









DoiT International customers often ask a simple question that is worth addressing in detail in this blog, as to answer it fully requires several complex considerations to be addressed with sufficient details:
Which services should I use for GCP / AWS data warehousing and analytics?

Answering this means going beyond service feature comparisons. It challenges us to scrutinize the nuanced pricing models of the DWH systems and the many cloud services they depend on.
While a feature comparison between offerings can be straightforward, pricing is considerably more difficult to compare for two main reasons:
- There are multiple cloud services that DWHs depend on to prepare and load data into the DWH. Each of these services comes with a typically non-trivial cost in addition to the DWH cost.
- An evaluation of DWH cost by itself requires both the scale of data being stored in the DWH and the methods and frequency in which that data will be queried to be considered. Different types of queries and execution frequencies incur significantly different costs depending on the DWH being used and the pricing model selected.
To better address this common question for cloud customers seeking to operate cost efficiently at scale, a detailed comparison of the end-to-end costs of GCP and AWS data warehousing options is provided below. This means we will examine the cost of:
- Retrieving large, multi-TB datasets used in real genomics applications
- Data transformations that facilitate loading data into a data warehouse
- The cost of executing 17 complex queries that yield useful results
(versus, say, running simple and arbitrary benchmark queries)
While the overall cost of data warehousing operations is the main focus of this article, I will also make functional comparisons to round out the discussion and provide a holistic guide to data warehouse selection.
Should you wish to reproduce any of the cost calculations discussed, please refer to the Git repo for this article which will make a reproduction of my benchmarks as easy and automated as possible.
Additionally, should you have any questions on how costs were calculated as you read the article, please see the Appendix for further details.
With all that said, let’s jump into it!
Rather than bury the lede, I’d like to highlight my benchmark-derived recommendations for data warehousing selection upfront.
If you are focusing solely on cost efficiency without regard for value-added functionality, I would recommend the following services in order of likelihood of being the least expensive to the most expensive:
- AWS Athena with AWS Glue Data Catalog (cheapest)
- AWS EMR with AWS Glue Data Catalog
- GCP BigQuery
- GCP Dataproc with GCP Dataproc Metastore
- AWS Redshift (most expensive)
If you care more about value-added functionality, I recommend products based on the following ordering, which weighs functionality against cost:
- GCP BigQuery (brings the most value of any DWH option)
- AWS Athena with AWS Glue Data Catalog
- AWS EMR with AWS Glue Data Catalog
- GCP Dataproc with GCP Dataproc Metastore
- AWS Redshift (brings the least value of any DWH option)
Read on to better understand the reasoning behind my recommendations.
Part 1: Data acquisition and transformation
I will stay out of the weeds of genomics terminology to keep this accessible. However, for readers interested in scalable scientific workloads, the Git repo for this blog presents detailed, reproducible examples for cost-efficiently implementing genomics workloads.
I will be working specifically with the following two datasets, which, for a non-genomics audience, can be summarized as follows:
- gnomAD genomes v4.0: gnomAD is commonly used in genomics research, as it contains population frequency data on mutations discovered across 807,162 individuals’ worth of whole genome sequencing data. Among other uses, population frequencies can be used to find rare mutations that, on account of being rare, are more likely to be of clinical significance.
- For example: A mutation with a 25% population frequency is present in 25% of the overall human population. A common mutation like that is much less likely to have a clinical impact on an individual than, say, a rare mutation (that is rare due to evolutionary pressure against it) appearing in only 0.01% of the human population.
- In flat file format, gnomAD v4.0, when bgzipped, is ~830 GBs in size.
- dbNSFP v4.6: Another large dataset used in human genome research. dbNSFP gathers - into a single file - dozens of functional impact predictions and annotations for all mutations in the human genome by unifying data across several dozen databases. The breadth and depth of data in dbNSFP helps clinicians assess mutations' clinical impact.
- In flat file format, dbNSFP uncompressed is ~250 GBs in size.
Both gnomAD and dbNSFP are crucial resources in precision medicine.
gnomAD is hosted in both S3 and GCS buckets, and dbNSFP is hosted on S3, so retrieving these datasets within cloud accounts is straightforward. However, both datasets are stored in flat file formats designed for researchers exploring them with poorly scalable, academia-focused bioinformatics tooling. gnomAD, in particular, is stored in a specialized bioinformatics flat-file format (bgzipped VCF) that is neither ideal for large-scale analytics nor a standard format accepted into DWHs.
