Cloud Intelligence™
Pourquoi vos coûts Amazon Redshift Concurrency Scaling ne cessent d'augmenter (et comment y remédier)
Cette page est également disponible en English, Deutsch, Español, Italiano, 日本語 et Português.









About Joseph Allam
Databases have been my craft for a long time — long before the cloud, and deep into it across AWS and GCP. I know what breaks, what costs too much, and what needs rethinking before it hurts. I also know how to bring AI into the work: into how databases are designed, operated, and accessed by the intelligent systems being built on top of them.
My personal pageLes hausses inattendues des coûts Amazon Redshift ressemblent souvent, au premier abord, à des pics isolés. En pratique, elles sont généralement dues à des profils de workloads qui poussent discrètement Concurrency Scaling au-delà de son rôle initial.
Concurrency Scaling est conçu pour ajouter de la capacité Redshift lorsque la demande de requêtes augmente, puis la retirer lorsque la demande retombe. C'est utile pour absorber des pics. Mais lorsqu'il reste actif sur de longues périodes, il se comporte moins comme une capacité de débordement et davantage comme du compute de base. Cela modifie en général le profil de coût du workload.
Cet article retrace une enquête Redshift inspirée d'un cas réel, où des dépenses élevées ressemblaient au départ à une croissance normale du workload. Un examen plus approfondi des données de facturation, de la configuration du cluster et des métriques CloudWatch a révélé un autre schéma : des workloads mixtes partageaient le même cluster, créant une pression CPU soutenue et déclenchant Concurrency Scaling la majeure partie de la journée.
Nous allons parcourir l'enquête, les métriques qui ont compté, les choix de configuration qui ont amplifié les coûts, ainsi que le plan de remédiation.
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Ce que vous retirerez de cet article
À la fin, vous disposerez d'un workflow concret pour :
- Identifier le cluster Redshift à l'origine des coûts
- Distinguer la pression CPU de la pression de file d'attente
- Repérer les cas où Concurrency Scaling sert de capacité de base
- Détecter les problèmes de routage WLM qui amplifient les coûts
- Bâtir un plan de remédiation par phases
Étape 1 : confirmer le facteur de coût avant tout changement
Lorsque les coûts Redshift augmentent de manière inattendue, la tentation est de se ruer sur l'optimisation des requêtes ou le redimensionnement du cluster. C'est risqué. L'optimisation des requêtes peut aider, et le redimensionnement peut s'avérer nécessaire à terme, mais ni l'un ni l'autre ne devrait être le premier réflexe.
La première question est plus simple :
Quelle ressource Redshift est réellement responsable de la hausse ?
Dans cette enquête, l'environnement comptait deux clusters Redshift provisionnés :
| Cluster | Rôle | Comportement des coûts |
|---|---|---|
analytics-production-cluster |
Workloads principaux : analytics, BI, applicatif, batch et ML | Coût élevé et forte variabilité |
batch-processing-cluster |
Workload batch dédié / mono-usage | Stable et prévisible |
Les données de facturation montraient que la quasi-totalité des dépenses et de la variabilité provenait du cluster d'analytics mixte. Le cluster batch, plus petit, affichait un coût stable, une faible activité de connexion et aucune utilisation de Concurrency Scaling.
Cette distinction comptait. Elle a permis de réduire rapidement le périmètre de l'enquête et d'éviter de perdre du temps sur un cluster qui ne contribuait pas véritablement au problème.
