Dans cet article, je vais montrer comment configurer une bascule automatique d'un cluster EKS vers votre région de reprise après sinistre (DR). Voici une rapide présentation d'EKS et de Route 53.
Amazon Elastic Kubernetes Service (EKS) est un service entièrement géré qui permet d'exécuter Kubernetes sur AWS sans avoir à installer, exploiter ni maintenir son propre plan de contrôle Kubernetes ou ses worker nodes. Avec EKS, vous tirez parti de la puissance et de la flexibilité de Kubernetes pour déployer, gérer et faire évoluer vos applications conteneurisées sur plusieurs zones de disponibilité AWS. EKS s'intègre également à de nombreux services et fonctionnalités AWS — IAM, VPC, CloudWatch, CloudFormation et bien d'autres — pour offrir une plateforme Kubernetes sécurisée, fiable et évolutive.

Amazon Route 53 est un service DNS dans le cloud qui permet de connecter vos utilisateurs à vos applications web et à vos ressources, sur AWS comme sur Internet. Route 53 garantit haute disponibilité, évolutivité, performance et sécurité pour vos requêtes et réponses DNS. Il prend également en charge des fonctionnalités avancées telles que les health checks, la gestion du trafic, l'enregistrement de noms de domaine et DNSSEC. Route 53 s'articule avec d'autres services AWS, comme Elastic Load Balancing, CloudFront ou S3, pour acheminer vos utilisateurs vers le point de terminaison optimal pour votre application.
Dans cet article, je vais lancer deux clusters EKS : l'un dans US-EAST-1 (région de production) et l'autre dans US-WEST-2 (région DR). J'utilise un domaine personnalisé pour le cluster de production via Route 53. Je ferai ensuite tourner le jeu 2048 sur les deux clusters et illustrerai la bascule automatique offerte par Route 53 en provoquant des défaillances dans le cluster de production. Plusieurs méthodes existent pour lancer un cluster EKS — AWS Console, Terraform, CloudFormation, etc. — mais j'utiliserai la console AWS, par souci de simplicité et de clarté pour tous. Voici un schéma d'architecture conceptuelle.
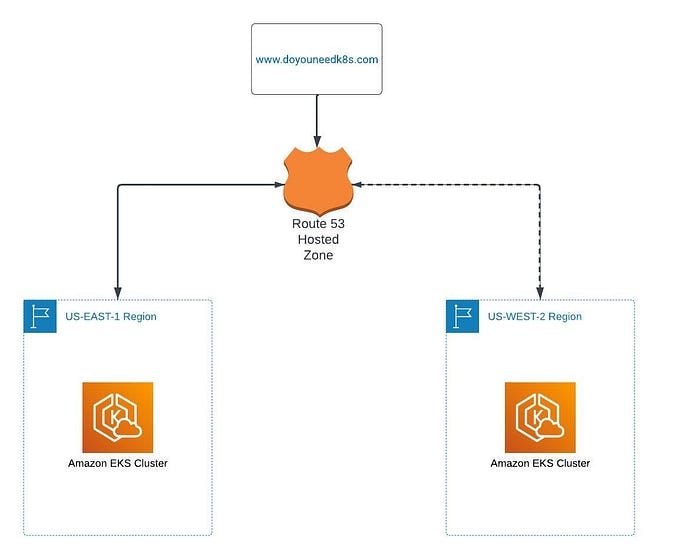
Architecture conceptuelle
**Étape 1 : créer un cluster EKS**
Je détaille ici les étapes pour lancer le jeu dans la région de production us-east-1 ; une configuration similaire est prête dans us-west-2.
Nom : eks-blog-production-us-east-1
Version de Kubernetes : 1.25
Cluster Service Role : créez un rôle eksClusterRole et veillez à y attacher les 3 politiques suivantes : AmazonEKSWorkerNodePolicy, AmazonEC2ContainerRegistryReadOnly et AmazonEKS_CNI_Policy.
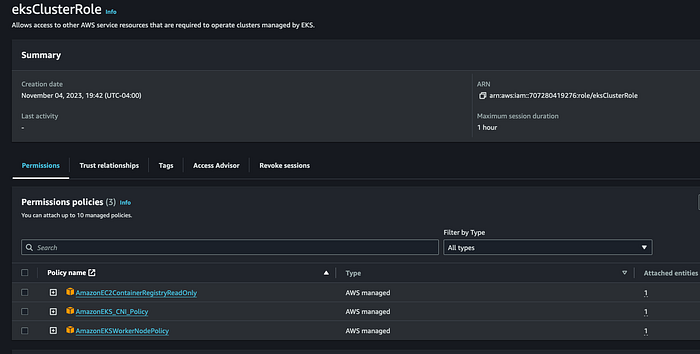
eksClusterRole
Sélectionnez le VPC par défaut, puis 2 ou 3 sous-réseaux.