Thus, step one of our journey in exploring DWH costs requires us first to retrieve gnomAD and dbNSFP, then transform their enormous flat files into a data warehouse-friendly format: Parquet.
One of the most cost-effective tools for manipulating large flat files is Apache Spark. In fact, Spark is one of the most cost-effective tools for analytics on any large dataset, particularly when working with Parquet files as inputs. Spark is not only frequently a key component in data pipelining at scale, it can even be used as a DWH when used to run analytics on Parquet files stored in a bucket.
With that in mind, let’s first review the cost of executing a Spark-based data preparation step.
The chart below illustrates the costs for converting the two data sources from flat files to Parquet, joining them together and writing that merged file to Parquet, provisioning a Hive metastore for maintaining Parquet metadata, and storing all Parquet files in a bucket:
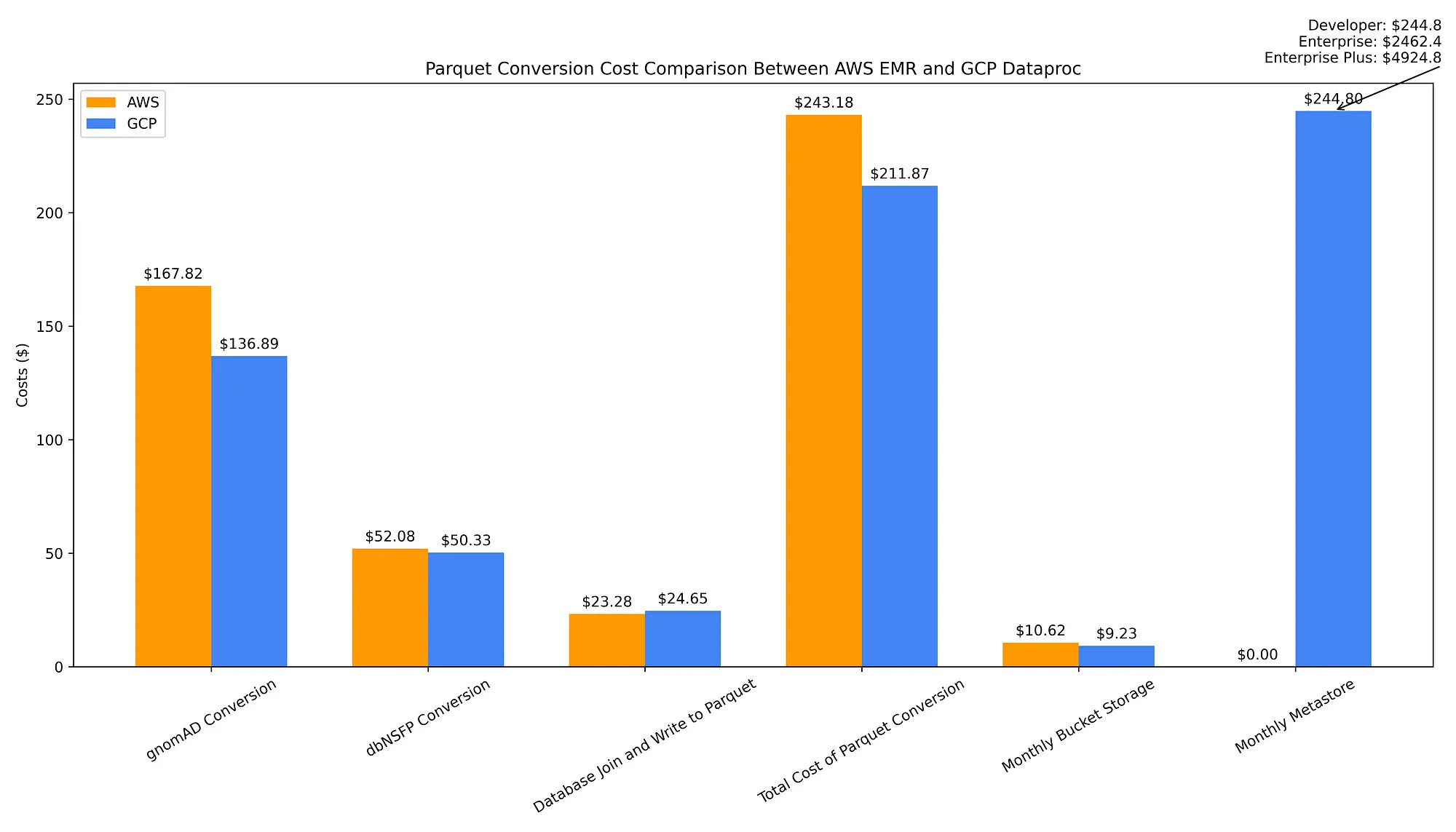
The total one-time cost of converting both databases’ flat files to Parquet and joining them into a merged database Parquet file is all together slightly cheaper with GCP Dataproc ($211.87) than AWS EMR ($243.18). This is due to the high-cost EMR surcharge applied to cutting-edge 7th-generation Graviton machines, such as r7g.16xlarge spot instances.