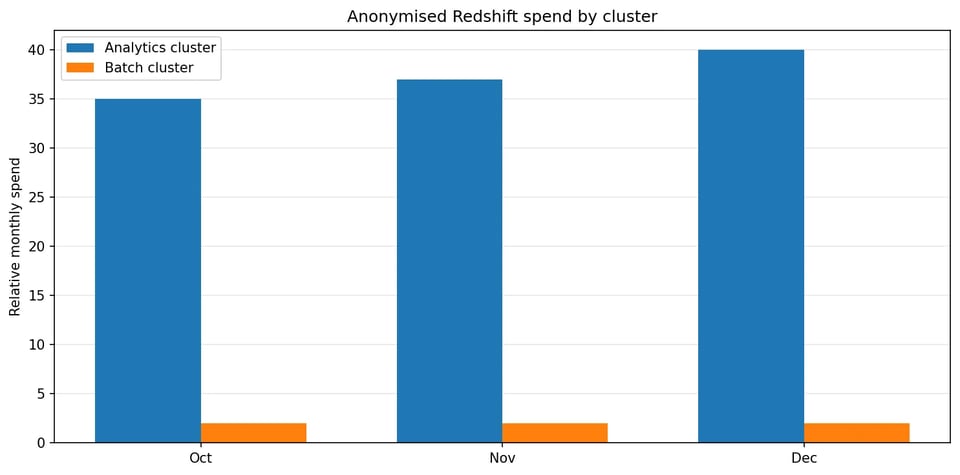
Presque toute la variabilité des dépenses provenait d'un seul cluster d'analytics à usage mixte.
Les données de coût montraient également que les plus grandes fluctuations étaient liées au compute et au comportement de scaling, plutôt qu'à la croissance du stockage. L'attention s'est donc portée sur le comportement à l'exécution, la pression CPU et l'activité de scaling.
L'hypothèse de travail était simple : le cluster d'analytics s'appuyait sur de la capacité de compute supplémentaire pendant des périodes plus longues que prévu.
Étape 2 : commencer par l'état du cluster
Une fois le cluster responsable des coûts identifié, l'étape suivante consistait à examiner sa posture.
Le cluster utilisait des nœuds RA3, du managed storage, Workload Management et Concurrency Scaling. Sur le plan de la configuration, rien ne semblait manifestement défaillant. Cela mérite qu'on s'y arrête. Un cluster Redshift peut paraître raisonnable du point de vue d'une configuration statique, tout en étant mal aligné avec la façon dont les workloads l'utilisent réellement.
La bonne question n'était pas le cluster est-il correctement configuré ? mais sa configuration est-elle alignée avec le profil du workload ? Cela a fait passer l'enquête de la revue de configuration statique à l'analyse du comportement à l'exécution.
Le cluster prenait en charge plusieurs types de workloads :
- Dashboards BI
- Analytics pilotés par les applications
- Pipelines de batch et de transformation
- Traitements ML ou liés à des campagnes
- Jobs de data engineering planifiés
Ce profil d'usage mixte est courant, mais il exige une isolation soignée des workloads. Le Workload Management (WLM) de Redshift définit des files d'attente de requêtes et y route le travail à l'exécution. AWS présente WLM comme le mécanisme de gestion des files de requêtes, des priorités et du routage des workloads.
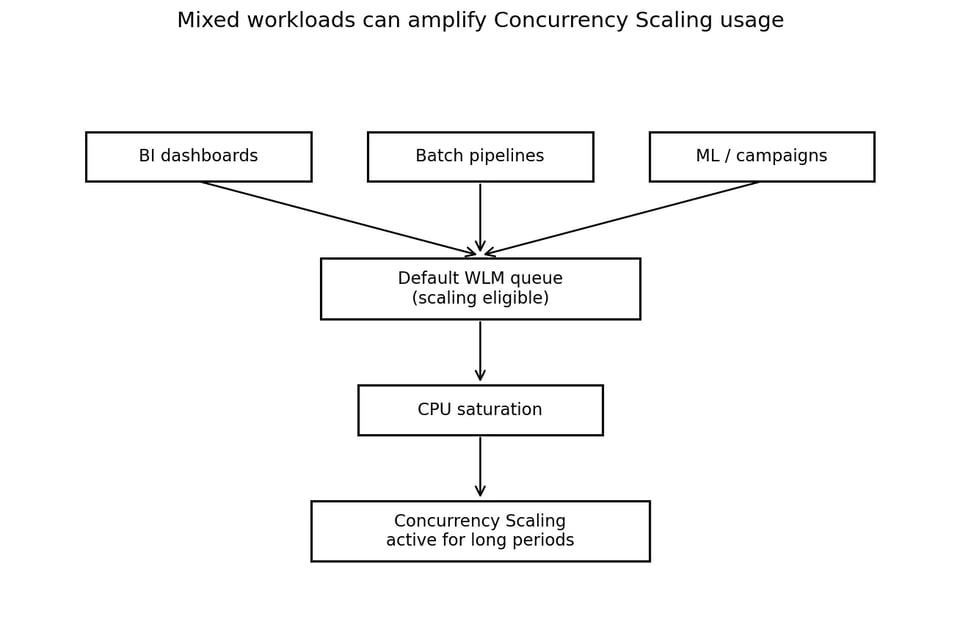
Quand plusieurs types de workloads partagent une même file éligible au scaling, Concurrency Scaling cesse d'être une capacité de pic.