Sélectionnez un groupe de sécurité ouvrant les ports 22, 80 et 8080.
Accès au point de terminaison du cluster : public
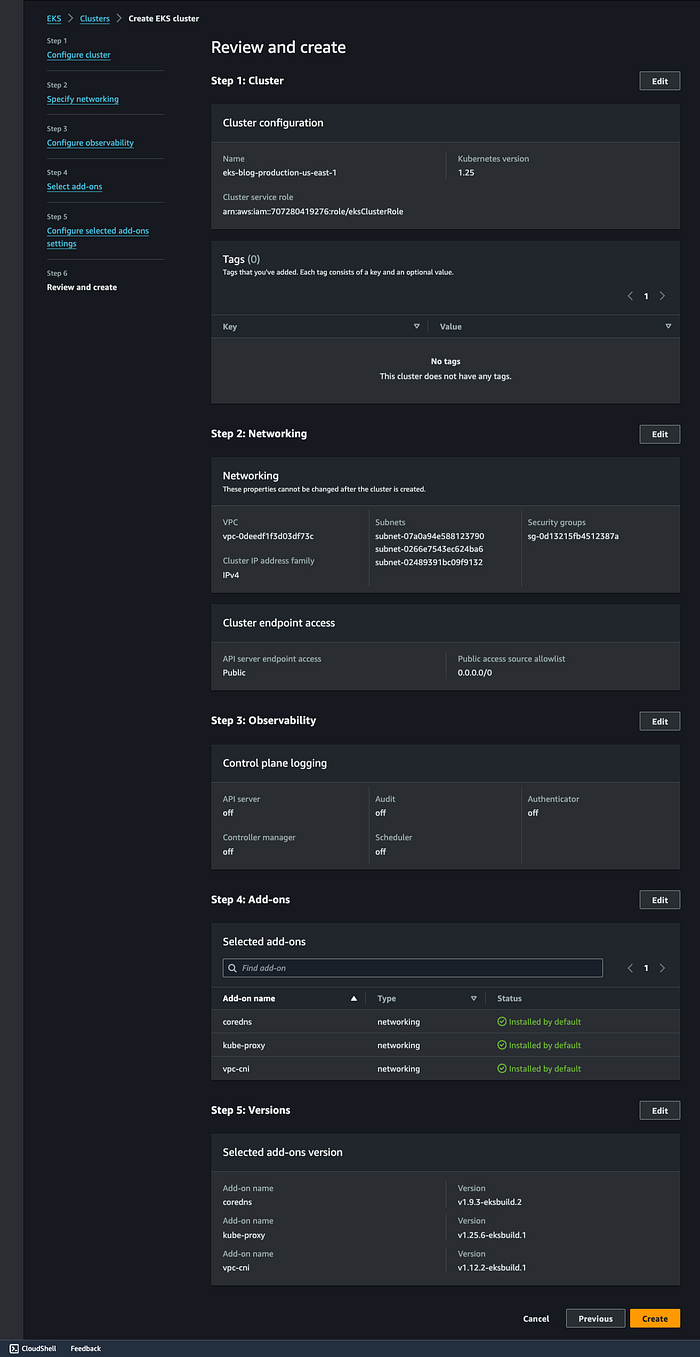
Détail complet du cluster avant lancement
Étape 2 : ajouter des Node Groups au cluster
Ouvrez le cluster > Compute > Add NodeGrp
Nom : eks-blog-production-eks-nodegrp-1
Cluster Service Role : créez un rôle eksNodeRole et veillez à y attacher les 3 politiques suivantes : AmazonEKSWorkerNodePolicy, AmazonEC2ContainerRegistryReadOnly et AmazonEKS_CNI_Policy.
Conservez les valeurs par défaut pour le reste.
EKS Node Group
Étape 3 : s'authentifier auprès du cluster
Ouvrez AWS CloudShell et exécutez les commandes ci-dessous.
