








Building and deploying production-grade machine learning models can be somewhat tricky. Even with technologies like Google Cloud AutoML, Cloud ML Engine and other out-of-the-box machine learning tools, training models and using them in production systems commonly requires a vast set of skills that can include some advanced Python programming, understanding complex models, SQL and DB technologies. This blog post demonstrates how to build a prediction system for shared cars/bikes/scooters using very simple tools!
BigQuery GIS adds new capabilities to Google BigQuery that enable the ingestion, management and analysis of geospatial data. BigQuery ML facilitates the creation and execution of machine learning models from within BigQuery, using standard SQL language. In this post we will try to show how one can leverage only SQL language to deploy a complete end-to-end ML pipeline for a geospatial time-dependent use-case.
In order to reduce the number of owned cars, the city of Tel Aviv launched a shared-car project, called AutoTel. Users of the service are able to reserve a car using a mobile app, and pay for it by the minute. The project that was launched in October 2017 attracted over 7500 users, with more than 50% of them using the service at least once a week.
Recent data shows constant growth in the usage of the AutoTel shared-car service. In fact the usage climbed so high that new problems emerged. Like many transportation services, one key factor in the public’s adoption rate is its reliability. Passengers will refrain from adopting an unreliable transportation service, since the cost of not getting to the required destination at the desired time is usually very expensive.
In order for the service to be reliable, AutoTel has to make sure that supply and demand are geospatially balanced, meaning cars are where and when they are needed. This task is extremely difficult since cars are driven and parked by customers who are not aligned at all with this optimization task. For the most part, the distribution of cars is uncorrelated with the demand: one reason is that if a car is parked in a suburban neighborhood, it may take a long time before another user may drive it to the city center, where high demand for the cars exists; thus clusters of unused cars are very often present on the outskirts of the city.
Using machine learning, AutoTel can predict the geospatial availability of cars at given times, and use predictions to modify their business model. They could, for example, modify prices so that it would be cheaper to park cars in high demand areas, or plan the the maintenance program so that cars will be collected from high-supply-low-demand areas and returned to areas of high demand. While this model could benefit AutoTel, developing it may be expensive and complicated, so in this post we will build and deploy a model that predicts the number of available cars, and do it all using only Google BigQuery. The complete code for this demo is available in this GitHub repo.
Part 1 : Data Acquisition
From the AutoTel website I extracted the location of the parked cars, every two minutes for several months. The raw data was saved to Google Storage in CSV format, and later loaded to a BigQuery Table. This short clip shows a visualization of the recorded data using Uber’s kepler.gl tool
https://www.youtube.com/watch?v=ys6PfEugYrw
Additionally I downloaded data from the Tel Aviv Municipal open data website, and loaded tables to BQ containing information on population age, commercial areas, hotel and kindergarten locations, and neighbourhood boundaries. These features are assumed to have a linear relationship with the total number of available cars, and while we may be proven wrong after analyzing the data, we start with this assumption.
Part 2 : Geographical Joins and Grouping
Each row in the raw dataset represents a location of a parked car at a given time. In order to aggregate the data to neighborhood level I needed to use a spatial join statement.
The following code shows how to perform spatial joins:
SELECT car_locs.*, ta_dis.neighbourhood_name FROM car_locs JOIN ta_dis ON
ST_WITHIN(ST_GEOGPOINT(car_locs.longitude, car_locs.latitude), ST_GeogFromText(ta_dis.area_polygon))
Part 3 : Model Training
As of December 2018 BQML supports two types of models — linear regression for regression and logistic regression for classification tasks. We train the models with the following SQL command:
CREATE OR REPLACE MODE
L `autotel_demo.free_cars_model`
--model save path
OPTIONS
(model_type='linear_reg', ls_init_learn_rate=.015, l1_reg=0.1, l2_reg=0.1, data_split_method='seq', data_split_col='split_col', min_rel_progress=0.001, max_iterations=30),
SELECT
free_cars label,
-- declaring target variable
timestamp split_col
-- independent variables:
,age5to14
...
