In Part 1, we described the challenges of slow, costly optimization processes and the new Black Box workflow implemented by Vertex AI Vizier. In Part 2, we explained why Black Box allows more control and scalability than ordinary hyperparameter tuner services. In this closing article, we’ll talk about ways to configure Vizier to accelerate your convergence to the best possible model.
Plain Vanilla vs Configurability
Your conversation with Vizier looks like this: The input is the parameters plus the metric from a trial that you ran; the output is suggested parameters for the next trial. But Vizier offers more flexibility where needed. Still, I suggest caution when fiddling with these advanced configuration options. Vizier is doing nested optimization: The trials themselves are optimizations, and Vizier is intended to converge on the best answer across these repetitions, each of which is expensive. If you then do another layer of nesting and run multiple Vizier studies on the same problem, each time tweaking Vizier’s optional configuration and running again, the cost of these optimizations is likely to exceed the benefits.
Search Algorithm
You can choose Vizier’s own search algorithm as it wanders the parameter space, trying to find you the best set of parameters. The first is grid search, which steps regularly through the parameter space, trying as many options as possible given the limited number of iterations. Next is random search: Just jumping around in parameter space, which can work surprisingly well. These two algorithms seem quite basic, and you could do these without Vizier, either carefully stepping through the range of hyperparameters, or just trying different combinations at random, the results would be no different. But when you use Vizier, it keeps track of and manages this process. Vizier is free with grid or random search.
More sophisticated is Bayesian search, in which Vizier creates its own internal model to optimize for the best suggestions. (See the research paper for details.) In contrast to jumping around randomly or in predetermined steps, this approach can be expected to converge far more quickly.
Bayesian search is the default, and the only one you are charged for: It costs a dollar a trial after the first 100 trials per month, which are free. Since Vizier is built to minimize the repetition of expensive optimization processes, that price is trivial in contrast to, for example, a single iteration of ML training which might cost $20, or an A/B test which could cost thousands in potential lost revenue. And by providing a hyperoptimization service rather than a library for self-deployment, Vizier saves you the time and expense of setting up the architecture.
Stopping
As mentioned, Vizier can advise you on when to stop. In the graph below, the dotted green curve first improves, and then eventually starts getting worse, so it’s a good idea to stop, and Vizier can detect that. The dotted orange curve, on the other hand, is getting rapidly better, and it’s worthwhile to continue; while the solid curves are in between. You can configure the algorithm that Vizier uses for this: You can ask it to recommend a stop to the study when the latest iteration is no better than the median of all previous iterations, or no better than the last few.
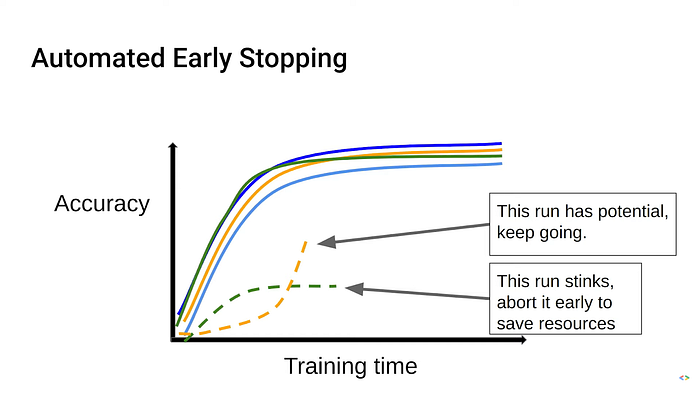
Figure 1. Suggestions for stopping (Based on the research paper. )
Choosing the Optimal Parameter-Set
After the study is over, Vizier tells you which parameter set was the best, and you can tell Vizier how to make this selection. It may seem obvious to choose the trial that produced the best metrics, and that is the default. But if you have a process with a lot of noise (see image below), the peak may just be the result of randomness, a momentary spike, sometimes called the Winner’s Curse. If you know that you have that kind of noise, yet the trend is generally upward, you can tell Vizier to just choose the last one.
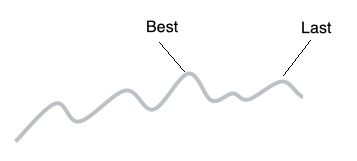
Figure 2. Winner’s Curse: Why you might not want to take the best
Transfer Learning
Vizier can incrementally use the learning that it has gained, creating a new study that builds on a similar earlier study. Say you’ve optimized your website with A/B testing, advised by Vizier, but a few weeks later, a new version with significant new features comes out, and you want to tweak those as well. With resumePreviousJobId, you transfer the learning from another study. This can lead to large savings in time and money as you reuse existing modeling efforts and run far fewer of those slow, expensive trials that Vizier is advising you on.
Today, this feature is only supported in the internal version of Vizier that powers the AI Platform’s hyperparameter tuner, and not in either of the Vizier-branded APIs.
The APIs
Vizier offers several APIs.
The Vertex AI Vizier API (sometimes called “GAPIC” from the Protocol Buffer client-generator used) is centered on a Python class VizierServiceClient. This is a Generally Available product and the future preferred direction for Google. So, it is the main API to focus on.
Vizier is also exposed as another API, backported to the older GCP AI Platform and now in beta. The API is discovery-based, where you don’t see any functions implemented in the library; instead, you call functions defined through a dynamic wrapper layer. This is not as difficult as it sounds: documentation, experimentation, and sample code (including mine, below) make it usable.
The other implementation of Vizier, as mentioned, is the open-source project, if you want to manage it yourself or just read the code.
Code Walkthrough
There are only a few code samples out there. Indeed, the official Vizier documentation offers only one ML notebook for the backported AI Platform Vizier API, and none for the preferred Vertex AI Vizier API. So, I prepared this notebook. It is built around a normal ML training process run internally in the container (though, as we know, Vizier is independent of how that training is run). You can walk through it with code comments numbered #[0], #[1], etc.
In addition, Ryan Holbrook created this open-source notebook. You may want to use this variant that I created, which presents the output of a successful run, and which is slightly tweaked to make it easier to run end-to-end without further configuration.
You may have used a hyperparameter tuner service for your ML: Vizier is that and more. Because Vizier knows nothing about the ML, or even that you are doing ML, you can use it for any slow, costly optimization process. As a service, it is robust and scalable, and almost free in comparison to the expensive processes that it aims to minimize. It gives you the freedom to take its advice or not, in either case suggesting the path towards the fastest convergence to an optimal answer.