Étape 3 : laisser parler CloudWatch
L'étape suivante consistait à examiner un petit ensemble de métriques CloudWatch pour Redshift.
L'objectif : répondre à une seule question. Ce cluster connaissait-il des pics brefs ou une pression soutenue ?
Les métriques les plus utiles étaient :
CPUUtilizationConcurrencyScalingActiveClustersConcurrencyScalingSecondsDatabaseConnections- Utilisation du disque
Le schéma est apparu rapidement.
Fenêtre chargée : 00:00 à 09:00 UTC
Cette période présentait les signes de pression les plus marqués : utilisation CPU au plus haut, nombre de connexions à la base le plus élevé, activité Concurrency Scaling la plus soutenue et chevauchement de plusieurs workloads. Cela suggérait que les workloads batch, dashboards et applicatifs entraient en collision sur la même plage horaire.
Fenêtre des heures ouvrées : 09:00 à 17:00 UTC
L'activité restait élevée, bien que généralement plus basse que la fenêtre matinale. Elle était probablement portée par la BI, l'usage des dashboards et l'analytics interactif.
Fenêtre de faible activité : 17:00 à 23:00 UTC
Cette période offrait davantage de marge : utilisation CPU plus faible, activité de scaling réduite, pression de connexion moindre. Elle constituait donc une candidate naturelle pour replanifier des workloads batch ou de transformation moins prioritaires.
Étape 4 : Concurrency Scaling ne se comportait pas comme une capacité de pic
Le constat principal portait sur le schéma d'utilisation de Concurrency Scaling. Le cluster n'y avait pas recours uniquement pendant de courts pics. Il l'utilisait la majeure partie de la journée, souvent avec plusieurs clusters de scaling actifs simultanément. Sur la période observée, Concurrency Scaling était actif environ 18 à 20 heures par jour.
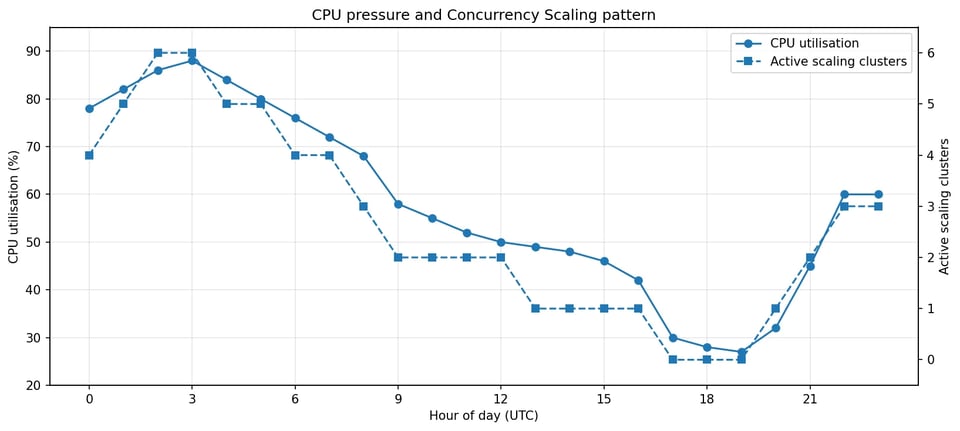
Concurrency Scaling suivait la pression CPU sur la majeure partie de la journée, et pas seulement durant les pics.
Cela a changé la nature de l'enquête. La question n'était plus pourquoi Redshift a-t-il scalé pendant un pic ? mais pourquoi ce cluster a-t-il besoin d'une capacité de débordement soutenue ?
