




Hadoop/Spark using Dataproc on Google Cloud
Dataproc is the go-to option when running a Hadoop cluster on top of Google Cloud Platform and is definitely a LOT easier than manually managing a cluster. Since Hadoop is part of the big data ecosystem, it many times has a big price tag to match that big data aspect as well. In order to reduce this price tag, many customers use preemptible instances as worker nodes on this cluster.
For the uninitiated, preemptible instances are virtual machines that exist using excess compute resources that a cloud provider has at that moment and can be reclaimed when those computing resources are needed elsewhere, thus they are good to think of as temporary virtual machines. They may or may not be available at any given point in time due to the availability of computing resources and they may be reclaimed back at any point in time with little to no notification. To offset this potential downfall the price of these instances is massively discounted, up to 80% according to Google, versus traditional virtual machine instances.
These instances are often attached to Dataproc clusters to reduce costs significantly or to allow add additional processing capability when needed.
A scenario that is brought up to us at DoiT International quite often is that a customer has an existing or is needing a new Hadoop cluster that will be running Spark jobs that run for long periods of time (hours or even days), but they need to be able to be scaled to the needed load or priced as cheaply as possible. Most of the time Dataproc with preemptible instances is ours and Google’s recommended option for this.
A question that some more risk-averse customers have asked us is: how does Dataproc handle the scenario when preemptible instances are reclaimed back by Google especially on very long-running jobs processing mission-critical data?
In order to answer this particular question, I created a scenario or experiment to simulate this happening in a production batch-load environment to determine how GCP’s managed Hadoop service would react.
Spark Checkpointing
Edit: Shortly after publishing Google reached out to me and informed me of a native Dataproc mode they have introduced in beta-form (at the time of writing) that performs this same functionality natively. I have documented it at the end of this article in the post-conclusion section.
First some background on how Spark handles moving workloads between different virtual machines or nodes that may exist for one operation and then will not for the next.
Spark has a concept called checkpointing which at a very high level is writing the current state of a RDD or DataFrame (think a dataset inside of Spark) to disk. This is useful because it makes a “bookmark” in your job so that if a virtual machine becomes unhealthy (dies or otherwise becomes unavailable) another instance can pick it up from the last bookmark and start from there.
In this case, if a cluster uses preemptible instances and it is reclaimed then the existence of a checkpoint will allow processing to continue mostly interrupted from that checkpoint on a different worker node.
Here is a quick example of how to set up a checkpoint with some PySpark code. It is setting the checkpoint directory, selecting out a column from a dataframe and checkpointing the result before writing it to a parquet file to HDFS:
spark.sparkContext.setCheckpointDir('gs://bucket/checkpoints')
events_df = df.select('event_type')
events_df.checkpoint()
events_df.write.format("parquet").save("/results/1234/")
Now assuming you have a Dataproc cluster with a single master, 2 worker nodes, and 2 preemptible instance worker nodes running the above code. If it is running and one of the preemptible instance worker nodes is reclaimed by Google during the final line of the example writing the results then Spark will detect the failure of the node and schedule it back onto another node. Now instead of starting over at the beginning of the example, it will start at the last line because it has a saved checkpoint right before that line.
This is a very simple example, but when you have a Spark job that has 100+ operations that may take 5 minutes each to run this can be a lifesaver especially with a large fleet of preemptible instances that might have any number of them disappearing between operations.
The Experiment of a Long-Running Spark Job on Dataproc
While this sounds incredible in theory there seems to be very little actual validation of this documented online running on Dataproc and this seems to be why there is a lot of uncertainty on this by customers considering Dataproc for their big data workloads.
TL;DR version: yes it works and runs the job to completion. Edit: Please check the post-conclusion for notes on an even better way to do this natively.
Here is how I set up this environment so it can be recreated for validation by others as required:
In order to test this and not let any potential preemptible actions slip by, I created a test environment that would be theoretically running a Spark job 24/7 to see what occurred when a preemptible VM was reclaimed and/or replaced.
