**Model Context Protocol, ou MCP : de quoi s'agit-il et pourquoi s'y intéresser ?**
Nous sommes en 2025 et l'écosystème des Large Language Models (LLM) ne donne aucun signe d'essoufflement. Si l'attention s'est d'abord portée sur des modèles plus volumineux entraînés sur davantage de données, 2024 a vu monter l'intérêt pour les systèmes d'IA dits composés, où le LLM s'intègre à un ensemble plus vaste, modulaire et composable.
Plusieurs raisons expliquent ce basculement :
1. Composabilité : on cherche à dépasser la simple génération de texte pour automatiser des workflows aujourd'hui manuels. Vous ne voulez pas copier-coller la réponse de votre manager dans ChatGPT : vous voulez que le LLM soit intégré directement à votre client de messagerie. De même, en tant qu'administrateur de base de données, vous ne voulez pas ressaisir tout le schéma et les relations entre les tables de votre base relationnelle : vous voulez que votre LLM puisse récupérer ces informations à la demande.
2. Ancrage : un LLM (comme l'explique Andrej Karpathy ici) est, en gros, une compression probabiliste et avec perte de l'ensemble d'internet (et des autres corpus utilisés à l'entraînement). Il fonctionne donc avec un instantané figé du monde au moment de l'entraînement (ce que l'on appelle le knowledge cut-off). Et comme il prédit avant tout le prochain meilleur token, il peut inventer des éléments déconnectés de la réalité — phénomène parfois amusant, mais rarement souhaitable (on parle alors d'hallucinations). Une parade consiste à donner au modèle un accès en récupération à des informations plus récentes, qu'il pourra citer dans ses réponses.
3. Comportement agentique : dans des scénarios moins déterministes, on peut même vouloir céder une partie du contrôle sur le _quoi_ et le _comment_ d'une tâche. Le modèle doit pouvoir choisir ses outils, récupérer les informations utiles, prendre ses propres décisions et s'adapter en cours de route.
Le fil conducteur de ces évolutions, c'est la communication avec des systèmes externes. Sans standard commun, chaque nouveau système exigerait une implémentation spécifique, d'où un paysage fragmenté. En lançant Model Context Protocol fin 2024, Anthropic a voulu transformer ce problème d'intégration N × M en problème N + M, via un standard ouvert pour les connexions bidirectionnelles entre sources de données (N outils) et applications IA (M clients). Une démarche comparable à celle de HTTP, qui a standardisé les échanges entre navigateurs et serveurs web.
Pour ceux qui s'inquiètent pour leurs bases de code LangChain ou LlamaIndex, rassurez-vous : MCP n'est pas là pour les remplacer. Comme le souligne cette présentation, MCP permettra aux frameworks agentiques de se concentrer sur ce qu'ils font le mieux : exécuter la boucle agentique et exploiter les données remontées par les outils.
Désormais adopté par Amazon, OpenAI et Google, MCP est en passe de devenir le HTTP des applications natives à agents — autant s'y pencher de plus près !
Que faut-il pour créer son propre serveur MCP ?
Sur modelcontextprotocol.io, vous trouverez un guide développeur complet pour bâtir votre propre serveur. Inutile de reprendre toutes les étapes ici, mais il vaut la peine de présenter les concepts clés et les types de capacités qu'un serveur peut proposer :
- Ressources : tout type de données qu'un serveur MCP souhaite exposer à votre client, qu'il s'agisse de ressources textuelles (enregistrements de bases de données, code source, etc.) ou binaires (images, audio, vidéo, etc.). Le client peut les découvrir, les lire et les mettre à jour. Elles sont conçues pour être pilotées par l'application.
- Prompts : le serveur peut définir des modèles de prompts et des workflows réutilisables, qui standardisent les interactions courantes avec les LLM. En y intégrant une partie de votre expertise métier, les prompts orientent l'utilisateur vers le bon usage des fonctionnalités proposées par votre serveur MCP. Ils sont donc conçus pour être pilotés par l'utilisateur.
- Outils : via les outils, le serveur met à disposition du client des fonctionnalités exécutables, qui lui permettent d'interagir avec des systèmes externes et d'agir dans le monde réel — intégrations d'API, traitement de données, etc. Puisque l'on souhaite confier au LLM la décision de l'action à mener, les outils sont conçus pour être pilotés par le modèle.
**Le serveur MCP de DoiT, désormais accessible à tous**
Fidèles à l'esprit DoiT, nous voulions rejoindre cette communauté florissante de serveurs en publiant notre propre serveur MCP, pour aller à la rencontre de nos clients là où ils se trouvent déjà.
Le voici :
doitintl/doit-mcp-server : le serveur MCP officiel de DoiT \ DoiT official MCP Server.\ github.com
Il vous suffit de récupérer votre clé API DoiT et de commencer à l'explorer !
