Lors de l'upload d'un fichier de plus de 5 Mo vers un bucket AWS S3, le SDK/CLI AWS découpe automatiquement le transfert en plusieurs requêtes HTTP PUT. C'est plus efficace, cela permet de reprendre les uploads interrompus, et — si l'une des parties échoue — elle est renvoyée sans interrompre la progression de l'upload.

Ne laissez pas de restes après vos uploads vers AWS S3
Les uploads multipart cachent toutefois un piège :
Si votre upload est interrompu avant que l'objet ne soit entièrement transféré, vous êtes facturé pour les parties déjà uploadées tant que vous ne les supprimez pas.
Résultat : une hausse invisible de vos coûts de stockage, qui ne saute pas aux yeux immédiatement.
Voyons comment identifier les parties d'objets déjà chargées et comment réduire les coûts en cas d'uploads multipart inachevés.
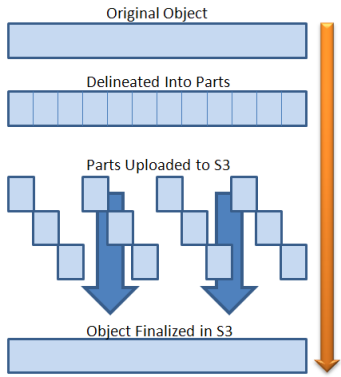
Image tirée de l'article de blog de Jeff Barr
Comment retrouver les parties d'objets chargées dans la console AWS S3 ?
C'est là que ça devient intéressant : vous ne pouvez pas voir ces objets dans la console AWS S3.
Pour les besoins de cet article, j'ai créé un bucket S3 et lancé l'upload d'un fichier de 100 Go. J'ai interrompu le processus après 40 Go transférés.
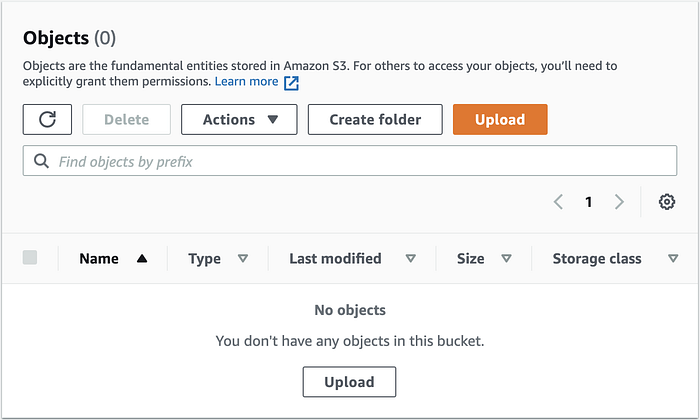
En accédant à la console S3, j'ai constaté que le bucket contenait 0 objet et que la console S3 n'affichait pas les 40 Go déjà uploadés (multipart).
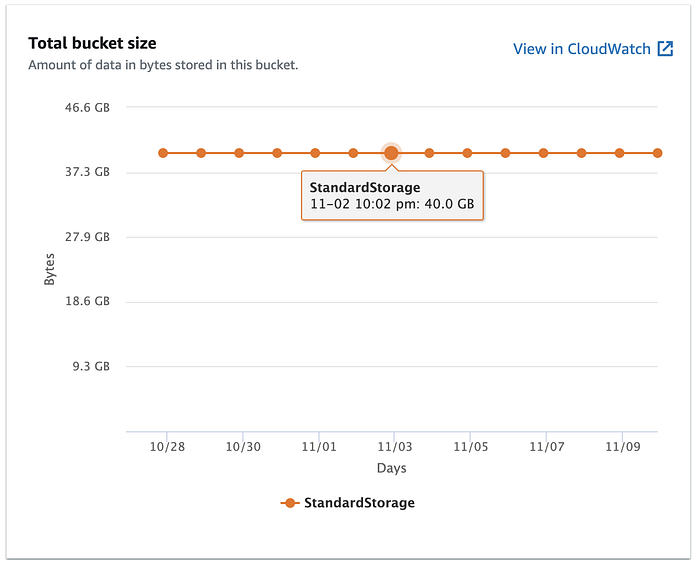
J'ai ensuite cliqué sur l'onglet Metrics et constaté que la taille du bucket était bien de 40 Go.