This test environment consists of a Dataproc cluster with a master node, 2 worker nodes, and 2 preemptible instance worker nodes, a batch (non-streaming) Spark job that runs in a little over 30 minutes, and a Cloud Scheduler job that runs the Spark job every 30 minutes so that it would run as closely to 24/7 as possible. I chose to use N1 vCPUs on the worker nodes since they are older and had a higher chance of being reclaimed more often, it turns out E2 instances are reclaimed a lot less than N1 instances. This Spark job is a very basic job where I pulled an open data set from BigQuery and performed a multitude of random expensive operations, such as joins, cross joins, random sample aggregations, etc., on it to simulate a real data processing job that would spread the processing out across all nodes in the cluster.
To monitor when a preemptible instance was reclaimed and/or replaced I created a custom metric for monitoring on the managed instance group Dataproc creates for the cluster (the name is usually dataproc-cluster-<cluster name>) and put it on a dashboard graph. Monitoring the dips and rises on this graph showed when preemptible instances were reclaimed and/or replaced, which gave me the times to use for filtering the logs.
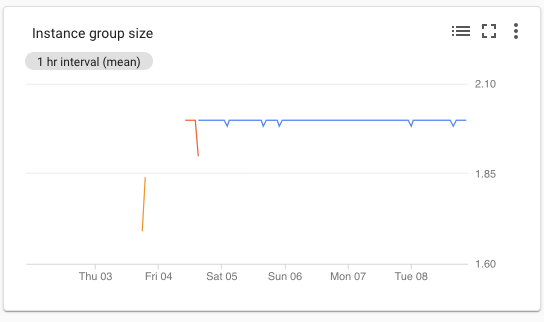
Once this was metric was validated with the instance and job’s master node logs, I started the process to run the job over the long Labor Day weekend here in the US and the following Tuesday to get a full weekend and a busy workday into the analysis. One thing to note is that preemptible instances run for a maximum of 24 hours at a time and will be reclaimed then a restart attempted at the 24-hour mark.
Over the course of this time, there were multiple dips and rises in the graph when the instances were reclaimed and replaced (see above graphic for an example). There were some “false positives” where the jobs were still starting up or were performing reads during the time the reclaim operations occurred that showed the intended behavior, they just were not very easy examples to show for the purpose of this article. Though a textbook example allowing easy visualization of the behavior did occur when right after a checkpoint operation and in the middle of writing dataframe to HDFS the preemptible instance doing the writing was reclaimed and restarted leaving some very clear logs behind showing its behavior.
The exception is thrown, from the Dataproc master log, was this:
20/09/08 20:05:36 WARN org.apache.spark.scheduler.TaskSetManager: Lost task 18.0 in stage 21.0 (TID 1490, cluster-4b46-sw-41l5.c.project-id.internal, executor 1): org.apache.spark.SparkException: Task failed while writing rows. at org.apache.spark.sql.execution.datasources.FileFormatWriter$.org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask(FileFormatWriter.scala:288) at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:198) at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:197) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87) at org.apache.spark.scheduler.Task.run(Task.scala:109) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:345) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)
This was exactly what I was looking for as it showed the machine being reclaimed during a write operation and conveniently right after a checkpoint operation had been done. After this exception there were a few sets of exceptions that raised warnings like these showing the failure to communicate with and schedule work on the reclaimed node (executor 2) confirming the reclaiming of a node:
20/09/08 20:06:41 WARN org.apache.spark.scheduler.cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: Requesting driver to remove executor 2 for reason Container marked as failed: container_1599249516460_0228_01_000003 on host: cluster-rand-sw-4c7x.c.project-id.internal. Exit status: -100. Diagnostics: Container released on a *lost* node 20/09/08 20:06:41 ERROR org.apache.spark.scheduler.cluster.YarnScheduler: Lost executor 2 on cluster-rand-sw-4c7x.c.project-id.internal: Container marked as failed: container_1599249516460_0228_01_000003 on host: cluster-rand-sw-4c7x.c.project-id.internal. Exit status: -100. Diagnostics: Container released on a *lost* node 20/09/08 20:06:41 WARN org.apache.spark.scheduler.TaskSetManager: Lost task 73.0 in stage 63.0 (TID 9855, cluster-rand-sw-4c7x.c.project-id.internal, executor 2): ExecutorLostFailure (executor 2 exited caused by one of the running tasks) Reason: Container marked as failed: container_1599249516460_0228_01_000003 on host: cluster-rand-sw-4c7x.c.project-id.internal. Exit status: -100. Diagnostics: Container released on a *lost* node 20/09/08 20:06:41 WARN org.apache.spark.scheduler.TaskSetManager: Lost task 74.0 in stage 63.0 (TID 9860, cluster-rand-sw-4c7x.c.project-id.internal, executor 2): ExecutorLostFailure (executor 2 exited caused by one of the running tasks) Reason: Container marked as failed: container_1599249516460_0228_01_000003 on host: cluster-rand-sw-4c7x.c.project-id.internal. Exit status: -100. Diagnostics: Container released on a *lost* node 20/09/08 20:06:41 WARN org.apache.spark.ExecutorAllocationManager: Attempted to mark unknown executor 2 idle
{
"insertId": "j96wpu5rh8p09edb5",
"jsonPayload": {
"message": "src: /10.128.0.9:55928, dest: /10.128.0.8:9866, bytes: 134217728, op: HDFS_WRITE, cliID: DFSClient_NONMAPREDUCE_-1208291363_17, offset: 0, srvID: 3b9b065f-15f4-49d7-a9ad-a5a2136e4ce1, blockid: BP-2070054281-10.128.0.10-1599249511859:blk_1073816330_75506, duration(ns): 556814753645",
"class": "org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace",
"filename": "hadoop-hdfs-datanode-cluster-rand-w-1.log"
},
"resource": {
"type": "cloud_dataproc_cluster",
"labels": {
"project_id": "project-id",
"cluster_uuid": "3de29175-f051-4aa5-9dee-e9925bfabec2",
"region": "us-central1",
"cluster_name": "cluster-rand"
}
},
"timestamp": "2020-09-08T19:06:15.035Z",
"severity": "INFO",
"labels": {
"compute.googleapis.com/resource_id": "5331347012694516446",
"compute.googleapis.com/resource_name": "cluster-rand-w-1",
"compute.googleapis.com/zone": "us-central1-a"
},
"logName": "projects/project-id/logs/hadoop-hdfs-datanode",
"receiveTimestamp": "2020-09-08T19:06:21.477492444Z"
}
{
"insertId": "j96wpu5rh8p09edb6",
"jsonPayload": {
"class": "org.apache.hadoop.hdfs.server.datanode.DataNode",
"filename": "hadoop-hdfs-datanode-cluster-rand-w-1.log",
"message": "PacketResponder: BP-2070054281-10.128.0.10-1599249511859:blk_1073816330_75506, type=LAST_IN_PIPELINE terminating"
},
"resource": {
"type": "cloud_dataproc_cluster",
"labels": {
"project_id": "project-id",
"cluster_uuid": "3de29175-f051-4aa5-9dee-e9925bfabec2",
"region": "us-central1",
"cluster_name": "cluster-rand"
}
},
"timestamp": "2020-09-08T19:06:15.035Z",
"severity": "INFO",
"labels": {
"compute.googleapis.com/resource_id": "5331347012694516446",
"compute.googleapis.com/zone": "us-central1-a",
"compute.googleapis.com/resource_name": "cluster-rand-w-1"
},
"logName": "projects/project-id/logs/hadoop-hdfs-datanode",
"receiveTimestamp": "2020-09-08T19:06:21.477492444Z"
}
After a few seconds and a few sets of those exceptions, the job continued on as normal to pass a job success value back to Dataproc. I verified that the data had written correctly to the destination folder on HDFS showing that the operation did complete successfully as intended.
