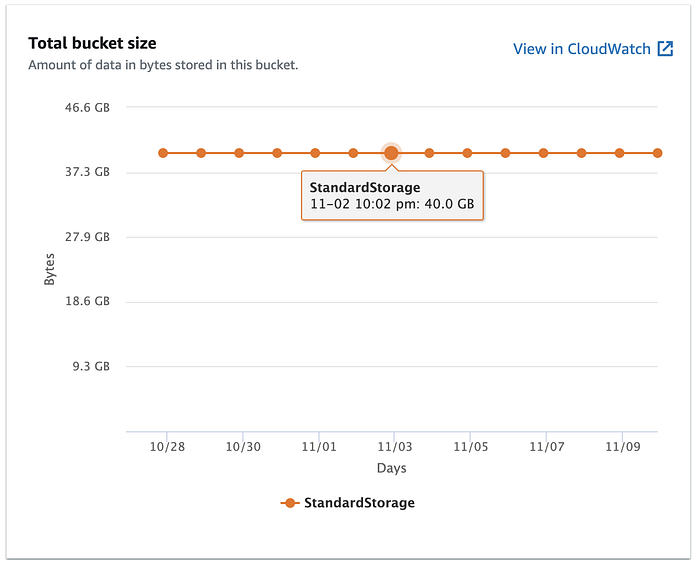
Significa che, anche se l'oggetto non compare in console perché il caricamento non è stato completato, le parti già trasferite vengono comunque fatturate.
Come si affronta il problema nella pratica?
Mi sono confrontato con diversi colleghi di aziende che gestiscono account AWS con un consumo mensile importante di S3.
Quasi tutti avevano tra i 100 MB e i 10 TB (o più) di multipart upload incompleti. Il dato ricorrente è chiaro: più è alto il consumo di S3 e più datato è l'account, maggiore è la quantità di oggetti incompleti accumulati.
Calcolare la dimensione delle parti di un singolo oggetto multipart
Per prima cosa, dalla AWS CLI, elenca i multipart upload in corso con il seguente comando:
aws s3api list-multipart-uploads --bucket <bucket-name>
L'output è la lista di tutti gli oggetti incompleti suddivisi in più parti:
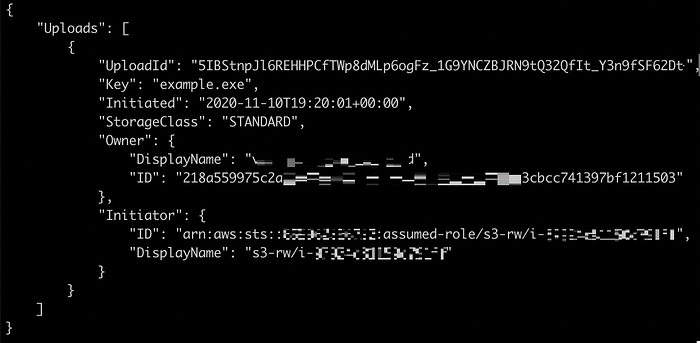
A questo punto, elenca tutte le parti del multipart upload con il comando list-parts, indicando il valore di "UploadId":
aws s3api list-parts --upload-id 5IBStnpJl6REH... --bucket <bucket-name> --key example.exe
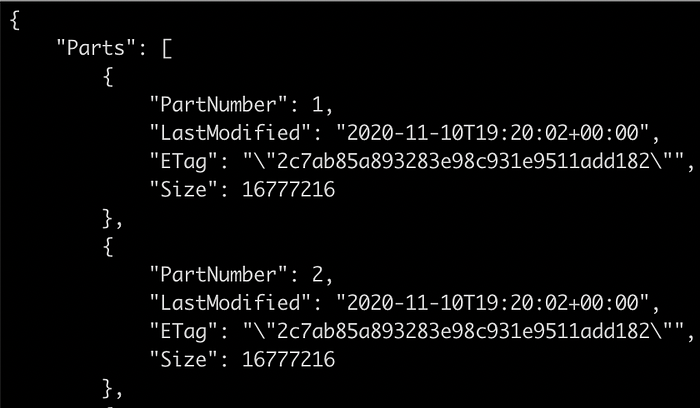
Quindi somma la dimensione (in byte) di tutte le parti caricate e converti il risultato in GB con JQ (un processore JSON da riga di comando):
jq '.Parts | map(.Size/1024/1024/1024) | add'
Per eliminare manualmente un multipart upload, il comando è:
aws s3api abort-multipart-upload --bucket <bucket-name> --key example.exe --upload-id 5IBStnpJl6REH...