En configurant notre serveur, vous accédez directement à vos données FinOps multicloud hébergées dans DoiT Cloud Intelligence™ et pouvez dialoguer avec elles. Le serveur permet aujourd'hui d'interagir avec les incidents, les anomalies, les rapports, les requêtes et les dimensions de l'API DoiT. Gardez un œil sur le repository : d'autres mises à jour arrivent !
Comment en tirer le meilleur parti ?
Imaginez un lundi matin classique : vous voulez prendre rapidement le pouls de votre infrastructure cloud après le week-end. Plutôt que d'éplucher les dashboards et les e-mails d'alerte, vous demandez à votre assistant favori :
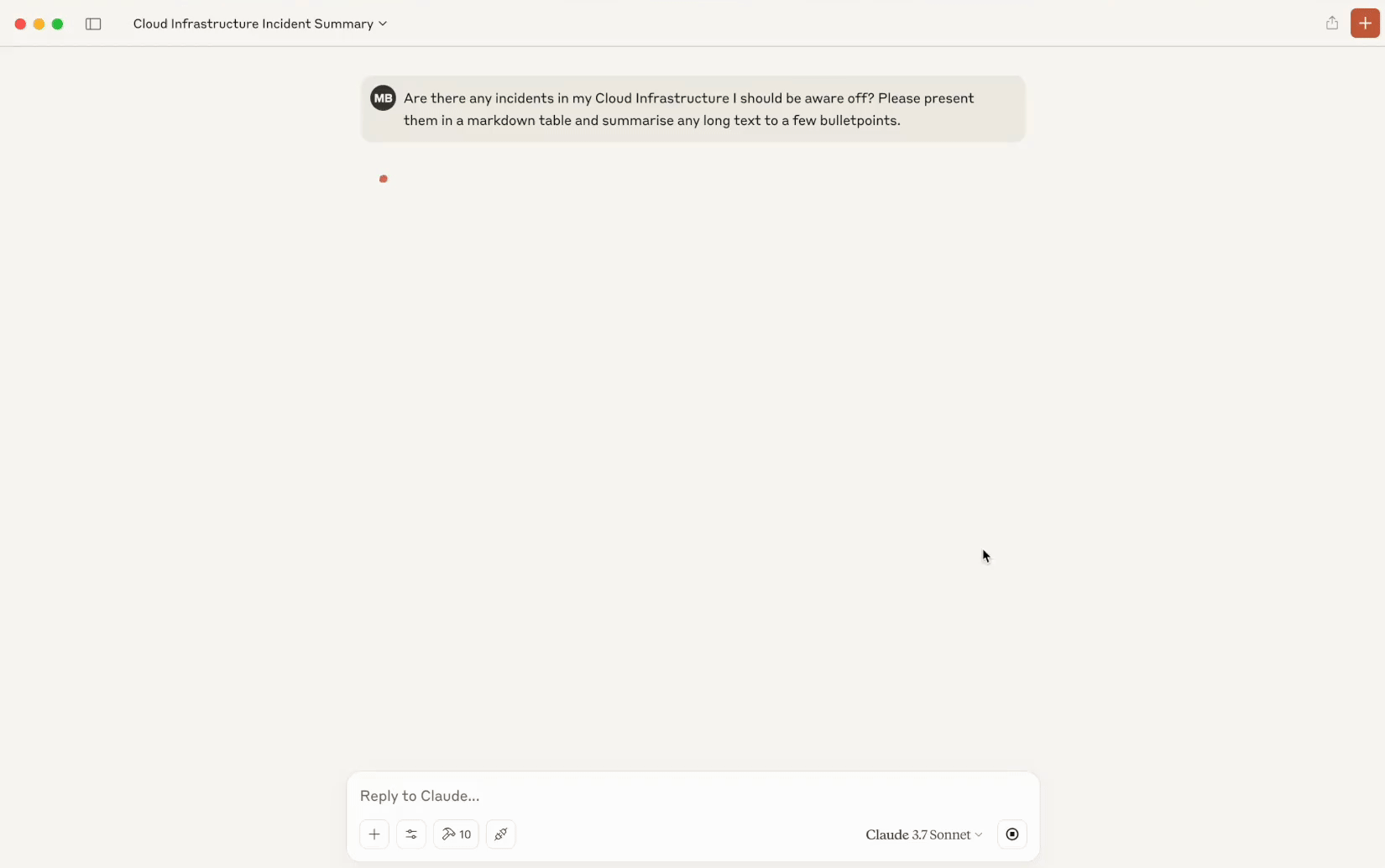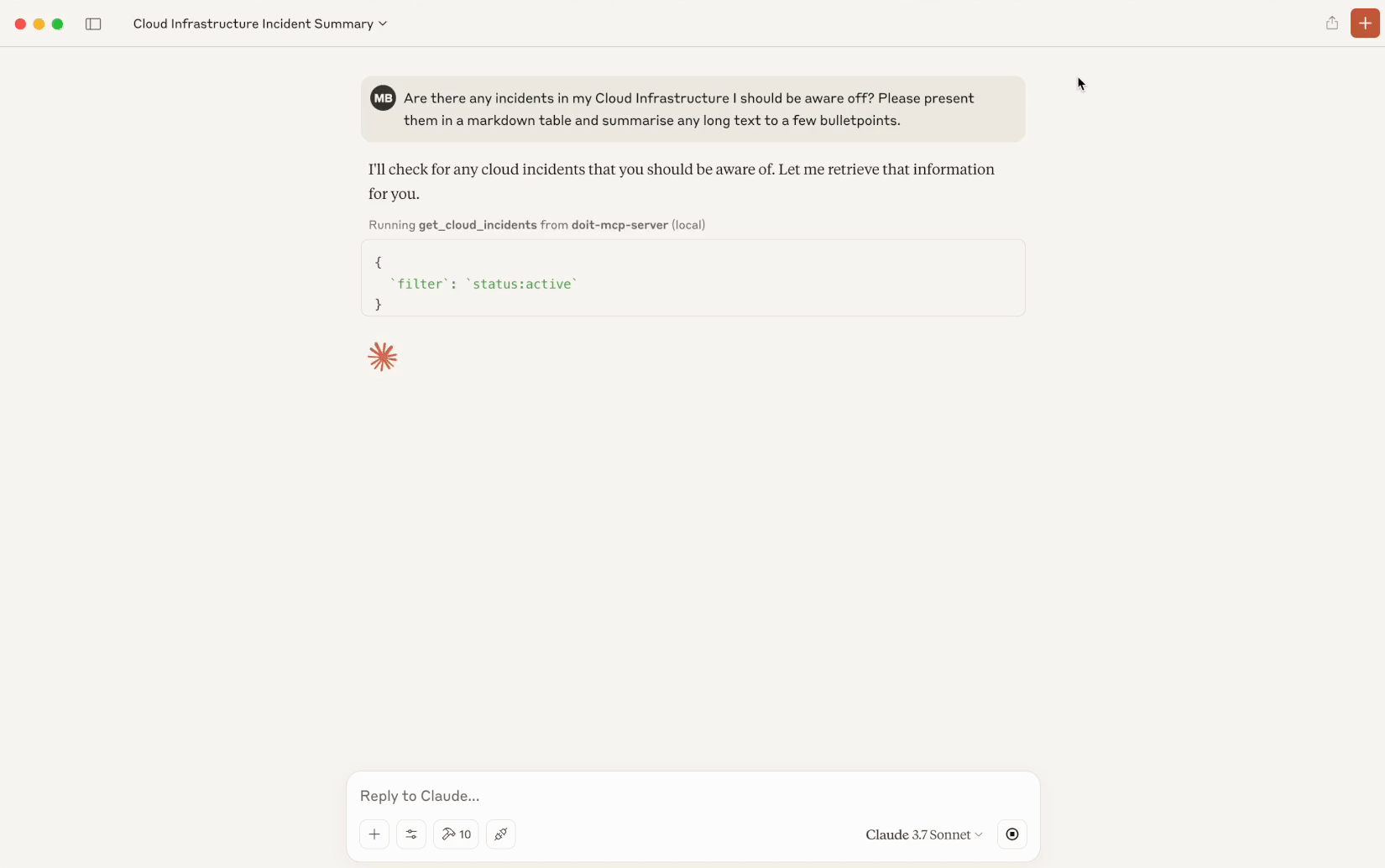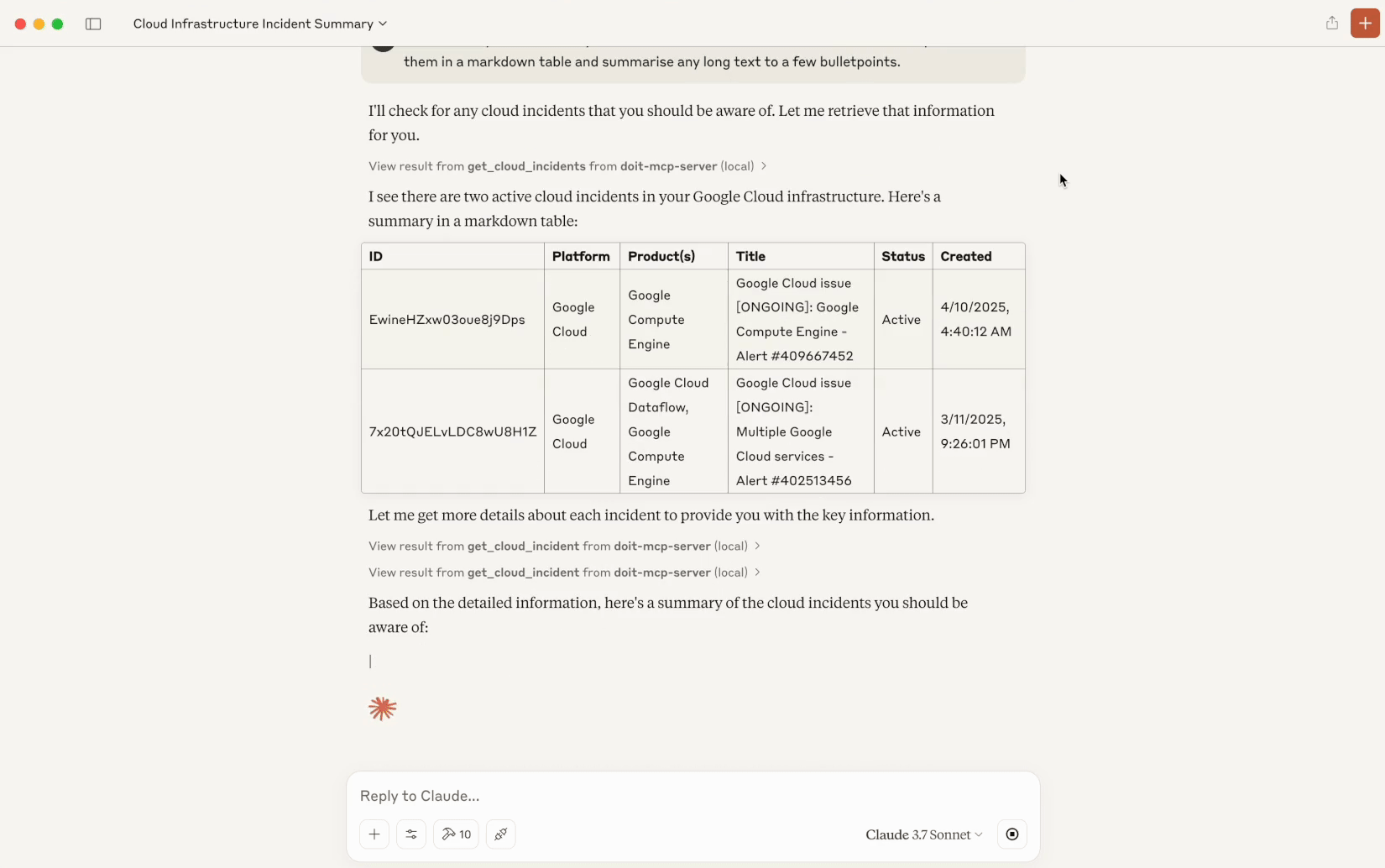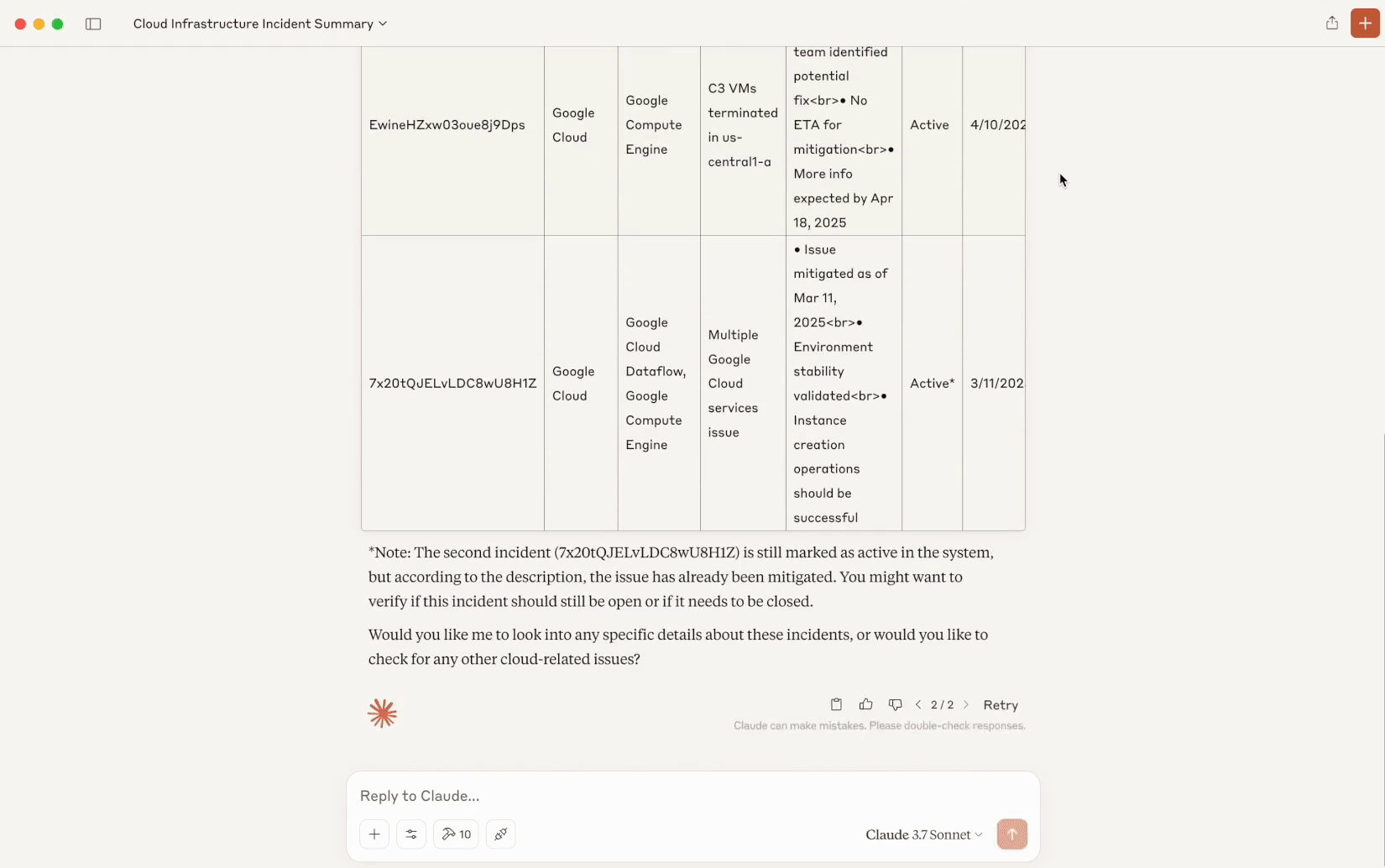
Y a-t-il des incidents dans mon infrastructure cloud