Un usage prolongé de Concurrency Scaling est le signe que le workload peut être mal aligné avec la capacité de base, le routage des workloads ou la planification. À ce stade, l'enquête est passée de trouver le pic à comprendre la forme du workload.
Étape 5 : identifier le goulot d'étranglement
L'étape suivante consistait à déterminer ce qui causait réellement la pression de scaling. Plusieurs possibilités courantes existent :
- Saturation CPU
- Temps d'attente en file
- Pression disque
- Pression I/O
- Pression sur les connexions
- Routage de workloads inadapté
Les métriques pointaient nettement vers le CPU. L'utilisation CPU restait élevée, avec des pics fréquents sur les mêmes fenêtres que celles où Concurrency Scaling était actif. L'utilisation du disque restait saine. Le débit I/O et réseau était actif, mais ne semblait pas être le goulot principal.
Cela compte, car la solution à une saturation CPU diffère de celle à une pression de file ou de stockage. Le temps d'attente en file renvoie à la configuration WLM et à l'allocation des slots. La pression stockage renvoie au design des tables, au cycle de vie des données et à l'utilisation du managed storage. La pression CPU renvoie à l'efficacité des requêtes, à la planification des workloads, à l'isolation des files et à la capacité de compute de base.
Dans ce cas, le cluster effectuait beaucoup de travail, pendant longtemps, avec de nombreux workloads se disputant le CPU.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Étape 6 : la file WLM, véritable amplificateur de coût
Le constat suivant se trouvait dans le Workload Management. La configuration définissait plusieurs files, mais Concurrency Scaling était activé sur la file Default Auto WLM, qui faisait également office de fourre-tout pour les workloads non explicitement routés ailleurs.
Cela créait un schéma simple, mais coûteux :
Workloads non classés ou mixtes vFile Default Auto WLM (scaling activé) vPression CPU vConcurrency Scaling vCoût de compute plus élevéLe problème n'était pas qu'Auto WLM ou Concurrency Scaling soient en soi mauvais. Les deux sont des fonctionnalités utiles de Redshift. Le problème, c'est qu'un volume trop important de workloads mixtes transitait par la seule file ayant accès à la capacité de scaling.
Le routage WLM peut s'appuyer sur les user groups, les query groups et des règles de classification associées, ce qui en fait un point de contrôle clé pour l'isolation des workloads. Si dashboards BI, jobs batch, workloads ML et requêtes applicatives atterrissent tous dans la même file activée pour le scaling, Concurrency Scaling devient une issue de secours généralisée plutôt qu'un outil ciblé.
C'est ainsi que les coûts grimpent en silence.
Étape 7 : connexions et concurrence active, ce n'est pas la même chose
Autre observation utile : les connexions à la base. Le cluster présentait des pics réguliers du nombre de connexions, atteignant parfois des niveaux élevés durant les fenêtres chargées. À première vue, cela ressemblait à un possible problème de limite de connexions.
Or, les connexions à la base ne sont pas la même chose que les requêtes en cours d'exécution. Un cluster Redshift peut avoir de nombreuses connexions établies tandis qu'un sous-ensemble seulement du travail s'exécute à un instant donné, en fonction du workload management, de la mémoire, du CPU et de la configuration des files. Un nombre élevé de connexions reste un signal utile, car il indique souvent des rafraîchissements de dashboards, du fan-out applicatif ou des rafales de jobs. Mais en soi, il ne prouve pas une concurrence active de requêtes.
Dans cette enquête, les pics de connexions étaient utiles parce qu'ils coïncidaient avec la pression CPU et l'utilisation de Concurrency Scaling. Ils faisaient donc partie du tableau, sans être la cause racine à eux seuls.
Conclusion plus juste : de nombreux clients se connectaient et soumettaient du travail sur des fenêtres prévisibles, et le cluster n'avait pas assez de marge de compute effective pour ce mélange de workloads.
Étape 8 : la visibilité des requêtes dépend des privilèges de la base
Pour enquêter sur le comportement des requêtes, les tables et vues système de Redshift sont essentielles. Un point de confusion fréquent concerne la visibilité des requêtes. Dans les vues système Redshift, les superusers voient toutes les lignes, tandis que les utilisateurs réguliers ne voient généralement que leurs propres données. AWS précise cette règle de visibilité pour des vues telles que SYS_QUERY_HISTORY, STL_WLM_QUERY, STL_QUERY_METRICS et d'autres vues de monitoring associées.