FROM
`autotel_demo.autotel_dataset` as dataset
WHERE
dataset.timestamp <
TIMESTAMP
'2018-10-11'
Part 4 : Model Evaluation
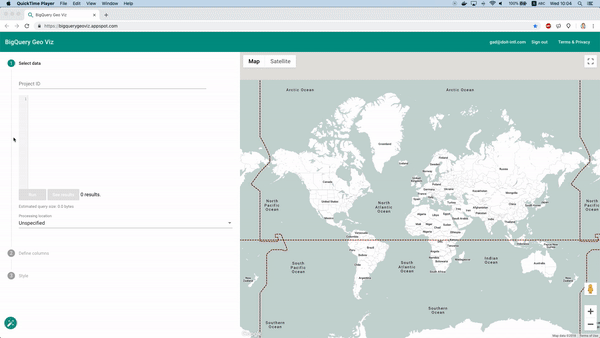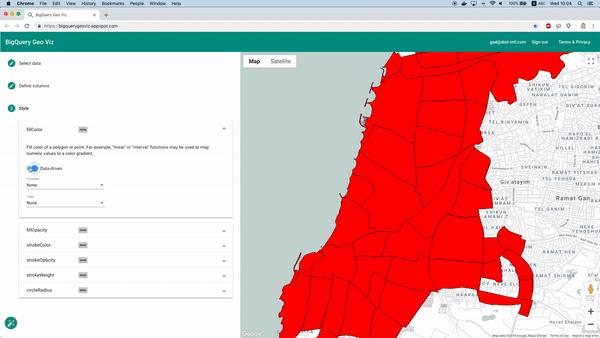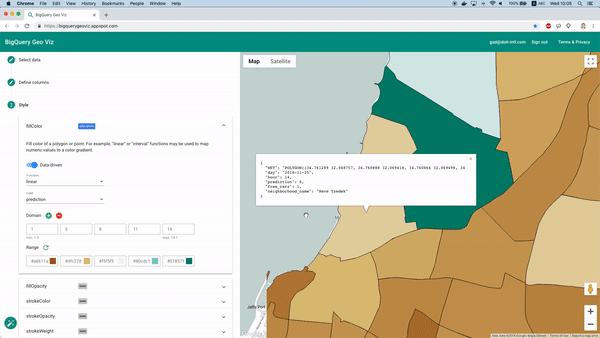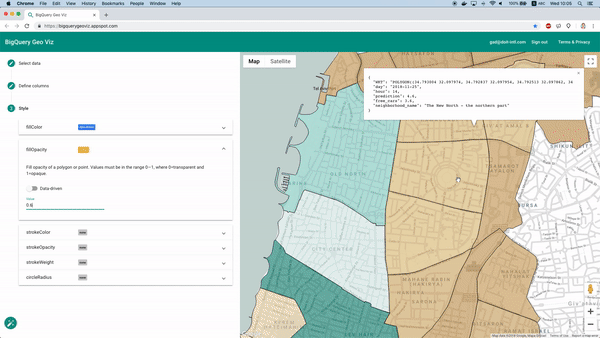
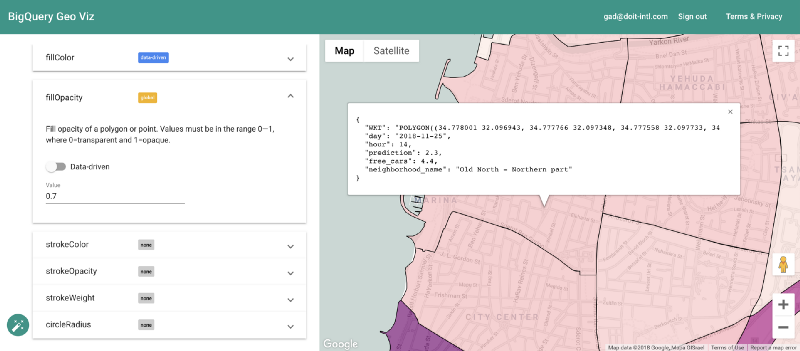
After training we can use “Model.Evaluate” function to provide metrics on the model performance. While these metrics are useful in many cases, this time we are facing a geospatial prediction task, and we would like to view the model predictions on a map.
Fortunately enough this is feasible using the BigQuery Geo Viz tool. Using this tool we can display the neighborhood boundary polygons on a map, and examine the prediction vs the real number of available cars at a specific time. This method lets us examine how the error is distributed geographically.
Part 5 — Deploying to Production
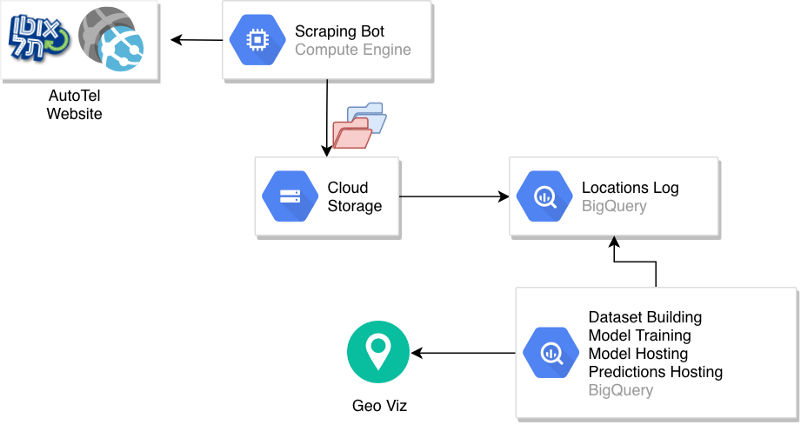
Let’s examine the overall architecture that was created
A scraping bot accesses the AutoTel website and uploads a CSV file with the car locations to a partitioned bucket in GCS.
A BigQuery table is built over the raw data, and a process of dataset creation and model training is initiated manually. After the model is created, it is hosted in BigQuery and used to serve predictions, or generate a predictions table. The predictions table can then be used to create visualizations and serve other components of the production system.
The key aspect that is missing here regards the automation of the process. Loading new data to the locations table, creating new datasets, training models and generating predictions were all described as manual steps. One way to automate this process is to leverage the concept that BigQuery is actually a service that can be invoked through client calls.
We can write a very simple python code to execute all these steps and then use Google Cloud Composer to manage them. Cloud Composer is a very good fit for this kind of task since some steps are dependent on each other; however it runs a cluster to manage the tasks, which could be quite expensive for solely handling this task.
You can think of other ways to schedule the training and prediction script, like Cron or Jenkins, but here’s the thing: for a few dollars a day Google Cloud Composer saves you the need to go through difficult configuration and permissions settings, and the more processes that are managed with it, the more cost effective it becomes.
Summary
As part of the effort to simplify the integration of machine learning models to production systems, BigQuery ML serves a managed tool that can serve as an end-to-end mechanism for the core part of the pipeline. If a simple linear/logistic regression model is sufficient, you will find that BQML can support:
- Data hosting
- Dataset creation
- Model training + hosting
- Inference and serving
With other tools like Airflow or Jenkins, these software blocks can be managed and automated.
It is important to mention that in this process we didn’t have to worry about resource allocation or data access, since we kept most of the process inside a managed data warehouse system that does it for us.
____________________________________
Technical advising and editing: Tony Braun
Want more stories? Check our blog, or follow Gad on Twitter.