When I switched over to the logs for the new preemptible instance that replaced the reclaimed one I found it had started exactly where the processing on the reclaimed one had left off. Please note this was a random but excellent example as it pushed the task back onto the replacement instance instead of another worker node, this will not happen most of the time (1 out of 9 for me in this experiment). Here are the log entries from the new instance:
{
"insertId": "j96wpu5rh8p09edb5",
"jsonPayload": {
"message": "src: /10.128.0.9:55928, dest: /10.128.0.8:9866, bytes: 134217728, op: HDFS_WRITE, cliID: DFSClient_NONMAPREDUCE_-1208291363_17, offset: 0, srvID: 3b9b065f-15f4-49d7-a9ad-a5a2136e4ce1, blockid: BP-2070054281-10.128.0.10-1599249511859:blk_1073816330_75506, duration(ns): 556814753645",
"class": "org.apache.hadoop.hdfs.server.datanode.DataNode.clienttrace",
"filename": "hadoop-hdfs-datanode-cluster-rand-w-1.log"
},
"resource": {
"type": "cloud_dataproc_cluster",
"labels": {
"project_id": "project-id",
"cluster_uuid": "3de29175-f051-4aa5-9dee-e9925bfabec2",
"region": "us-central1",
"cluster_name": "cluster-rand"
}
},
"timestamp": "2020-09-08T19:06:15.035Z",
"severity": "INFO",
"labels": {
"compute.googleapis.com/resource_id": "5331347012694516446",
"compute.googleapis.com/resource_name": "cluster-rand-w-1",
"compute.googleapis.com/zone": "us-central1-a"
},
"logName": "projects/project-id/logs/hadoop-hdfs-datanode",
"receiveTimestamp": "2020-09-08T19:06:21.477492444Z"
}
{
"insertId": "j96wpu5rh8p09edb6",
"jsonPayload": {
"class": "org.apache.hadoop.hdfs.server.datanode.DataNode",
"filename": "hadoop-hdfs-datanode-cluster-rand-w-1.log",
"message": "PacketResponder: BP-2070054281-10.128.0.10-1599249511859:blk_1073816330_75506, type=LAST_IN_PIPELINE terminating"
},
"resource": {
"type": "cloud_dataproc_cluster",
"labels": {
"project_id": "project-id",
"cluster_uuid": "3de29175-f051-4aa5-9dee-e9925bfabec2",
"region": "us-central1",
"cluster_name": "cluster-rand"
}
},
"timestamp": "2020-09-08T19:06:15.035Z",
"severity": "INFO",
"labels": {
"compute.googleapis.com/resource_id": "5331347012694516446",
"compute.googleapis.com/zone": "us-central1-a",
"compute.googleapis.com/resource_name": "cluster-rand-w-1"
},
"logName": "projects/project-id/logs/hadoop-hdfs-datanode",
"receiveTimestamp": "2020-09-08T19:06:21.477492444Z"
}
While unfortunately, it does not write out any log entries showing it reading back from the checkpoint directory that I could find in any of the available logs, it did continue exactly where it had left off then completed the operations left in the job.
Conclusion
To conclude on this experiment Dataproc handled the reclaiming and the replacing of a preemptible instance node as expected by the design of Hadoop and Spark. Google’s engineers have done a wonderful job in ensuring that Dataproc seamlessly handles “failures” of worker nodes i.e. when a preemptible instance is reclaimed without warning.
Post-Conclusion: Dataproc Enhanced Flexibility Mode
After publishing this article I was shared details by a Googler about a beta project Google has that directly relates to what I shared here that I was unaware of when writing the article.
Google has a mode for Dataproc that is specifically built for Dataproc clusters that might lose their worker nodes, i.e. preemptible worker instances. This mode shuffles the data to the filesystem in a way to optimize it for worker nodes failing.
I would highly recommend looking into this mode as it further cements my conclusion above and shows Google has been silently optimizing this process as well.
Details of this product are located here: https://cloud.google.com/dataproc/docs/concepts/configuring-clusters/flex