The cost of storing the output Parquet files in regional buckets is comparable across clouds — you only save $1.39 a month by storing the output Parquet data on a GCS bucket ($9.23) instead of S3 ($10.62).
However, the long-term operational costs associated with using these Parquet files are substantially higher on GCP due to its fully-managed metadata store service having an hourly cost vs. essentially being free on AWS with its Glue Data Catalog, at least until you hit large-scale usage.
With Glue Data Catalog, you would have to exceed 1M objects stored to begin being charged a measly $1 per 100,000 objects stored per month over the 1M objects free tier. Requests to Data Catalog are also free until 1M requests are made, at which point you are charged only $1 per million requests above 1M per month.
Contrast AWS’ metastore, ranging from free to trivial in cost, against the monthly cost of $245 for Dataproc Metastore. That Dataproc cost assumes usage of the Developer tier, which possesses “limited scalability and no fault tolerance.” For larger-scale analytics, you would require the scalable, fault-tolerant Enterprise tier that comes at a monthly cost of $2,462. There is additionally a poorly documented Enterprise Plus tier that doubles this monthly cost to $4,924 (discussions with a GCP PM indicated that Plus means getting a High Availability configuration).
Thus, while one-time data conversion and metadata creation costs are slightly higher in AWS, and long-term storage costs are about the same, in terms of usage of Parquet files as a data warehouse, AWS wins due to the trivial cost of having a Parquet metastore. A Hive metastore is essential to both improve the cost efficiency of querying Parquet files as well as making them easier and more convenient to access — for example, by enabling them to be queried via ‘table’ names rather than querying the filepath directly — so I consider it a required component to a Parquet-backed data warehouse.