Pour une analyse des workloads à l'échelle du cluster, la personne qui exécute les requêtes doit disposer des bonnes permissions sur la base.
Parmi les questions utiles à traiter :
- Quels utilisateurs consomment le plus de temps d'exécution ?
- Quelles requêtes s'exécutent durant la fenêtre chargée ?
- Quels workloads utilisent Concurrency Scaling ?
- Quelles files reçoivent l'essentiel du travail ?
- Quelles requêtes se répètent suffisamment pour mériter une optimisation ?
Lorsque c'est possible, AWS recommande les vues de monitoring SYS plus récentes, car elles sont formatées pour être plus simples à utiliser et à comprendre. Les anciennes vues STL et SVL restent largement utilisées et utiles pour les enquêtes, mais les vues SYS constituent un point de départ plus propre lorsqu'elles couvrent vos besoins.
Top requêtes par temps d'exécution
SELECT h.user_id, u.usename AS user_name, h.query_id, h.query_type, h.status, h.start_time, h.end_time, h.elapsed_time / 1000000.0 AS elapsed_seconds, h.execution_time / 1000000.0 AS execution_seconds, h.queue_time / 1000000.0 AS queue_seconds, h.service_class_name, h.compute_type, LEFT(h.query_text, 500) AS query_text_sampleFROM sys_query_history hLEFT JOIN pg_user u ON h.user_id = u.usesysidWHERE h.start_time >= dateadd(day, -7, current_date)ORDER BY h.execution_time DESCLIMIT 50;Top utilisateurs par temps d'exécution total
SELECT h.user_id, COALESCE(u.usename, 'unknown') AS user_name, COUNT(*) AS query_count, SUM(h.execution_time) / 1000000.0 AS total_execution_seconds, SUM(h.queue_time) / 1000000.0 AS total_queue_secondsFROM sys_query_history hLEFT JOIN pg_user u ON h.user_id = u.usesysidWHERE h.start_time >= dateadd(day, -7, current_date)GROUP BY h.user_id, u.usenameORDER BY total_execution_seconds DESC;Top requêtes par temps CPU
SVL_QUERY_METRICS_SUMMARY est utile ici, car elle inclut query_cpu_time, query_blocks_read et d'autres métriques pour les requêtes terminées. AWS documente query_cpu_time comme le temps CPU utilisé par la requête, en secondes.
SELECT h.user_id, COALESCE(u.usename, 'unknown') AS user_name, h.query_id, h.start_time, h.service_class_name, h.compute_type, m.query_cpu_time, m.query_execution_time, m.query_blocks_read, m.query_temp_blocks_to_disk, LEFT(h.query_text, 500) AS query_text_sampleFROM sys_query_history hJOIN svl_query_metrics_summary m ON h.query_id = m.queryLEFT JOIN pg_user u ON h.user_id = u.usesysidWHERE h.start_time >= dateadd(day, -7, current_date)ORDER BY m.query_cpu_time DESCLIMIT 50;Utilisation des files WLM
SELECT service_class_name, compute_type, COUNT(*) AS query_count, SUM(queue_time) / 1000000.0 AS total_queue_seconds, SUM(execution_time) / 1000000.0 AS total_execution_seconds, AVG(queue_time) / 1000000.0 AS avg_queue_seconds, AVG(execution_time) / 1000000.0 AS avg_execution_secondsFROM sys_query_historyWHERE start_time >= dateadd(day, -7, current_date)GROUP BY service_class_name, compute_typeORDER BY total_execution_seconds DESC;Requêtes ayant tourné sur Concurrency Scaling
Dans SYS_QUERY_HISTORY, la colonne compute_type indique si une requête s'est exécutée sur le cluster principal ou sur un cluster Concurrency Scaling, pour les clusters Redshift provisionnés. AWS documente primary-scale comme le type de compute d'une requête s'exécutant sur un cluster de concurrence.