# À taper dans votre fenêtre AWS CLI
aws sts get-caller-identity
# observez les détails de votre compte et de votre user id
# Créer un fichier kubeconfig qui stocke les identifiants pour EKS :
# La configuration kubeconfig vous permet de vous connecter à votre cluster avec la ligne de commande kubectl.
aws eks update-kubeconfig --region us-east-1 --name eks-blog-production-us-east-1
# vérifiez que vous obtenez bien les nœuds créés
kubectl get nodes
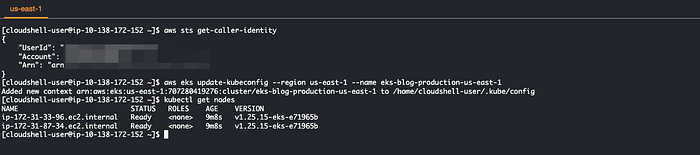
Sortie des commandes
Étape 4 : créer un nouveau POD dans EKS pour le jeu 2048
Créez le fichier 2048-pod.yaml ci-dessous pour déployer le pod du jeu 2048 dans le cluster.
### début du code ###
apiVersion: v1
kind: Pod
metadata:
name: 2048-pod
labels:
app: 2048-ws
spec:
containers:
- name: 2048-container
image: blackicebird/2048
ports:
- containerPort: 80
### fin du code ###
Appliquez le fichier YAML pour créer le pod.
# applique le fichier de configuration pour créer le pod
kubectl apply -f 2048-pod.yaml
#pod/2048-pod created
# affiche le pod nouvellement créé
kubectl get pods

Pod 2048 créé
Étape 5 : configurer le service Load Balancer
Nous allons maintenant mettre en place un service de load balancer en créant le fichier YAML mygame-svc.yaml ci-dessous.
### début du code ###
apiVersion: v1
kind: Service
metadata:
name: mygame-svc
spec:
selector:
app: 2048-ws
ports:
- protocol: TCP
port: 80
targetPort: 80
type: LoadBalancer
### fin du code ###
Appliquez le fichier de service Load Balancer.
# applique le fichier de configuration
kubectl apply -f mygame-svc.yaml
# affiche les détails du service modifié
kubectl describe svc mygame-svc
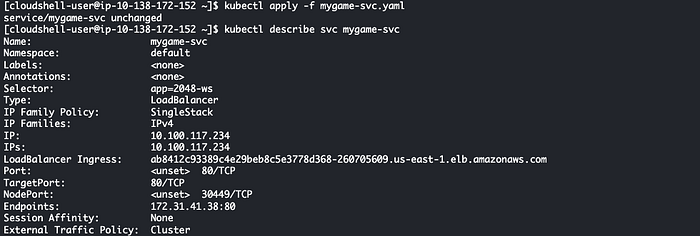
Service Load Balancer créé
Lorsque vous collez le point de terminaison du Load Balancer ab8412c93389c4e29beb8c5e3778d368–260705609.us-east-1.elb.amazonaws.com dans votre navigateur, le jeu se charge.

Étape 6 : router le domaine [www.doyouneedk8s.com](http://www.doyouneedk8s.com/) vers le jeu
Rendez-vous dans la zone hébergée Route 53 du domaine www.doyouneedk8s.com et ajoutez le point de terminaison du Load Balancer en tant qu'enregistrement CNAME. Une fois la propagation DNS effectuée, le jeu se charge lorsque vous saisissez le domaine dans votre navigateur.
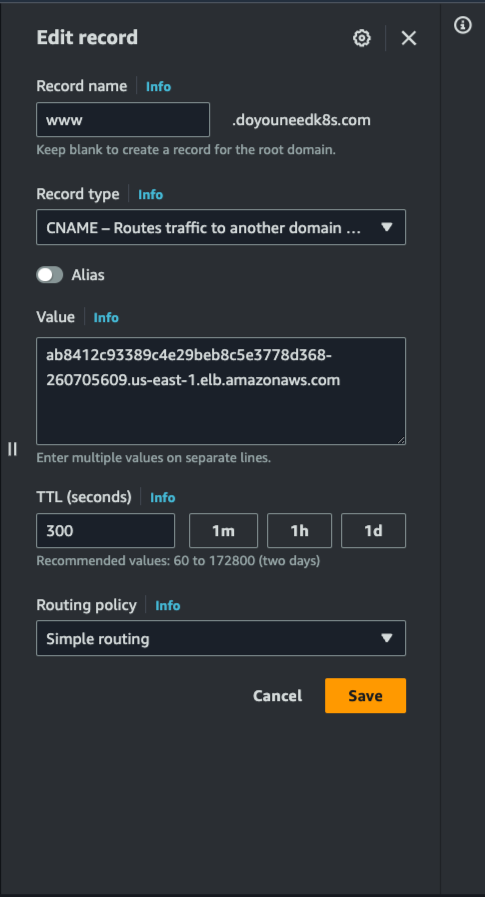
Enregistrement CNAME Route 53
Étape 7 : provoquer une défaillance
Imaginons à présent que la région US Virginia subisse une panne. Nous allons déclencher manuellement une défaillance pour l'application dans US-EAST-1 en supprimant la règle entrante sur le port 80 du groupe de sécurité du Load Balancer. Le jeu cesse alors de se charger, faute de bascule disponible pour l'application de production.