Come smettere di pagare per i multipart upload incompleti
A livello di bucket puoi creare una lifecycle rule che elimini automaticamente gli oggetti multipart incompleti dopo qualche giorno.
"Una S3 Lifecycle configuration è un insieme di regole che definiscono le azioni che Amazon S3 applica a un gruppo di oggetti." ( documentazione AWS).
Di seguito due soluzioni:
- una soluzione manuale per i bucket esistenti;
- una soluzione automatica per i nuovi bucket.
Eliminare i multipart upload nei bucket esistenti
In questa soluzione creerai una object lifecycle rule per rimuovere i vecchi oggetti multipart in un bucket già esistente.
Attenzione: massima cautela nel definire una Lifecycle rule. Un errore di configurazione può eliminare oggetti già presenti nel bucket.
Apri la console AWS S3, seleziona il bucket desiderato e vai alla scheda Management.
In Lifecycle rules clicca su Create lifecycle rule.
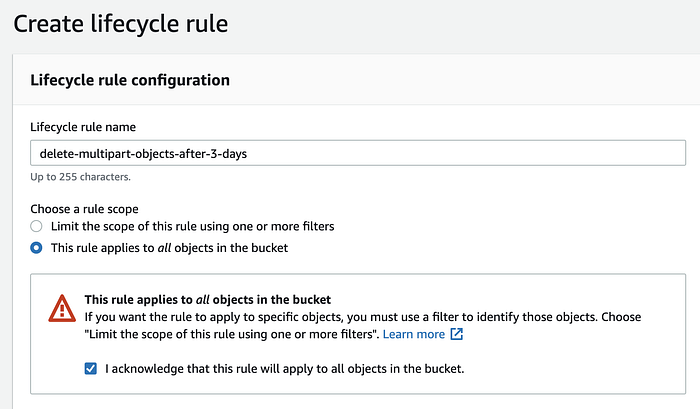
Assegna un nome alla lifecycle rule e imposta lo scope su tutti gli oggetti del bucket.
Spunta la casella "I acknowledge that this rule will apply to all objects in the bucket".
Vai poi su Lifecycle rule actions e seleziona "Delete expired delete markers or incomplete multipart upload".
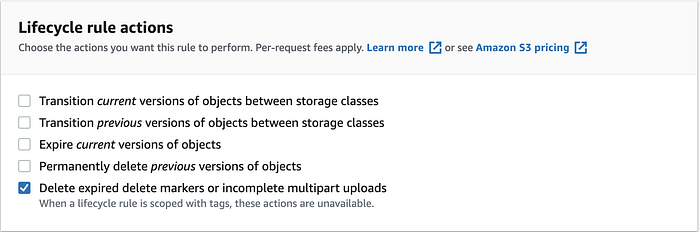
Spunta "Delete incomplete multipart uploads" e imposta il Number of days in base alle tue esigenze (a mio avviso tre giorni sono sufficienti per portare a termine i caricamenti rimasti in sospeso).
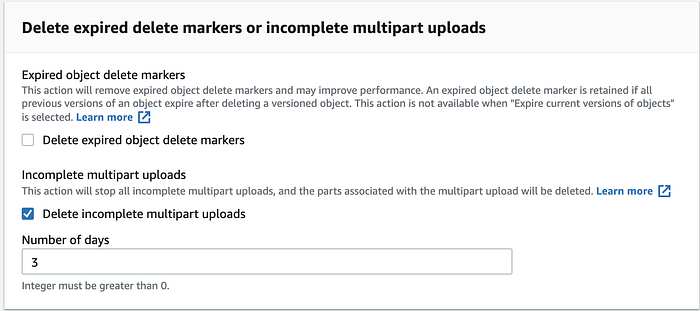
Una volta completati questi passaggi, le parti multipart caricate verranno eliminate, ma non in tempo reale (ci vorrà un po').