SELECT h.user_id, COALESCE(u.usename, 'unknown') AS user_name, h.query_id, h.start_time, h.end_time, h.execution_time / 1000000.0 AS execution_seconds, h.service_class_name, h.compute_type, LEFT(h.query_text, 500) AS query_text_sampleFROM sys_query_history hLEFT JOIN pg_user u ON h.user_id = u.usesysidWHERE h.start_time >= dateadd(day, -7, current_date) AND h.compute_type = 'primary-scale'ORDER BY h.start_time DESCLIMIT 100;Ces requêtes ne sont pas la fin de l'optimisation. Elles en sont le début, celui de la priorisation. L'objectif : arrêter de deviner et identifier quels workloads doivent être isolés, replanifiés, optimisés ou autorisés à utiliser le scaling.
Étape 9 : plan de remédiation recommandé
Une fois le schéma clair, le plan de remédiation est devenu évident. L'objectif n'était pas de désactiver Concurrency Scaling à l'aveugle. Cela réduirait probablement les coûts, mais pourrait aussi augmenter l'attente en file et ralentir des workloads importants.
Une approche plus prudente est progressive : commencer par des changements de routage à faible risque, puis aller vers des décisions plus coûteuses à inverser.
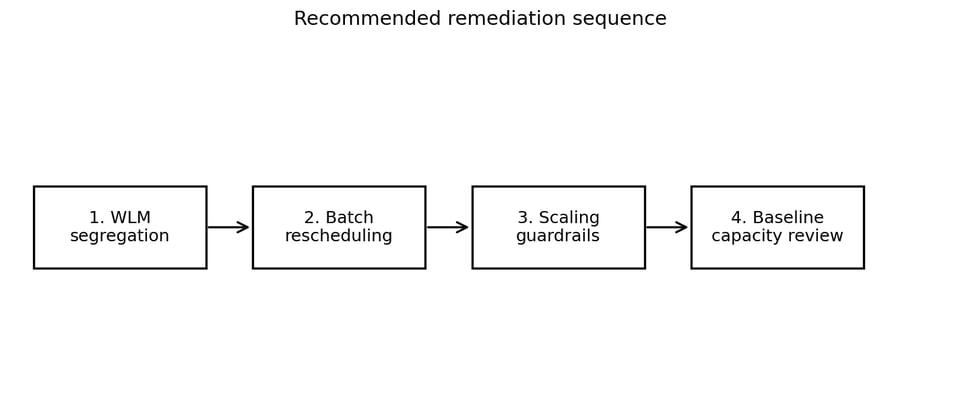
Un déroulé par phases garde les premières étapes peu coûteuses et réversibles.
1. Ségréger les workloads avec WLM
WLM doit refléter la priorité des workloads. Par exemple :
| Type de workload | Traitement possible |
|---|---|
| Dashboards BI | Priorité plus élevée, accès limité au scaling |
| Requêtes applicatives critiques | Priorité plus élevée, file protégée |
| Jobs batch | File dédiée, souvent sans scaling |
| Workloads ML ou de transformation | File dédiée, planifiée quand c'est possible |
| Analyse ad hoc | Priorité plus faible ou scaling restreint |
Cela empêche le travail batch peu prioritaire de consommer le même pool de scaling que les requêtes interactives ou critiques pour le business. C'est un changement de routage, donc réversible rapidement si une frontière de file s'avère mal placée.
2. Déplacer les jobs batch vers les fenêtres de faible activité
Les métriques mettaient clairement en évidence une fenêtre de faible activité plus tard dans la journée, ce qui constitue un levier opérationnel immédiat.
Tous les jobs batch n'ont pas besoin de tourner durant la période la plus chargée. Déplacer les jobs de transformation, ML ou reporting moins prioritaires vers des fenêtres plus calmes peut réduire la pression CPU de pic sans changer la taille du cluster. C'est souvent l'un des leviers de coût les plus pragmatiques, car il modifie le timing, pas l'architecture.
3. Ajouter des garde-fous à Concurrency Scaling
Avec des workloads correctement routés et planifiés, l'étape suivante consiste à plafonner Concurrency Scaling lui-même. Si on le laisse scaler trop largement, il peut protéger les performances mais générer des coûts imprévisibles.
