You have an optimization process where each trial is costly in time or money. It might be Machine Learning (ML) training, where every run takes hours and tens of dollars, or A/B testing where each iteration could take a day and potentially thousands of dollars of lost revenue. Or it might be supply chain management for a factory, where choosing the day’s inputs for the lowest cost and greatest output is a gamble: A wrong guess can cost a day and a lot of money.
If a trial doesn’t come out good enough, you try again. But you don’t want to guess at parameters, when each trial is costly; you want to converge on the best feasible parameters in as few trials as possible.
This series of three blogs will explain a new approach to reducing cost for ML training and other optimization processes: the Black Box optimization workflow with Google Vertex AI Vizier.
It’s essential to remember that Vizier is not just for Machine Learning. It does not even know you are doing ML; it doesn’t get involved in the trials themselves. Vizier only knows what you tell it: The parameters and the objective measurement (how well the trials came out). You are the expert, and you run the ML training or other process under optimization, while Vizier is an advisor that sits on the outside and gives you suggestions for the next round.
For ML training, you can use Vertex AI Vizier to help choose the best possible hyperparameters — those that configure the training run as a whole — such as regularization, learning rates, or the number or size of layers. Moreover, the type of model to be used in the next training run is itself a parameter to be explored: For example, whether a binary classification problem should be solved with Naive Bayes, Logistic Regression, or XGBoost.
Because Vertex AI Vizier is just advising on training from the outside, you can use it with any kind of ML. You could be using Google Vertex SDK to launch custom training jobs, or you could be training your own TensorFlow or PyTorch model inside a custom container.
How to use Vizier
You may be familiar with hyperparameter tuner libraries like those of Scikit and Hyperopt. These run repeated ML trials, tweaking the hyperparameters each time, trying to converge to the best result.
However, a hyperparameter tuner service like those of Google and AWS radically simplify the process as they eliminate the need to set up the libraries and the compute infrastructure.
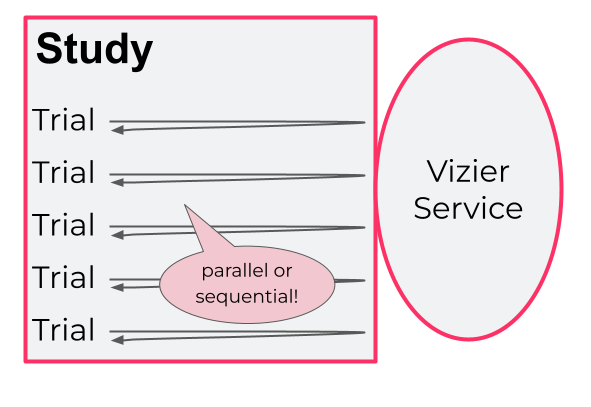
Vertex AI Vizier takes this one step further with the Black Box process that I will describe in this series. The basic difference is the usage pattern: With Vizier you run interactive trials, in which you ask Vertex AI Vizier for advice on each round, and it sends back suggestions, based only on how good the results were on previous trials.
The process
These are the high-level steps for implementing the workflow with Vertex AI Vizier: :
- First, create a Vertex AI Vizier study, in which there will be a number of trials. The study is defined with a study configuration, which states the goals (the measurements/metrics) and input values (hyperparameters) of your experiments, called trials.
- Run a trial: training a Machine Learning model or running another process you need to optimize.
- Invoke Vertex AI Vizier, by sending the parameters along with the optimization measurement from that trial. In the case of training an ML Model, that metric might be, or example, cross-entropy loss or balanced accuracy on your validation data, after the usual train/validation/test split.
- The response to that request is suggestions for the next trial. This includes one or more sets of parameters, which you can use in defining an upcoming a trial.
- Run the next trial, typically based on the suggested parameters. But they are just suggestions, and you can use your own choice of parameters. Either way, Vertex AI Vizier will keep learning.
- Keep going with the next trial.
- Stop iterating after you have done enough trials (details on that to follow).
Flow chart of interaction with Vizier
Vertex AI Vizier is software-as-a-service. You just call a REST service through a convenient Python API, which I will discuss later.
What an API Call Looks Like
Here is an example of the input and output. It’s a bit simplified, but it presents the essence of the REST invocation. (In practice, you would use a Python client, which we discuss later.)
Input:
{
"Params": {"flour": 0.21, "recipe": "Pam's chocolate chip", "eggs": 2 },
"rating": 8.1
}
Output:
{"flour": 0.32, "recipe": "Chocoflake", "eggs": 1}
This JSON is an example of a cookie-recipe optimization, which was actually carried out by the research team: Cookie baking is so expensive and time-consuming that you don’t want to do it hundreds of times!
The parameters include the amounts per ingredient: We have a float and an integer parameter. Another parameter is the choice of recipe, which is a categorical parameter (one that has a few options, with no ordering between them).
The input also includes the success measurement, which is the taste-testers’ rating of the cookies.
The output, the response from the REST call, is a suggestion (in practice, potentially multiple suggestions) for the parameters to use on the next round of baking.
Running the trials in a study
You can do the trials iteratively, but you can also run multiple trials in parallel. You ask Vertex AI Vizier for multiple suggestions, say five, and then simultaneously run five trials. Parallelism has a trade-off: On the one hand, it speeds things up, but on the other hand, there’s an advantage to doing trials iteratively, because then Vizier can improve its recommendations for each trial based on all previous ones.
The number of trials can be predetermined, say twenty: The recommendation is ten times the number of parameters. Alternatively, Vizier can suggest when it is time to stop, based on whether results are converging. This frugality in the number of trials is important, since each is costly.
Where we go from here
Recently, in February 2023, Vizier became available in an open-source variant. I recommend that you explore the implementation. However, the open-source does not contain the core Bayesian optimization algorithm, and the Vertex AI Vizier service provides ease of use, scalability, and robustness. In the blog post series, we will focus only on Vertex AI Vizier.
In this first blog post, we provided a summary of how to use Vertex AI Vizier. The second blog post will explain the advantages of this “Black Box” approach: By leaving responsibility for the heavyweight optimization processes with you, you do what you do best, such as structuring your ML training, or other costly processes. Meanwhile, Vertex AI Vizier does what it does best: Guiding you to get the best outcome in the smallest number of trials.