Part 2: The Cost of 17 Complex Analytical Queries
We’ve compared the cost of transforming terabytes of flat files to Parquet format and hosting a metadata store for those files to accelerate query runtimes against them. Now let’s examine the cost of running queries against these datasets using several cloud data warehouse services.
A summary of the 17 queries that will be run against each DWH is provided in the Appendix to highlight the complexity of the queries being run. For genomics-minded folks, further detailed explanations are provided via comments in the code files.
Option 1: Ephemeral Spark Clusters as a Data Warehouse
Let’s start off by assuming our data warehouse consists of ephemeral Spark clusters querying bucket-stored Parquet files:
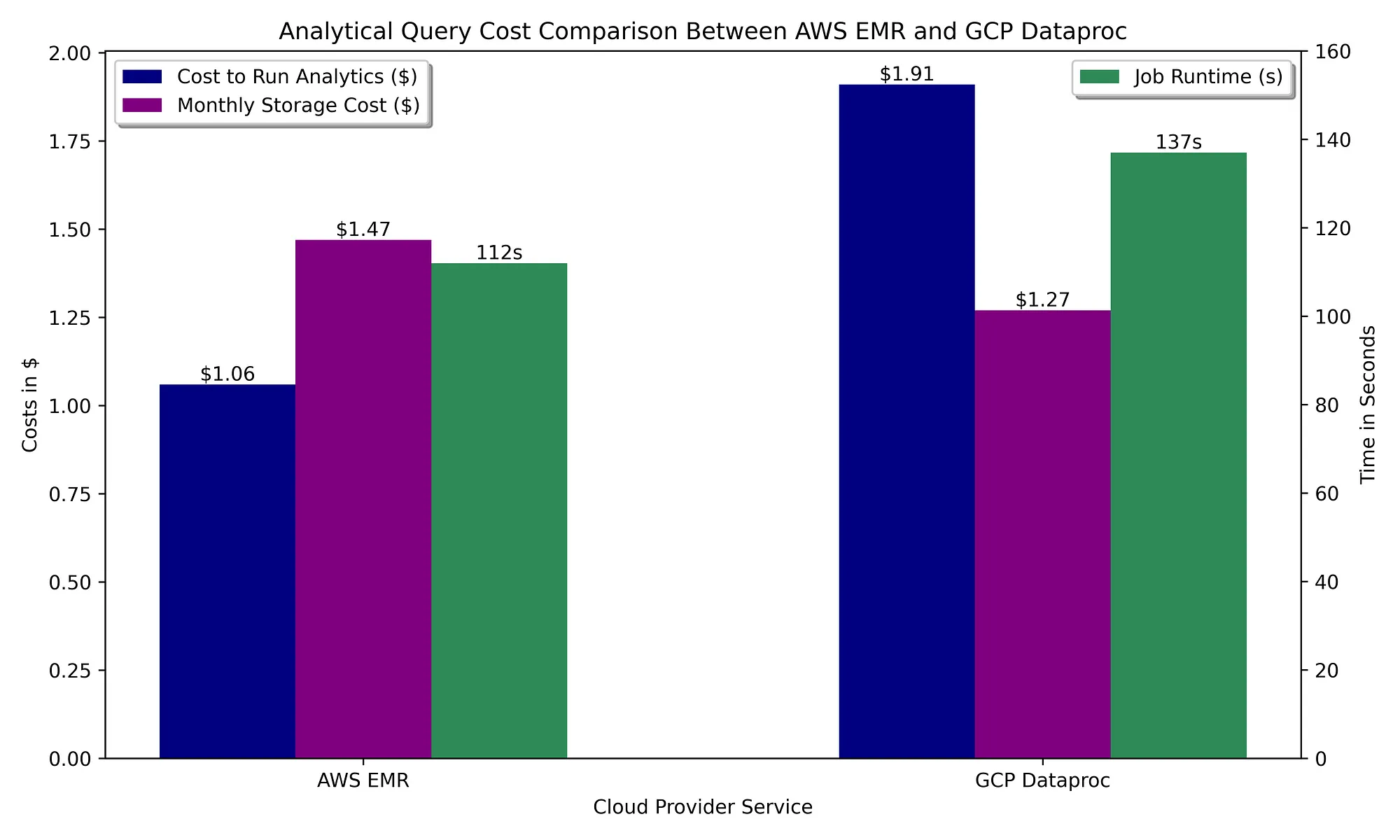
Like the Spark-powered data prep step, running analytics on managed Spark offerings comes with a similar cost in both clouds. In this case, AWS has an edge over GCP due to EMR’s idle auto-termination config allowing as low as 60 seconds of idling before terminating the cluster, while Dataproc’s auto-termination config can only go as low as 5 minutes. Given that these queries do not require much time to complete, the minimum supported idle time that leads to cluster termination works against GCP.
Spark functionality is identical in each cloud, so there’s no real functional advantage to either cloud. With EMR’s cheaper, faster execution on shorter-lived clusters and free metastore vs. the high cost of hosting a Hive metastore in GCP, Spark-based analytics swing heavily into AWS’ favor.
Option 2: Serverless DWH offerings
What if we want to replace Spark as a DWH with a cloud provider’s fully managed and serverless data warehouse service — where queries can be run with only SQL —so that we can avoid writing Spark code?