dont je devrais être informé ? Présente-les dans un tableau markdown et résume les textes longs en quelques puces.
Ou vous voulez voir où est passé votre budget la semaine dernière, et repérer d'éventuelles tendances :
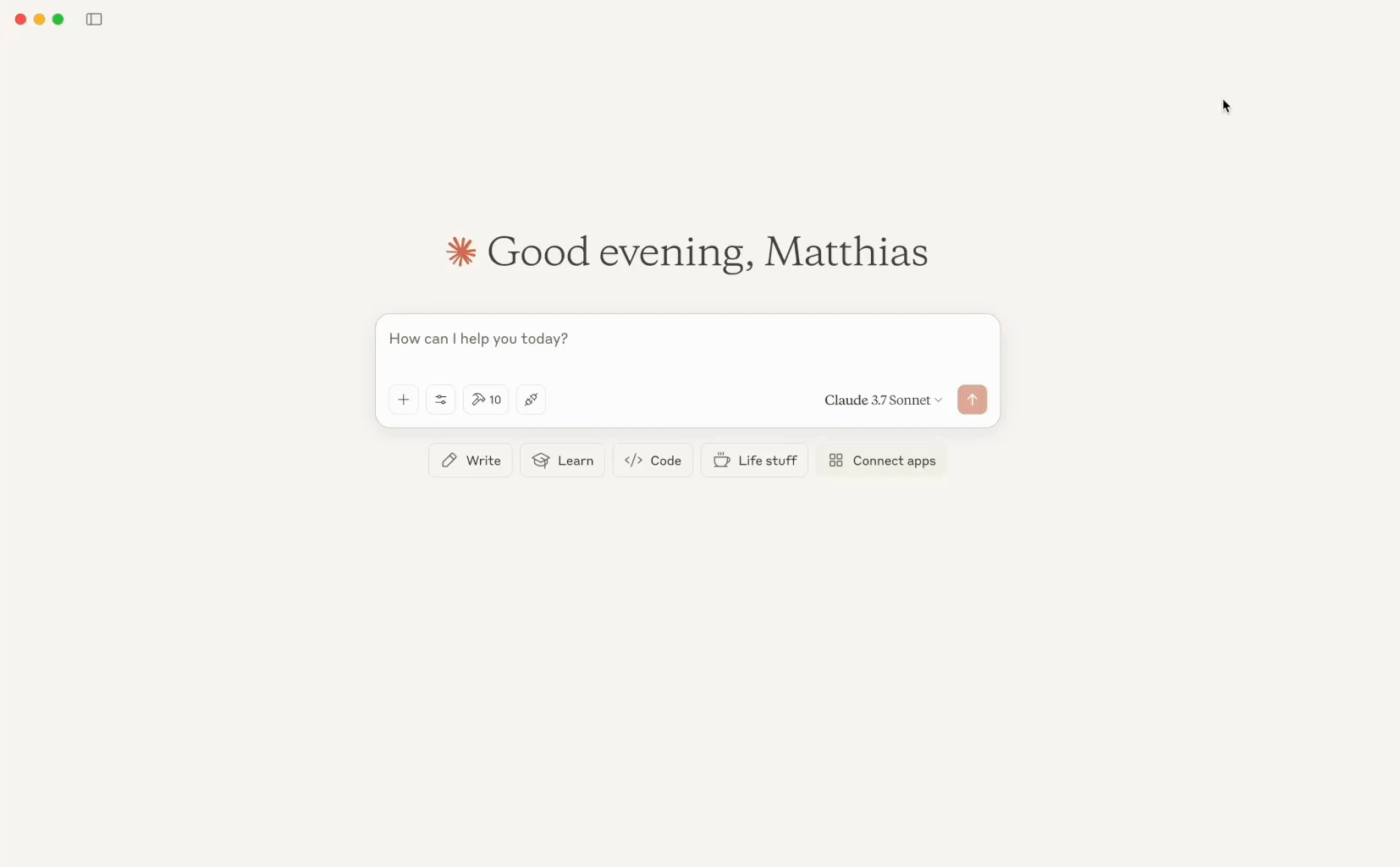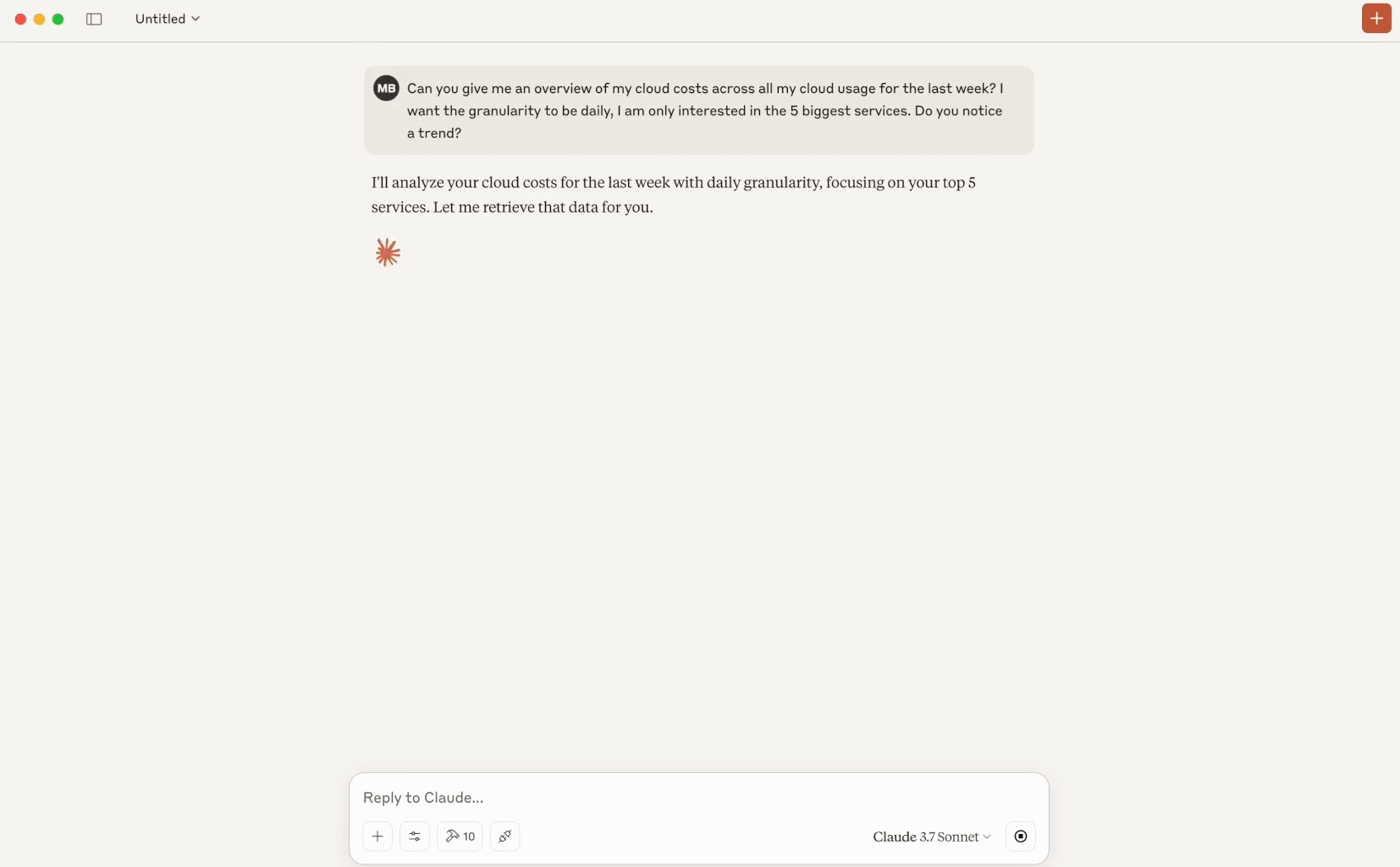