La mise à jour des métriques peut prendre plusieurs heures avant de s'afficher.
Autrement dit, même si l'objet n'apparaît pas dans la console parce que l'upload n'est pas allé à son terme, vous êtes tout de même facturé pour les parties déjà transférées.
Qu'en est-il dans la vraie vie ?
J'ai interrogé plusieurs collègues dans diverses entreprises qui exploitent un compte AWS avec une utilisation mensuelle d'AWS S3 conséquente.
La majorité d'entre eux cumulaient entre 100 Mo et plus de 10 To d'uploads multipart inachevés. Le constat partagé : plus l'utilisation de S3 est importante et plus le compte est ancien, plus les objets incomplets s'accumulent.
Calculer la taille des parties d'un objet multipart
Tout d'abord, depuis l'AWS CLI, listez les objets multipart en cours avec la commande suivante :
aws s3api list-multipart-uploads --bucket <bucket-name>
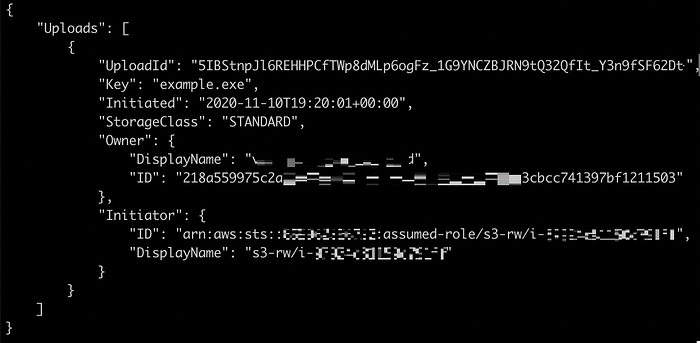
Cette commande renvoie la liste de tous les objets incomplets composés de plusieurs parties :
Listez ensuite toutes les parties de l'upload multipart à l'aide de la commande list-parts avec la valeur UploadId :
aws s3api list-parts --upload-id 5IBStnpJl6REH... --bucket <bucket-name> --key example.exe
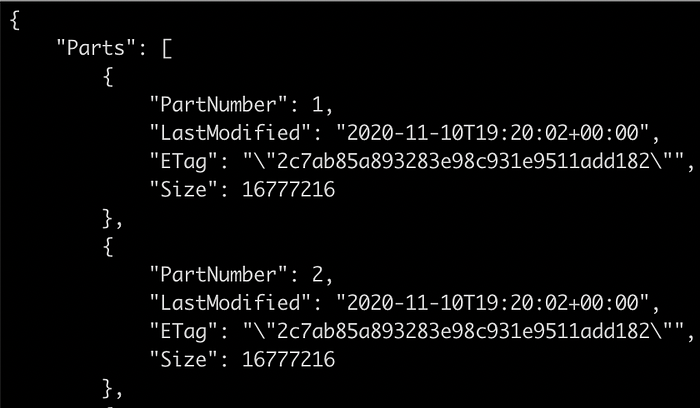
Additionnez ensuite la taille (en octets) de toutes les parties uploadées et convertissez le résultat en Go avec JQ (un processeur JSON en ligne de commande) :
jq '.Parts | map(.Size/1024/1024/1024) | add'
Pour supprimer manuellement un objet multipart, exécutez :
aws s3api abort-multipart-upload --bucket <bucket-name> --key example.exe --upload-id 5IBStnpJl6REH...
Comment cesser d'être facturé pour les uploads multipart inachevés ?