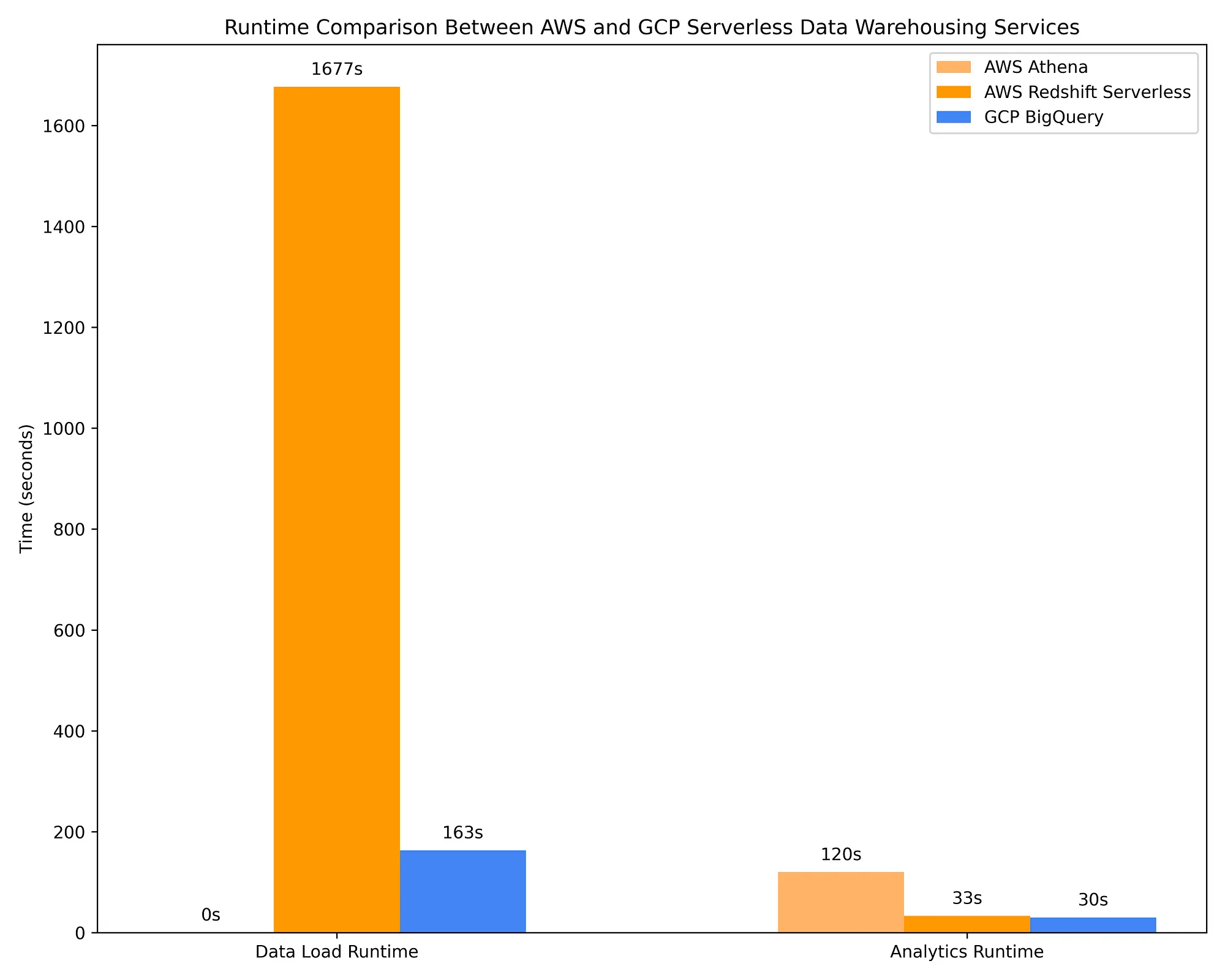
Shown below are AWS data warehousing using Athena and Redshift Serverless cost comparisons against GCP BigQuery on-demand. The same 17 OLAP queries used in Step 2 Option 1 are used for these DWHs. It is with this comparison that the cost effectiveness of DWH options becomes clear:
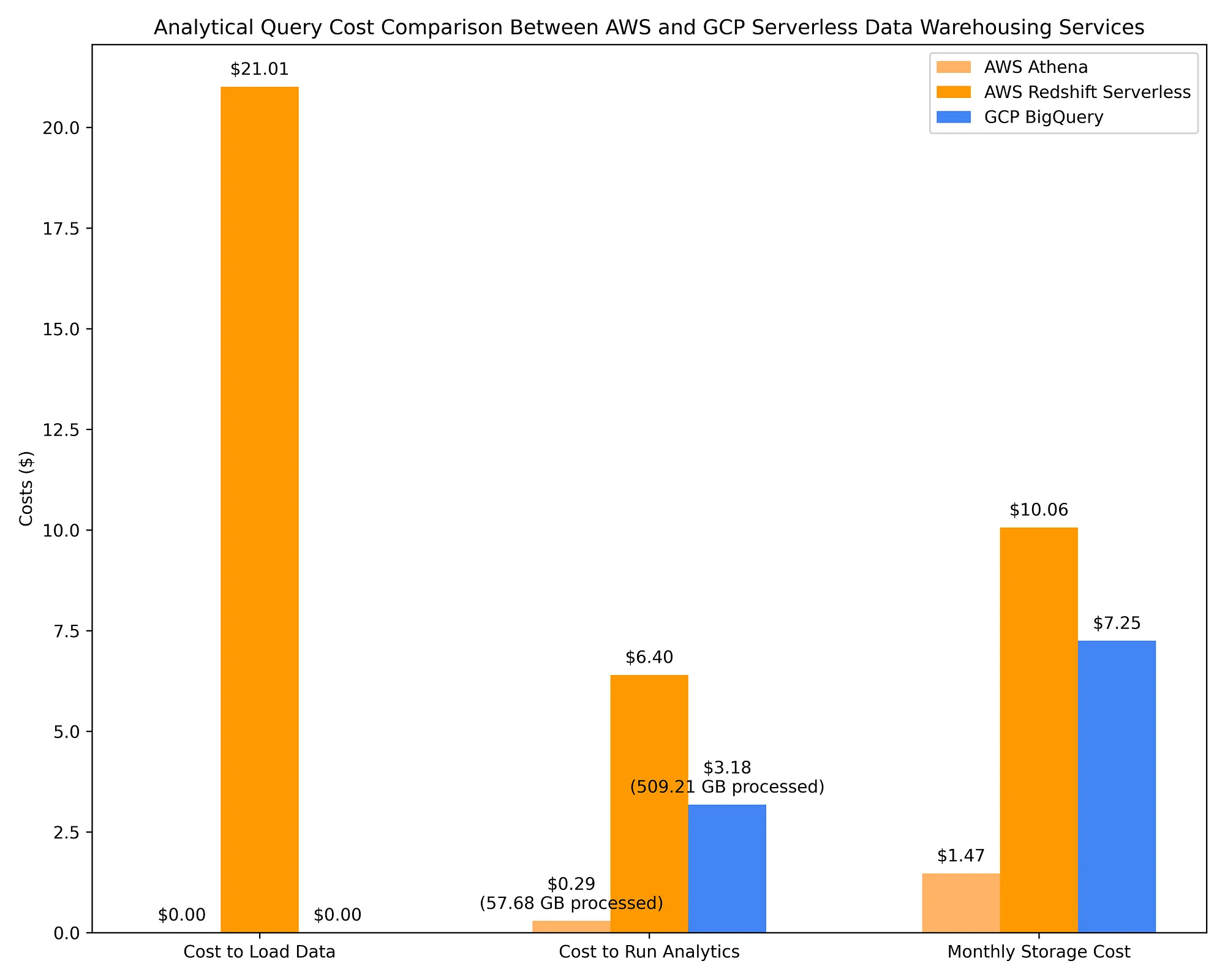
Redshift and BigQuery calculate query-optimizing column metadata when data is inserted into a table. Such metadata optimizes queries by, for example, enabling pushdown predicate filters that reduce how much data has to be scanned to execute a query. This, by extension, reduces the cost of queries that are charged based on how many TBs of data they scanned, either directly (BigQuery) or indirectly (Redshift via the number of RPUs required to run a query).
Parquet files contain metadata, and if you calculate and store additional metadata on those files to a Hive metastore using Spark, OLAP queries hitting them will utilize very similar query-optimizing column metadata.
Whether you’re using a serverless DWH or Spark clusters querying Parquet files, you are leveraging pre-calculated column metadata that enables highly complex queries against TBs of data to be typically complete in seconds while having only scanned a few GBs or MBs, thanks to the available metadata. This is why, for example, running 17 complex queries against several TBs of data can cost little more than a quarter after scanning only 57.68 GB, as seen in AWS Athena’s costs above.
The cost comparisons shown above, as well as in Option 2 Part 1, reveal that querying Parquet files paired with a Hive metastore via AWS Athena, AWS EMR, and GCP Dataproc is much more cost-effective than querying with cloud-native data warehouse services. It’s a pretty interesting finding considering that all these systems rely on the same principle of query plan optimization by utilizing column metadata for a columnar file system.