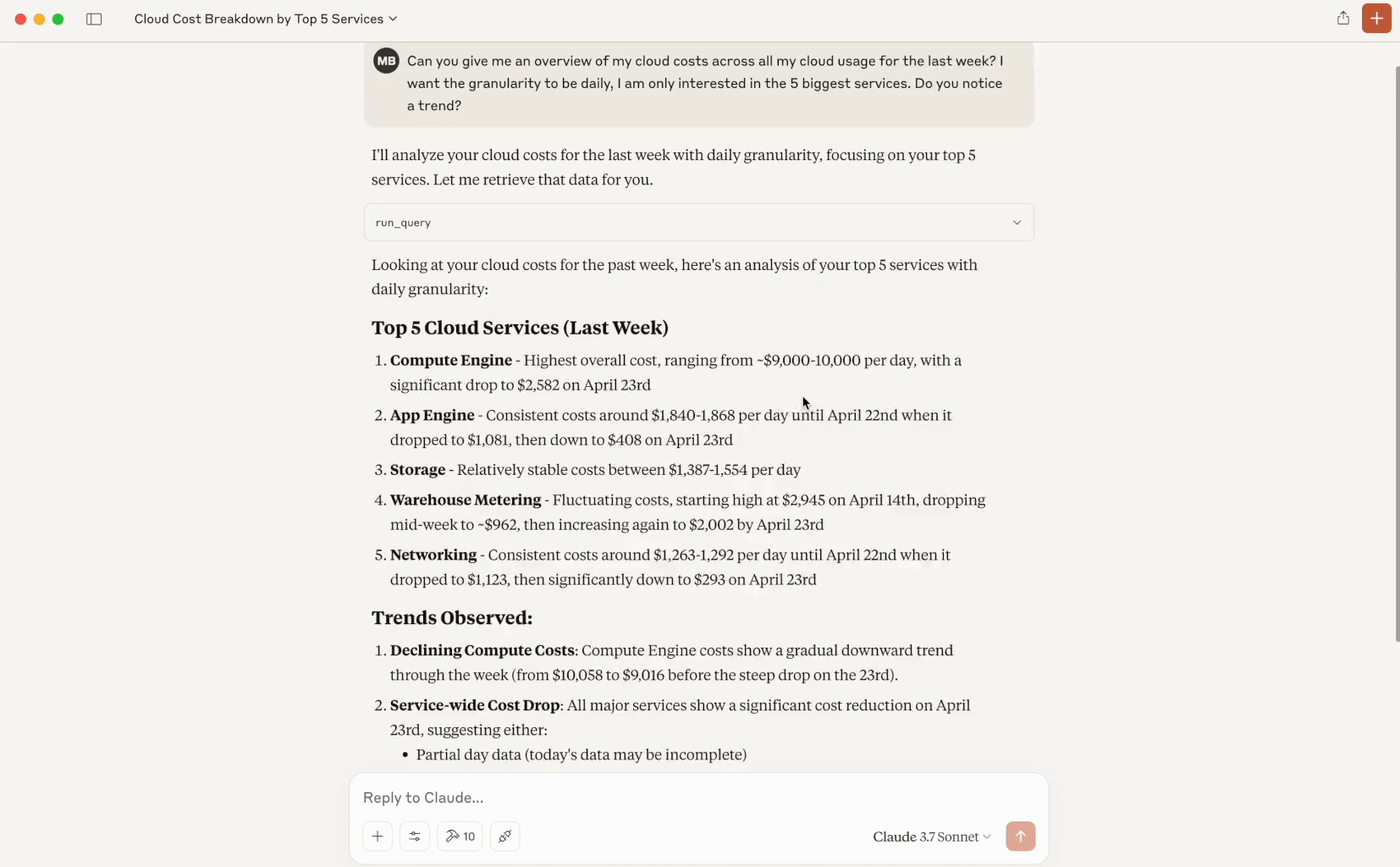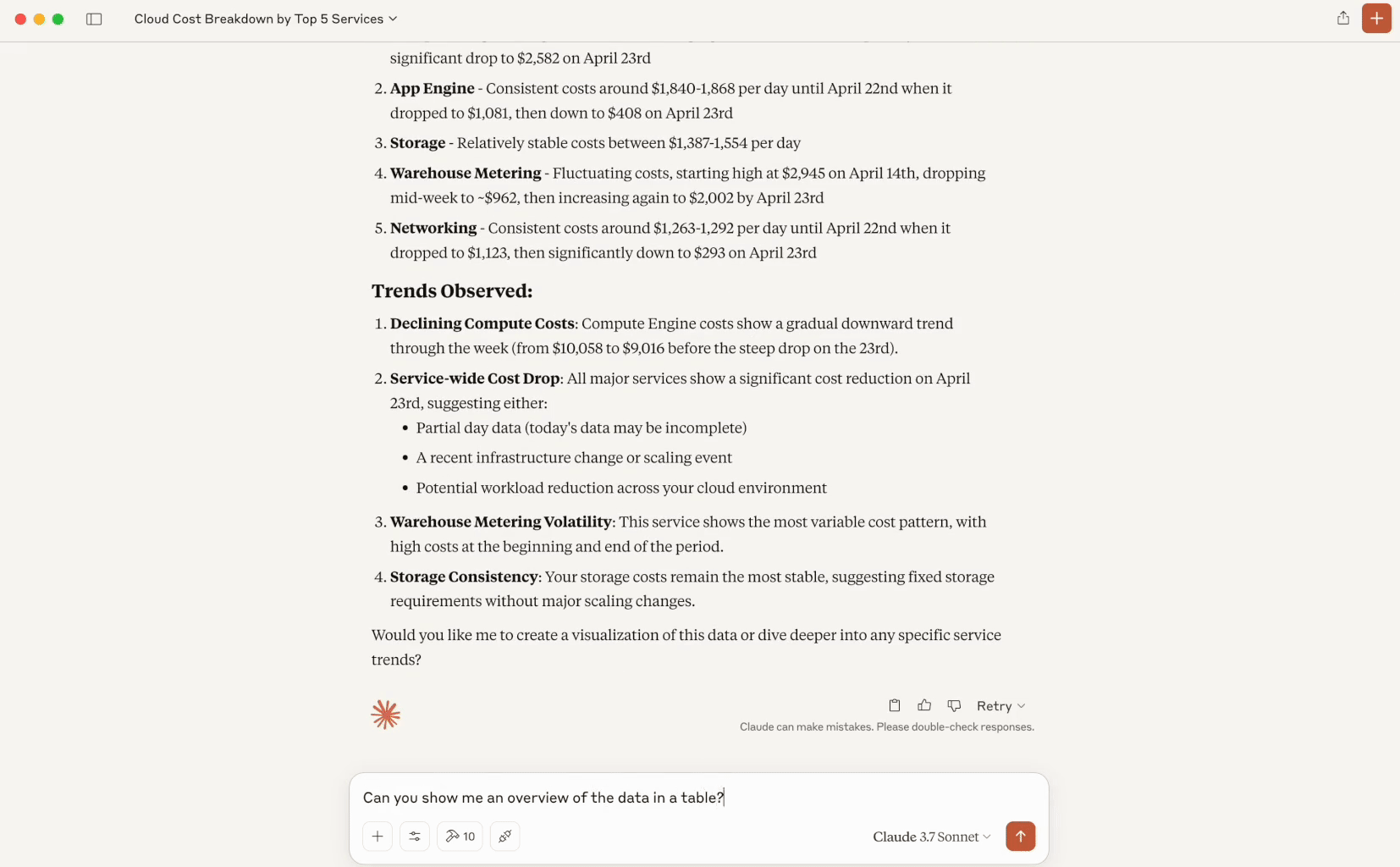
Peux-tu me donner un aperçu de mes coûts cloud sur l'ensemble de mon usage pour la semaine écoulée ? Je veux une granularité quotidienne et seulement les 5 plus gros services. Tu remarques une tendance ?
Et si vous voulez voir les données concrètes sur lesquelles Claude a fondé son analyse, il suffit de les demander :
Peux-tu m'afficher un aperçu des données dans un tableau ?

Avec MCP, votre assistant — Claude par exemple — sait précisément quels endpoints DoiT appeler : il construit la requête et l'exécute. Dès qu'il reçoit les bonnes informations, il vous les présente ou les analyse selon votre demande.
—
Aidez-nous à simplifier votre parcours FinOps : partagez vos retours sur le repository ou échangez avec nous via doit.com/services !