








Let’s start with a short disclaimer — DoiT International does not promote, condone or advocate licit or illicit drug use.
The use of marijuana for recreational purposes is illegal in Israel. But where is a demand, there is always a supply. Telegrass is a network for purchasing marijuana in Israel. It operates on top of Telegram — a free chat application with communications being encrypted end-to-end . The network offers quick deliveries with the option to write reviews about the sellers. The monthly turnover of Telegras is estimated at $17 million.
Users can read reviews about the sellers so they can make a better decision from who they are going to make a purchase. There is a conventional bot that helps the user to write a review and rate the seller on 4 points while each ratings is between 0 to 5.
- How was communication with the seller?
- What was the quality of the product?
- Was the price fair?
- Was it delivered on time?
Data Acquisition
Let’s start by grabbing the reviews from Telegram. We will use the telethon — a python library to work with Telegram API. We are only interested in the message body, since the reviews are submitted by bots (after some human review) so the message metadata is not particularly interesting.
Here is the config file
Lets run it:
python geth.py >reviews.txt
The output would look something like this:
[‘ביקורת על הסוחר: @weed1614\nאיזור פעילות: באר שבע — באר שבע’, ‘חוות דעת מספר: #71584\nנשלח מאת: @Hoover656\nנשלח בתאריך: 15:25 22/12/17’, ‘חוות הדעת:\nשווה כל שקל,ירק ברמה ממש גבוהה,יבש,טעים,מפוצץ באבקנים.’, ‘\nתקשורת: 🌟🌟🌟🌟🌟 (5/5)\nאיכות: 🌟🌟🌟🌟🌟 (5/5)\nמחיר: 🌟🌟🌟🌟🌟 (5/5)\nהמתנה: 🌟🌟🌟🌟🌟 (5/5)’, ‘להגשת חוות דעת: @TelegrassBot לשירותכם!’]
As you can see (even if you don’t read modern Hebrew) there is a mixture of letters, symbols, and numbers without any apparent structure (also remember the fact Hebrew is right to left language as opposed to English which is left to right). So the next step that we need to apply is prepared the data for analysis
Data Preparation
Before we can query and analyze the data, we would need to prepare it for the analysis i.e. clean it and make it more structured.
However, writing the code that will to this is a very time consuming and relatively dull task with a lot of trial and error. Lucky for us there is a new service by Google (still in beta though) — Cloud Dataprep. Quoting from the product’s website :
“Google Cloud Dataprep is an intelligent data service for visually exploring, cleaning, and preparing structured and unstructured data for analysis. Cloud Dataprep is serverless and works at any scale. There is no infrastructure to deploy or manage. Easy data preparation with clicks and no code.”
Well, I’ve figured out that the reviews data could give Dataprep a run for it’s money. So in just 60 trivial steps or so (listed below) and without writing a single line of code I was able to create a structured data from the ratings. The DataPrep UI allows you to see in real time the transformation and therefore to visually debug and adjust the process. Some steps involved splitting the data based on charters or patterns and dropping rows with invalid values.
Finally, Cloud Dataprep natively supports writing the resulting data to a large variety of data sources. For my purpose, I have opted for Google BigQuery — Google’s serverless analytical database.
Now the data is nice and clean.
Analysis
Once we have the data all nice and tidy, it’s time to analyze it. Let’s check how the price is related to the other ratings using BigQuery’s CORR() function which calculates Pearson Correlation coefficient. The coefficient of -1 indicates strong negative correlation, the coefficient of +1 indicates strong positive correlation and finally coefficient of zero means there is no correlation.