Au niveau du bucket, vous pouvez créer une lifecycle rule qui supprime automatiquement les objets multipart incomplets au bout de quelques jours.
Une configuration de cycle de vie S3 est un ensemble de règles qui définissent les actions qu'Amazon S3 applique à un groupe d'objets. (documentation AWS).
Voici deux approches :
- une solution manuelle pour les buckets existants ;
- une solution automatique pour la création de nouveaux buckets.
Supprimer les uploads multipart dans les buckets existants
Vous allez créer une règle de cycle de vie d'objets pour supprimer les anciens objets multipart d'un bucket existant.
Attention : soyez prudent lorsque vous définissez une lifecycle rule. Une erreur de définition peut entraîner la suppression d'objets existants dans votre bucket.
Ouvrez d'abord la console AWS S3, sélectionnez le bucket souhaité et accédez à l'onglet Management.
Sous Lifecycle rules, cliquez sur Create lifecycle rule.
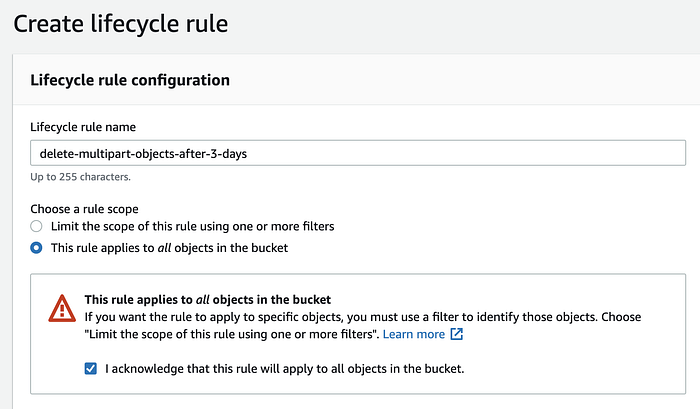
Donnez un nom à la lifecycle rule et choisissez la portée tous les objets du bucket.
Cochez la case I acknowledge that this rule will apply to all objects in the bucket.
Rendez-vous ensuite dans Lifecycle rule actions et cochez la case Delete expired delete markers or incomplete multipart upload.
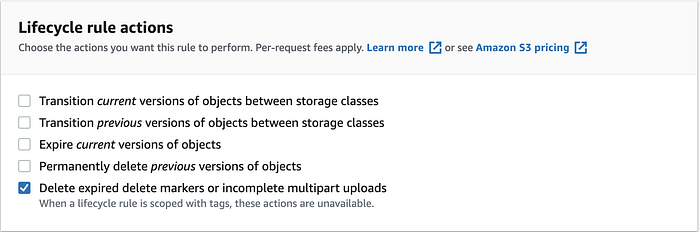
Cochez la case Delete incomplete multipart uploads et fixez le Number of days selon vos besoins (trois jours suffisent généralement pour terminer les uploads en cours).
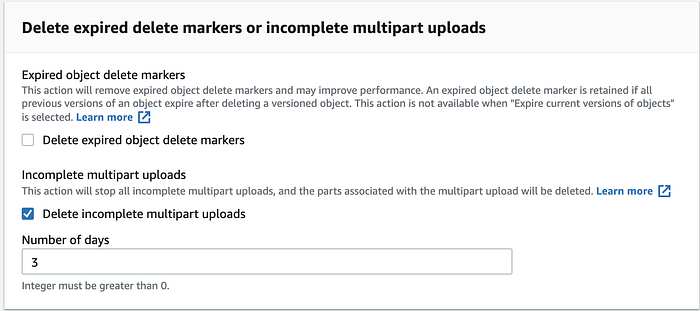
Une fois ces étapes effectuées, les fichiers multipart déjà uploadés seront supprimés, mais pas immédiatement (cela prendra un peu de temps).