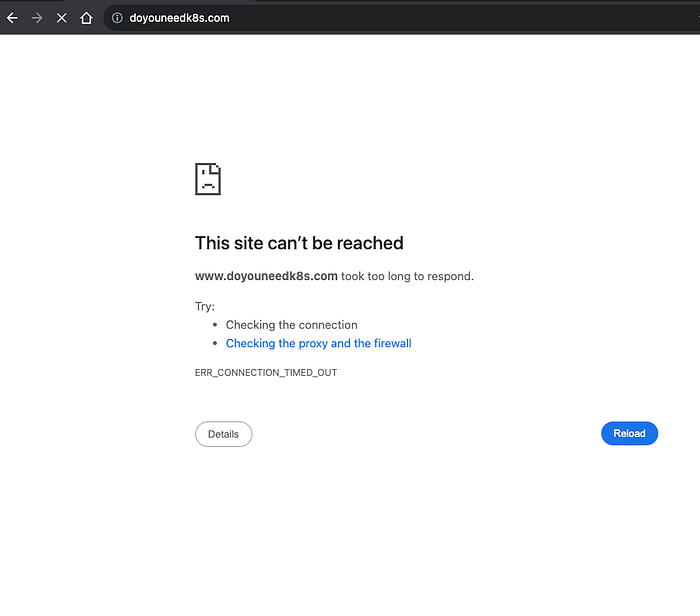
Étape 8 : configurer la bascule Route 53 vers la région DR
Première chose à faire : créer un Health Check pour votre application dans Route 53. Allez dans Route 53, sélectionnez Health Checks dans la navigation de gauche et cliquez sur le bouton Create Health Check.
Nom : www.doyouneedk8s.com
Élément à surveiller : Endpoint
Monitor and endpoint > sélectionnez Domain Name > renseignez www.doyouneedk8s.com dans le champ Domain Name, port 80.
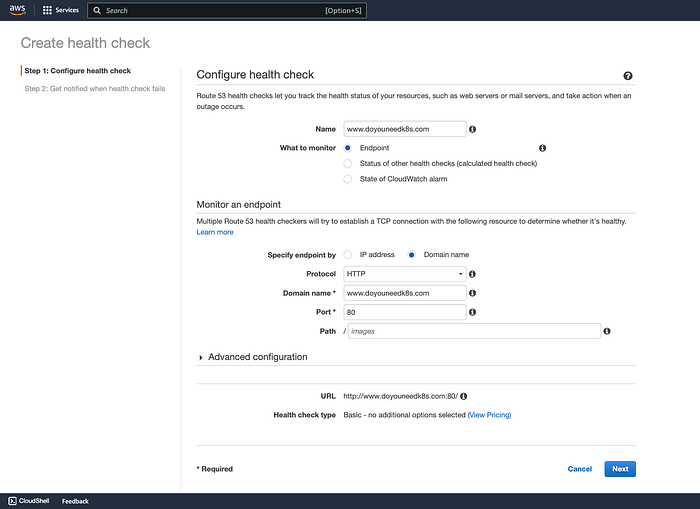
Création du Health Check — Page 1
Après avoir cliqué sur Next, la page suivante propose de créer une alarme pour cet événement, afin que vous soyez averti de la bascule. C'est très simple : il suffit d'un topic SNS vérifié — sélectionnez-le. Choisissez Yes pour Create Alarm, puis cliquez sur Create health check.
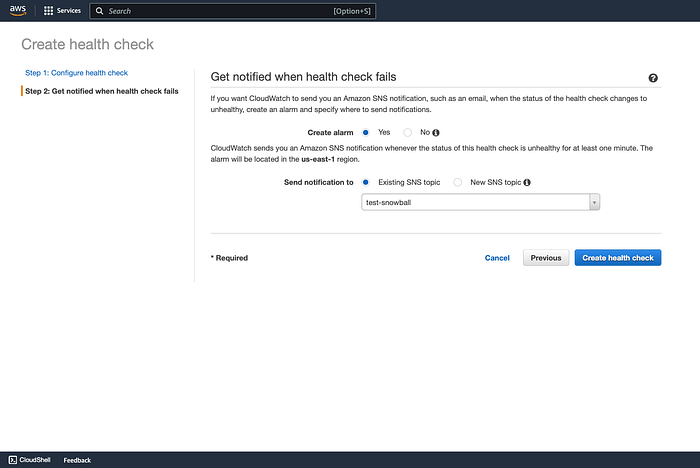
Création du Health Check
Une fois les paramètres définis satisfaits, le Health Check passe au vert avec le statut Healthy.
