The 7 anti-patterns companies make around how they organize resources and set up controls and policies.

Your cloud landing zone is the foundation of your cloud infrastructure. How you organize your resources and set up controls and policies will have a huge impact on whether your cloud journey is smooth sailing or rough riding.
For instance, a well-structured resource hierarchy will make your life easier when it comes to allocating cloud costs and configuring access control. A poorly set-up resource hierarchy will have you scratching your head over which team is responsible for which cost and increase the chances that someone sees data they aren’t supposed to see.
And while every cloud provider describes a set of best practices for setting up your cloud landing zone for success, we still see some common anti-patterns being performed.
Applying our experience gained through helping 3,000+ digital native companies with their cloud challenges, we’ve highlighted the top 7 landing zone anti-patterns that we observe most and what you should be doing instead.
Let’s dig in.
Anti-Pattern #1: Not utilizing Organizational Units (OUs) and/or Folders
Failing to establish proper Folder (Google Cloud) or Organizational Unit (AWS) structures can lead to resource sprawl and difficulties in managing access and permissions.
Ideally, your cloud resources should be organized in a way that matches your actual organization structure, and Folders/OUs are a great way to set that up.
They’re used to separate and categorize resources for different departments/teams within your organization. Within these, you’ll have projects (Google Cloud) or accounts (AWS), with each of your workloads belonging to a single project/account (more on that in our next anti-pattern).
Folders and OUs are also great for setting guardrails via policies and permissioning. For example, you may want to block users in a specific department from accessing regions you don’t use. Or you might want to prevent development teams from using specific instances like T2Ds in Google Cloud or X1s in AWS.
But while Folders/OUs can be nested, you shouldn’t make things too complicated unless you really need to. The more levels that you add to your cloud resource hierarchy, the more hassle you’ll encounter trying to manage everything.

Anti-Pattern #2: Housing all resources within a single AWS account or Google Cloud project.
When you group all your workloads together in a single account or project, you make it challenging to manage costs, track usage, and enforce security controls.
For example, imagine you have resources related to two different applications located in the same Google Cloud project. By not isolating resources into different projects/accounts, you become overly reliant on having a perfect tagging policy (more on that in the next anti-pattern). Tracking expenses and attributing costs to specific teams, applications, or environments becomes convoluted, hindering your ability to identify opportunities for cost savings and efficient resource allocation. This will only get more complicated as your organization grows.
Additionally, when all resources are concentrated within a single account or project, any security breach or misconfiguration can potentially affect all services and workloads (thinking in terms of blast-radius reduction can help mitigate the impact of negative events).
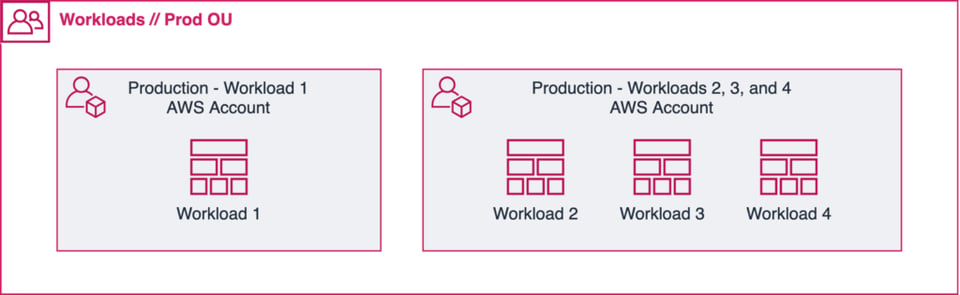
When possible, go with a single workload in a single account/project. However, sometimes when you have small workloads that are similar to each other in terms of scope, you may want to put them all in the same account (see illustration above).
Finally, while you do have less administration with fewer accounts, by separating your workloads you benefit from built-in operational security features like permission structures and rate-limiting (anyone who's tried to put 100+ buckets into an account will be aware of those limits).
Anti-Pattern #3: Underutilizing Tags/Labels (or not using them at all)
Tags (AWS) and Labels (Google Cloud) are used to provide fine-grained information around your cloud resources.
Use cases include:
- Billing enrichment (ex. adding cost center information to a resource)
- Environment/application classification (ex. specifying data-security levels)
- Automation (ex. determining reboot schedules)
…but let’s focus specifically on the first point and why tags are so important.
Tags and labels play a crucial role in cost allocation and tracking. And good cost allocation sets you up for success when managing your cloud spend.
Without proper tagging, it becomes challenging to associate expenses with specific projects, departments, or teams. Failing to utilize tags and labels means missing out on the opportunity to generate detailed insights, track usage trends, and generate meaningful reports for informed decision-making. This lack of granularity can lead to cost inefficiencies, overspending, and difficulty in identifying areas for optimization.
With tagging, it may be tempting to define a highly-detailed structure with many different tags that should be applied to every resource. While this level of tagging is admirable, it’s unrealistic when getting started. We recommend starting small, and using 2-3 tags only, but being very strict on enforcement of these.