Deux points à retenir :
- les opérations de suppression sont gratuites ;
- une fois la lifecycle rule définie, vous n'êtes plus facturé pour les données qui seront supprimées.
Créer une lifecycle rule pour les nouveaux buckets
Vous allez créer ici une lifecycle rule qui s'applique automatiquement à chaque création d'un nouveau bucket.

Le mécanisme repose sur un script d'automatisation Lambda simple, déclenché à chaque création d'un nouveau bucket. Cette fonction Lambda met en place une lifecycle rule qui supprime tous les objets multipart âgés de 3 jours.
Remarque : EventBridge ne s'exécutant que dans la région où il a été créé, vous devez déployer la fonction Lambda dans chaque région où vous opérez.
S3 Management Console — Voir la vidéo
Comment mettre en place cette automatisation ?
- Activez un trail AWS CloudTrail. Une fois le trail configuré, vous pouvez utiliser AWS EventBridge pour déclencher une fonction Lambda.
- Créez une nouvelle fonction Lambda avec Python 3.8 comme Runtime.
- Collez le code ci-dessous (gist Github) :
4. Sélectionnez create function.
5. Remontez en haut de la page, sous Trigger sélectionnez Add trigger puis, dans la configuration du déclencheur, choisissez EventBridge.
Créez ensuite une nouvelle règle et donnez-lui un nom et une description.
6. Choisissez Event pattern dans rule type, puis Simple Storage Services (S3) et AWS API call via CloudTrail dans les deux champs suivants.
Sous le champ Detail, choisissez CreateBucket dans Operation.
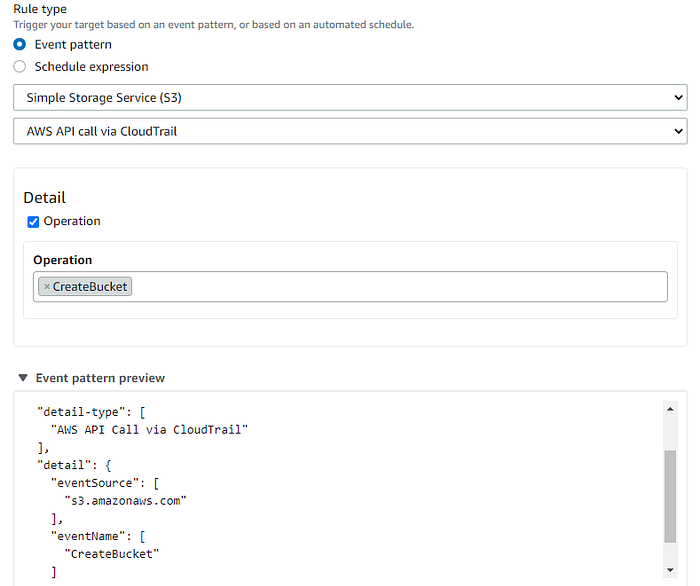
Faites défiler vers le bas et cliquez sur le bouton Add.
7. Descendez jusqu'à l'onglet Basic settings, sélectionnez Edit → IAM role et attachez la policy ci-dessous.
Cette policy autorise la fonction Lambda à créer une configuration de cycle de vie sur l'ensemble des buckets du compte AWS.
{
"Version": "2012-10-17",
"Statement": [\
{\
"Sid": "VisualEditor0",\
"Effect": "Allow",\
"Action": "s3:PutLifecycleConfiguration",\
"Resource": "*"\
}\
]
}
8. Créez un bucket pour vérifier que la fonction Lambda fonctionne correctement.
9. Et voilà ! Désormais, à chaque création d'un nouveau bucket (dans la région configurée), la fonction Lambda y appliquera automatiquement une lifecycle rule.
Merci de votre lecture ! Pour rester en contact, suivez-nous sur le DoiT Engineering Blog, le DoiT Linkedin Channel et le DoiT Twitter Channel. Pour découvrir nos opportunités de carrière, rendez-vous sur https://careers.doit-intl.com.