Nonetheless, serverless DWH offerings are nowhere near as effective at optimizing queries based on column metadata. BigQuery, for example, scans ~10X more data than AWS Athena scans when querying Parquet files via AWS Glue Data Catalog, charging ~10X more as a result. BigQuery’s query costs are also >2X that of running those same queries on ephemeral Spark clusters with spot/preemptible instances on AWS EMR / GCP Dataproc. BigQuery may complete its queries ~4X faster than AWS Athena, AWS EMR, and GCP Dataproc, but this comes at ~10X the cost. Depending on your use case, this may or may not be worth the additional cost.
AWS Redshift is a service that began as a provisioned capacity service and implemented a quasi-serverless version much later (the ‘serverless’ offering requires capacity planning in the form of Redshift Processing Unit, or RPU, scaling configuration). Given its roots, Redshift Serverless remains the priciest of the on-demand DWH options in large part due to its ‘serverless’ pricing remaining reliant on resources provisioned rather than TBs of data scanned. Given that Redshift also behaves more like Postgres than a cloud-native serverless data warehouse, and considering it lacks native integrations with AWS IAM and the fact that it takes ~9X longer than BigQuery to load data into tables at a non-trivial cost…I personally cannot recommend Redshift. It is advantageous only if your data engineers are very familiar with Postgres and only if they cannot, for whatever reason, work with any other data warehouse option.
Which Data Warehouse Should You Pick?
Recommendation: If cost is the only concern
If cost is the only consideration, and if your use-case supports Parquet files as the backend (i.e., your datasets being queried are not reliant on real time streaming data), I recommend you use Parquet files stored in a bucket and query them with a serverless query engine like AWS Athena or an ephemeral cluster service such as AWS EMR or GCP Dataproc. Serverless data warehouse offerings such as BigQuery and Redshift offer convenience, better support for real time streaming use cases, and many other value-added features I’ll cover shortly —but this all comes with a substantial cost.
It’s worth noting that at a large enough operational scale, BigQuery and Redshift will hit artificial limitations that require you to move from an on-demand to a slot/CPU resource-based pricing model. This move will likely cost more than the equivalent on-demand.
BigQuery on-demand charges per TB scanned; however, it is limited to only 2,000 slots (~2,000 cores and ~2 TBs of memory) for use across all queries. You also cannot use key BigQuery features, such as BigQuery ML queries, with BQ on-demand or even BQ Editions Standard. If you anticipate needing any of the following, you must switch to one of three BigQuery Editions resource-based pricing tiers:
- More than 2,000 cores / 2 TBs of memory (Standard)
- Running ML training and predictions within BQ using SQL (Enterprise)
- Row- and column-level access controls (Enterprise)
- Materialized views (Enterprise)
The cost-effectiveness of Redshift serverless scalability is similarly limited and also requires a flat-rate cluster to solve.
Resource-based pricing models can be complex (particularly so for BigQuery Editions [1] [2] [3] ) and difficult — if not impossible — to arrive at a genuinely accurate cost estimation without running all workloads on a resource-based deployment for a few days and, from that, forecast monthly/annual costs. There are peculiarities, such as BigQuery Edition’s flawed slot autoscaler (it only scales in increments of 100 slots, and it bills for a minimum of 1 minute for a given slot quantity regardless of whether queries are using those autoscaled slots), as well as the unknowable variable of how many slots all of your queries will collectively require to run, that cannot be accounted for without simply running all workloads in a full production-simulating test on the flat-rate model.
Regardless of the pricing details, I have observed across many DoiT customers that flat-rate pricing models will generally cost more than the on-demand model. Unless you plan on running OLAP queries 24/7/365, and only if those queries consistently request the same quantity of compute resources over time, flat-rate is unlikely to save you much, if any, money compared to on-demand pricing.
Given the information above, if you are focusing solely on cost efficiency without regard for value-added functionality, I would recommend the following services in order of likelihood of being the least expensive to the most expensive:
- AWS Athena with AWS Glue Data Catalog (cheapest)
- AWS EMR with AWS Glue Data Catalog
- GCP BigQuery
- GCP Dataproc with GCP Dataproc Metastore
- AWS Redshift (most expensive)
I would not end the conversation here, though. It is important to carefully weigh the cost of serverless DWH systems against the features they enable.
Recommendation: If cost is weighted against functionality
Querying Parquet files with Spark code or Athena SQL may be highly cost effective, but this approach has limitations. You will miss out on the feature richness advantages that services like BigQuery bring.