Due aspetti da tenere a mente:
- le operazioni di eliminazione sono gratuite;
- una volta definita la lifecycle rule, i dati che verranno eliminati non sono più fatturati.
Creare una lifecycle rule per i nuovi bucket
In questa soluzione creerai una lifecycle rule che si applica automaticamente ogni volta che viene creato un nuovo bucket.

Si utilizza un semplice script di automazione Lambda, che si attiva alla creazione di ogni nuovo bucket. La funzione Lambda implementa una lifecycle rule che elimina tutti gli oggetti multipart con più di 3 giorni.
Nota: dato che EventBridge opera solo nella region in cui viene creato, devi distribuire la funzione Lambda in ogni region in cui operi.
S3 Management Console — Guarda il video
Come implementare l'automazione
- Abilita un trail di AWS CloudTrail. Una volta configurato il trail, potrai usare AWS EventBridge per attivare una funzione Lambda.
- Crea una nuova funzione Lambda, scegliendo Python 3.8 come Runtime.
- Incolla il codice qui sotto (Github gist):
4. Seleziona create function.
5. Torna in cima alla pagina; in Trigger seleziona "Add trigger" e, nella configurazione del trigger, scegli EventBridge.
Crea quindi una nuova regola assegnandole un nome e una descrizione.
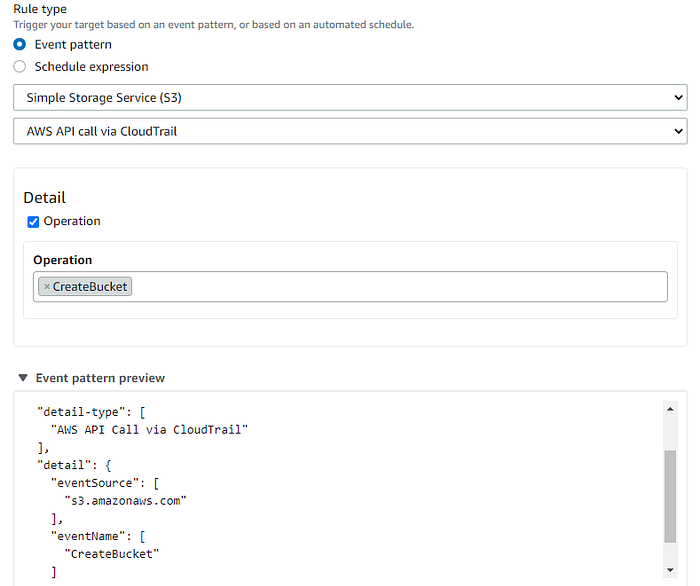
6. In rule type scegli Event pattern, poi seleziona Simple Storage Services (S3) e AWS API call via CloudTrail nelle due caselle sottostanti.
Nella casella Detail, in Operation scegli CreateBucket.
Scorri in basso e clicca sul pulsante Add.
7. Scorri fino alla scheda Basic settings, seleziona Edit → IAM role e associa la policy riportata di seguito.
Questa policy consente alla funzione Lambda di creare una lifecycle configuration per tutti i bucket dell'account AWS.
{
"Version": "2012-10-17",
"Statement": [\
{\
"Sid": "VisualEditor0",\
"Effect": "Allow",\
"Action": "s3:PutLifecycleConfiguration",\
"Resource": "*"\
}\
]
}
8. Crea un bucket per verificare che la funzione Lambda funzioni correttamente.
9. Et voilà! Da questo momento, ogni volta che crei un nuovo bucket (nella region configurata), la funzione Lambda genererà automaticamente una lifecycle per quel bucket.
Grazie per la lettura! Per restare aggiornato, seguici sul DoiT Engineering Blog , sul canale LinkedIn di DoiT e sul canale Twitter di DoiT . Per scoprire le opportunità di carriera, visita https://careers.doit-intl.com .