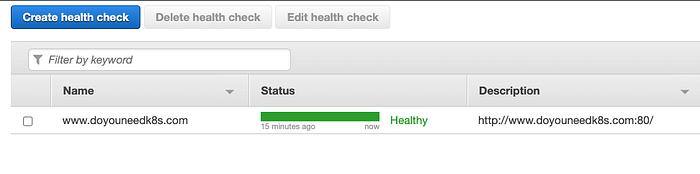
Health Check prêt à l'emploi
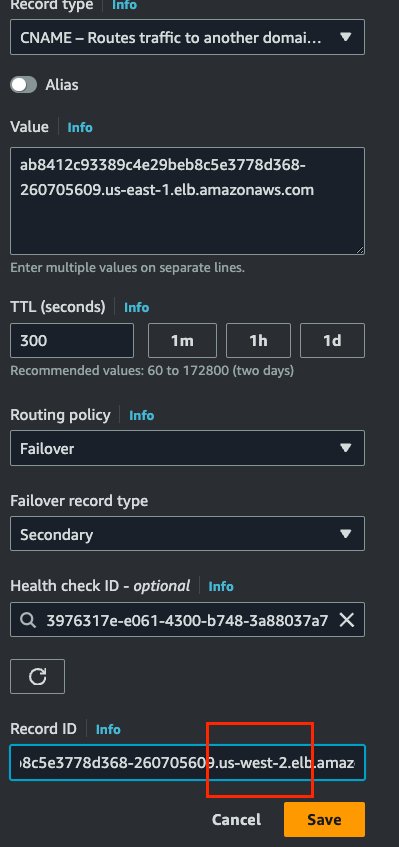
Rendez-vous dans la zone hébergée www.doyouneedk8s.com dans Route 53. Sélectionnez l'enregistrement CNAME et, sous Routing Policy, choisissez Failover.
Failover record type : Secondary
Health Check ID : le Health Check de domaine créé précédemment.
Record ID : le Load Balancer US-WEST-2 créé lors du lancement du jeu dans la région US Oregon. Enregistrez la configuration.
Place au test. Reproduisez la même défaillance qu'à l'étape 7 : cette fois-ci, le jeu continue de fonctionner. Pour le démontrer, j'ai ajouté un texte différent sur la page du jeu, qui prouve qu'il est désormais servi depuis la région DR.
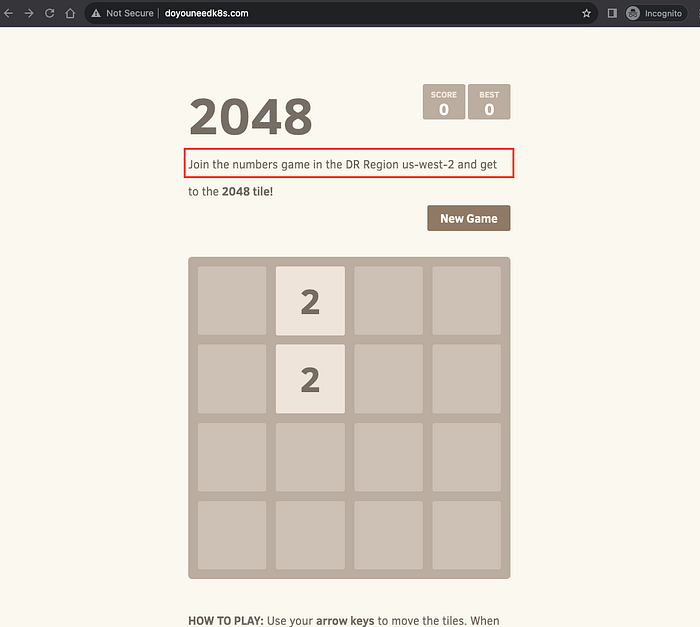
Bascule DR réussie
Conclusion
Route 53 est un outil particulièrement puissant proposé par AWS pour bâtir des stratégies robustes de DR et de continuité d'activité. Dans l'article ci-dessus, j'ai démontré comment réaliser la bascule, mais maintenir les clusters de production et de DR synchronisés au niveau du code reste à votre charge. Par ailleurs, si vous mettez en place cette stratégie de bascule, pensez à exécuter régulièrement des tests de bon fonctionnement durant les fenêtres de maintenance, afin de vérifier que les applications de production et de DR se comportent correctement.