The three absolutely required tags (in our opinion) are:
- Application name
- Team
- Stage/Environment
Being as tags are case sensitive, we recommend adopting a naming standard, such as snake case, to avoid having duplication of tags. The names can, of course, be changed to suit your company culture, but should be descriptive and clear. In this case, “app_name” refers to a microservice or workload name, and “env” is a development stage, such as “development”, “testing” or “production”
Values for both fields should ideally come from a relatively standard list - again if you have users tagging their resources with variations of “Website - Frontend”, it could lead to problems analyzing the data.
One example where tags will help you better understand your cloud consumption could be when there’s a ‘shared resource’ account within an organization and all the database resources (which are used by multiple teams) are located there. For each database you can assign a tag or label that determines which team should be charged for usage of that resource.
We cover more on this in our Resource Labeling Best Practices blog post.
Anti-Pattern #4: Using shared Google Cloud projects or AWS accounts among different teams.
For similar reasons to Anti-Pattern #2, sharing projects/accounts between teams hampers resource governance and creates potential conflicts over access, permissions, and costs.
Imagine cramming different teams into the same room. No one gets their own space, and there's no privacy. Shared projects/accounts in the cloud are a bit like that — but everyone has the keys to everyone’s rooms, so It’s much easier for folks to stumble into places they shouldn't be. Different teams might have different rules to follow, and it's tough to keep everyone in line when everyone’s resources are mingled together. Plus, if there’s a security breach/incident, you increase the “blast radius” in terms of impact when you have teams sharing an account.
With resources grouped together, costs will also get mixed up, making cost allocation difficult — unless you have perfect tagging. It’s like splitting a restaurant bill between friends where nobody remembers what they ordered.
Lastly, in a shared setup, you’ll run into situations where teams end up fighting over resources, leading to slow performance and downtime.
Instead, you should follow the advice from Anti-Pattern #2 and have a one-workload-one-project/account policy. This ensures clear ownership, easier management, and reduces the risk of unintentional interference with others' resources.
Anti-Pattern #5: Running workloads within the AWS management account.
Occasionally, we’ll encounter a customer who has all their resources in the management account because they started their company as a Minimum Viable Product (MVP) in this account, perhaps not thinking twice about it. Then as the company grew and evolved, they just kept building within that account.
The AWS management account should be reserved for administrative functions, and hosting workloads there increases the risk of accidental misconfigurations and exposure to security vulnerabilities.
One important reason to keep your resources in other accounts is because an AWS Organization’s service control policies (SCPs) do not work to restrict any users or roles in the management account.
We recommend that you use the management account and its users and roles solely for tasks that can be performed only by that account. The one exception is that we do recommend that you enable AWS CloudTrail and keep relevant CloudTrail trails and logs in the management account. Its primary purpose is for security, so you can know who changed what and when in your AWS account. But it can also be used for events - so you can react when a new EC2 Instance is launched.
As mentioned above, you should look to isolate workloads into separate AWS member accounts. This separation enhances security, simplifies management, and mitigates risks.
Lack of Automation in Security Policies
Anti-Pattern #6: Lack of automation in security policies
Manual enforcement of security policies is error-prone and time-consuming, leading to potential breaches, overspending, and inefficient resource utilization.
Imagine manually applying, validating, and adjusting policies — all the time!
You should aim to establish a baseline security posture automatically. In an ideal world, every new resource configured in the cloud will automatically have relevant security policies applied. Automation does not only apply to consolidate security policies across heterogeneous environments but also (perhaps even more importantly) to evaluation and remediation of events. Stable systems will be able to remediate events based on policies without human intervention, allowing teams to focus on value creation. Services such as AWS Config, Amazon EvenBridge and Amazon GuardDuty can massively help in creating these workflows.
As mentioned earlier, maybe you don’t want your teams to use specific instances (ex. T2D). Or you don’t want anyone to be able to launch instances in a region you don’t currently operate in (a common tactic with crypto mining-related breaches). Automated security policies can continuously monitor your cloud environment and perform these kinds of checks with validated and consistent responses.
Anti-Pattern #7: Overlooking organizational-level policies and best practices.
As mentioned above, a stable organization is able to consolidate security policies and configurations via automation, to use resources more efficiently. This requires a cloud governance strategy to be in place highlighting what are the primary drivers for securing workloads and data on the cloud, the teams responsible and the tools that will be used. Failing to have a minimal skeleton for such a strategy will inevitably open the organization to regulatory risk, inefficient use of resources and exposure to threat vectors.
Cloud Governance is not only based on security practices. The lessons learned from teams operating the cloud can also lead to a more efficient usage of resources and the creation of architectural best practices that should be shared across the different teams managing cloud resources. More advanced organizations define and constantly refine reference architectures that include types of resources to use (think of services or machine types allowed) and security policies: this increases the product team's velocity as they won’t have to redevelop an architecture from scratch for every new product deployed.
By recognizing and addressing these common landing zone pitfalls, you'll be well-equipped to better understand your cloud spend, optimize costs, and enhance your security posture. Many of these steps are especially pivotal for allocating costs.
Want to dive deeper into cloud cost allocation? Watch our on-demand webinar covering FinOps, cost allocation, and how to perform cost allocation with DoiT Cloud Intelligence™.