price_wait,price_communication,price_quality
0.679, 0.774, 0.793
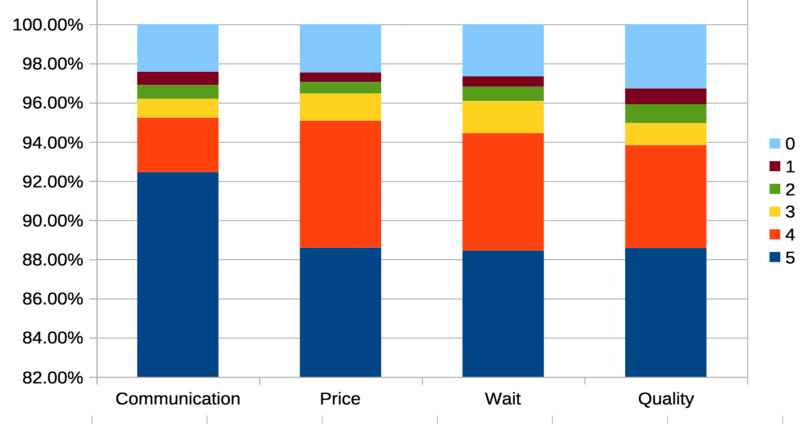
As you can see the highest correlation to the satisfaction is the price and the quality of the product. Should we trust the rating? Well, the online rating is often subjected to self-selection bias. Let’s see if the reviews in Telegrass have the same issue.
As we can see for the results, either our sellers are superb in every possible manner or we have some bias in the user ratings or perhaps maybe after using the product people tend to be more positive☺️
Now let’s see what are the most popular bigrams and are they correlated to the high ratings
The most popular bigrams are:
- Amazing man
- Awesome product
- Highly recommended
We can see that there is a high correlation between the high scores and the most common bigram in the reviews.
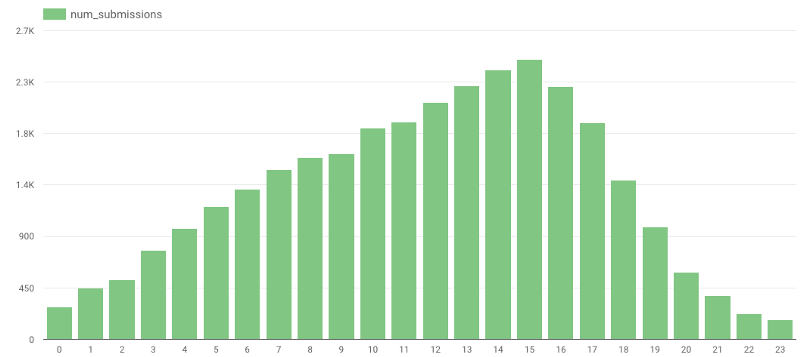
Can you guess what’s the most popular time for submitting a review? If I had to imagine, I would say sometime during the late evening, or the night, however, the actual data proved me wrong:
Now let’s see if there is a correlation between the city size and the number of reviews. We will start by getting the top 20 reviews generating cities. The results will be added to a new table (by_city)
Now will will add a new coulmen population and we will populate (pun intended) it with data from the the Israel Central Bureau of Statistics (data is for end of 2016). So let’s see the results:
Before we start to compare the results, one thing is standing out. Almost 1% of the Tel-Aviv population is writing reviews in Telegrass!, not using the product or just buying, but actively participating.
We will take a look at the first and the last results. If you’re a bit familiar with the demographics of Israel, it shouldn’t be a big surprise. Tel-Aviv is a city with young population and a center for many high tech companies, it is the most liberal city in Israel. People are very tech savvy and like to state their opinion. At the bottom we will find Bnei Brak, the city is dominated by low income religious people so it’s pretty obvious why not so many people are writing reviews.
Now it is time to play a bit with ML using TensorFlow. First I created a training set and a test data set.
I took the code written by Akshay Pai and adjusted it a bit to my needs.
After loading the data and preparing it the ML code is this:
Once the training was done I used model.predict in order to predict the score.
I loaded the test set and calculated the RSME. The RMSE is 1.4, the values are between 0 to 20, so I results are not amazing but can predict pretty well from the text what will be the numerical rating.
You don’t have to be a full fledge data scientist or data engineer in order to get some interesting insights out of an un structure text, without writing a single line of code to prepare it for analysis. Then you can analyze it using BigQuery and TensorFlow to get some interesting insights.