Une première mesure raisonnable consiste à réduire le nombre maximal de clusters de scaling autorisés à un niveau contrôlé, puis à observer l'impact. Cela aide à répondre à :
- Quels workloads commencent à attendre ?
- Quels jobs sont réellement sensibles à la latence ?
- Quels workloads s'appuyaient sur la capacité de scaling sans justification métier ?
L'idée n'est pas de dégrader les performances, mais de faire du scaling une ressource maîtrisée, et non un comportement par défaut illimité.
4. Revoir la capacité de base
Si Concurrency Scaling reste actif sur de longues périodes après les changements WLM et de planification, le cluster de base est peut-être tout simplement sous-dimensionné pour le workload. Dans ce cas, ajouter de la capacité de base peut revenir moins cher que de s'appuyer en continu sur la capacité de débordement.
C'est contre-intuitif, mais fréquent : augmenter la capacité de base peut réduire le coût total si cela réduit matériellement l'usage soutenu de Concurrency Scaling.
L'essentiel est de prendre cette décision après avoir amélioré l'isolation et la planification des workloads. Sinon, vous risquez d'ajouter des nœuds tout en laissant un routage inefficace continuer à consommer la capacité de scaling.
5. Optimiser les requêtes sur la base de preuves
L'optimisation des requêtes doit se concentrer sur les workloads les plus importants :
- Temps d'exécution total élevé
- Consommation CPU élevée
- Exécution répétée et fréquente
- Exécution durant les fenêtres chargées
- Requêtes qui atterrissent dans des files éligibles au scaling
C'est là que l'analyse des tables système prend tout son sens. Optimisez les requêtes qui pèsent réellement sur le coût et la performance, pas celles qui semblent juste mal écrites.
À retenir
Cette enquête a confirmé quelques enseignements pratiques sur Redshift.
Concurrency Scaling ne doit pas devenir une capacité de base. S'il reste actif la majeure partie de la journée, il ne se comporte plus comme une capacité de pic. Il fait alors partie du modèle de compute en régime établi, et c'est un signal de coût.
Pression CPU et pression de file sont deux problèmes distincts. Un usage élevé de Concurrency Scaling ne signifie pas automatiquement qu'une file WLM en est la cause racine. Examinez ensemble le CPU, le temps d'attente en file, le disque, l'I/O et les schémas de connexion.
Le routage par la file par défaut peut coûter cher. Une file fourre-tout avec Concurrency Scaling activé peut discrètement devenir le principal amplificateur de coût. Le routage WLM doit correspondre à la priorité des workloads.
Le timing des workloads compte. Si jobs batch, dashboards, workloads ML et analytics applicatifs se chevauchent, la pression de scaling augmente. Déplacer les workloads batch non critiques vers des fenêtres plus calmes peut réduire les coûts sans rien changer aux fonctionnalités.
L'optimisation des requêtes doit suivre l'attribution. Avant d'optimiser des requêtes, identifiez quels utilisateurs, workloads et files consomment les ressources. Deviner fait généralement perdre du temps.
Pour conclure
L'optimisation des coûts Redshift se résume rarement à un seul réglage. Dans ce cas, le problème n'était ni un cluster défaillant, ni une seule requête mal écrite. C'était une combinaison de workloads mixtes, de collisions de timing prévisibles, de saturation CPU et d'un accès large à Concurrency Scaling via le chemin WLM par défaut.
L'apport le plus utile de l'enquête n'était aucune métrique prise isolément. C'était de les relier entre elles :
- Le rapport de coûts identifie le cluster
- CloudWatch met en évidence un scaling soutenu et une pression CPU
- La configuration WLM explique pourquoi le scaling est largement accessible
- Les tables système indiquent quels utilisateurs et requêtes prioriser
Si votre facture Redshift grimpe et que Concurrency Scaling a discrètement glissé du pic au régime établi, vous n'êtes pas seul. C'est précisément le type d'enquête sur les coûts que DoiT mène chaque semaine avec des clients AWS. Notre équipe de plus de 100 experts cloud peut vous aider à identifier les facteurs, à ségréger les workloads et à remettre Concurrency Scaling à sa juste place. Contactez-nous.