Below are some of the key advantages that, in my opinion, make BigQuery worth the extra cost in many cases:
- Accessibility. The BQ UI is beautiful, easy to use, and easy to learn. Data scientists — who may be less inclined to learn Apache Spark and other complex systems — will appreciate having a nice, SQL-based UI for storing and querying data.
- Point-in-time recovery. PIT is baked into BQ, with time travel up to 7 days set as the default. By contrast, while you could turn on bucket versioning to enable the restoration of accidentally deleted Parquet files, this is not as convenient as restoring a table with one SQL command. Data lakehouse projects such as Apache Iceberg and Delta Lake can enable SQL-based PIT recovery on Parquet files, but in brief tests I’ve run, lakehouses increase query runtime by at least 2–3X. By relying on a data lakehouse, you lose out on the high-performance cost advantages of relying only on Apache Spark to query Parquet data.
- Native IAM integrations. BQ’s native reliance on GCP IAM makes sharing data and controlling access to that data to a very granular level possible and surprisingly easy. It is straightforward to share datasets and tables with other GCP users. You can even limit users’ ability to view particular columns and particular rows. Sharing and granular access control isn’t something you’ll get with a Parquet-backed file system.
- Native real-time streaming service integrations. If real-time data ingestion is key, BigQuery natively integrates with PubSub and Dataflow. These services enable queries to hit real-time streaming data with only a few seconds of latency, at most. BigQuery sets itself apart from all other DWH systems in this regard; even Snowflake’s real-time data ingestion can take several minutes to become available. Making data available for query in near real time, to the best of my knowledge, is not possible with a Parquet-backed file system.
- Native integrations with…almost everything. There’s a UI/UX aspect to BigQuery that shouldn’t be underestimated. With BQ on-demand, you can see the estimated cost of a query before you even run it. Let’s say you’re OK with the cost of a query and run it. With a single click of a button, you can export the results of that query to Looker Studio, where a visualization is automatically built based on what Looker Studio’s ML-powered algorithm thinks you’ll want to visualize from your query results. It is similarly easy to move query results to GCP’s Vertex AI for machine learning, or build/deploy an ML model directly within BigQuery through BQ ML SQL, or to export query results to Google Drive, and so on. BigQuery isn’t just a data warehouse. BigQuery is a part of a service ecosystem built seemingly entirely around BigQuery.
Unlike BigQuery, Redshift sadly offers more headaches than benefits. I would place it last in terms of cost-effectiveness and feature richness. It behaves more like Postgres than a data warehouse, and as such, to use it well requires becoming intimately familiar with tweaking table performance, as well as user/group creation and permissions within Redshift due to its IAM controls remaining separate from AWS IAM. Redshift integrations with other services are clunky or non-existent. Connecting it to SageMaker and performing ML training can be onerous, and there are no native integrations between Redshift and Quicksight to enable visualizations on your queries. Considering the exceptionally high cost associated with this service, whether you use its serverless or provisioned capacity version…there really is no benefit to using it. There are several better options, including within AWS itself (AWS Athena and AWS EMR paired with AWS Glue Data Catalog).
If you want to balance value-added functionality with total cost, I recommend data warehouses based on the following ordering:
- GCP BigQuery (brings the most value of any DWH option)
- AWS Athena with AWS Glue Data Catalog
- AWS EMR with AWS Glue Data Catalog
- GCP Dataproc with GCP Dataproc Metastore
- AWS Redshift (brings the least value of any DWH option)
Appendix
The DoiT Navigator’s Reporting capabilities were leveraged to simplify and speed up total cost determination for each Part. This platform unifies spending across all cloud providers and enables easy creation of reports with complex grouping and filtering criteria. For example, a breakdown of cloud spend by day, cloud provider, service, and SKU can be obtained within seconds with relative ease; this type of report was frequently leveraged to effortlessly gather the spend data reported in this article.
Cost calculation details and query complexity explanations can be found in the code base that pairs with this blog: Appendix.md
Do you still have questions about utilizing the recommendations I’ve provided to enable GCP or AWS data warehousing success within your organization?
Reach out to us at DoiT International. Staffed exclusively with senior engineering talent, we specialize in providing advanced cloud consulting architectural design and debugging advice.
If you are interested in deep-diving into other cloud data architecture topics, please check out my other blog posts on Medium.



