









At Google Next 2019 conference in San Francisco, Google announced that Cloud Run has moved into Beta, so I’ve felt this is a good time to test it on some real-world application.

Google Cloud Run is a managed compute platform that automatically scales your stateless containers. Cloud Run is serverless: it abstracts away all infrastructure management, so you can focus on what matters most — building great applications. It is built on top of Knative, letting you choose to easily run your containers either fully managed with Cloud Run, or in your Google Kubernetes Engine cluster with Cloud Run on GKE.
I wanted to compare a service running on a vanilla GKE cluster against Cloud Run on both the fully managed version and the one that is running on my own GKE cluster.
To test the Cloud Run, I’ve decided to use Banias (code on Github) which is an Opinionated Serverless Event Analytics Pipeline. Banias has two parts:
Frontend — receives all the events from the clients and writes them into Pub/Sub. The frontend is implemented in Go.
Backend — a Google Cloud Dataflow which validates and mutates the data from Pub/Sub and writes it into BigQuery. The backend is implemented in Java and Google Dataflow SDK.
I ran into two issues while trying to deploy Banias on Google Cloud Run:
- Banias uses Viper for its configuration. Viper uses a prefix for each environment variable. However Cloud Run uses the environment variable PORT, so we had to change our code to look for PORT and not BANIAS_PORT.
- Cloud Run can only listen on one port. Banias expose a Prometheus endpoint for scraping. This did not work on Cloud Run
I have installed Banias on variety of different implementations:
- On a GKE cluster (nodes are n1-standard-4) as a “normal” deployment
- Separate cluster with the (same node config) but using Cloud Run
- Managed version of Cloud Run
My experiment has started with testing the time it takes for the first request to be handled(e.g. cold start):
- GKE ~0.008 seconds
- Cloud Run on GKE ~7 seconds
- Cloud Run managed ~7 seconds
For load generation, I’ve used K6 — developer centric open source load testing tool written in Go. I’ve opted to store test results with InfluxDB and visualize them with Grafana. To start generating the load, we ran K6 as following:
k6 run — out influxdb=http://x.x.x.x:8086/myk6db — u 2500 — duration 1m — rps 6000 test_file.js
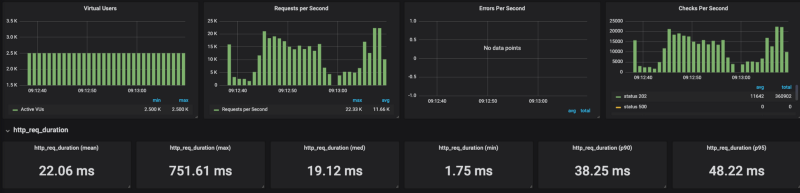
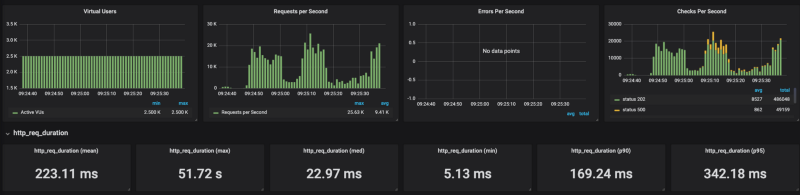
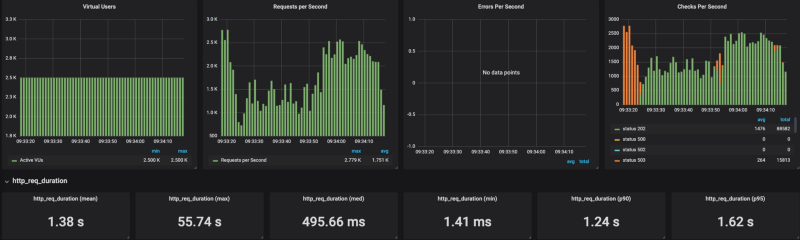
As you can see from the result Cloud Run is having some hard time scaling under a heavy load (I tested it with a range of concurrency settings from 80 to 1 with the same results). When I put a limit on the number of requests per seconds (no limits results in 20K RPS) to around 4k RPS, Cloud Run could handle it reasonably well.
It is very easy to deploy workloads on Cloud Run, however, it seems that for now, not all types of workloads and loads can run efficiently on Cloud Run.
Want more stories? Check our blog, or follow Aviv on Twitter.



