Cloud Intelligence™
Por que os custos de Concurrency Scaling do Amazon Redshift não param de crescer (e como resolver)
Esta página também está disponível em English, Deutsch, Español, Français, Italiano e 日本語.









About Joseph Allam
Databases have been my craft for a long time — long before the cloud, and deep into it across AWS and GCP. I know what breaks, what costs too much, and what needs rethinking before it hurts. I also know how to bring AI into the work: into how databases are designed, operated, and accessed by the intelligent systems being built on top of them.
My personal pageAumentos inesperados de custo no Amazon Redshift costumam parecer picos isolados à primeira vista. Na prática, eles quase sempre vêm de padrões de workloads que empurram o Concurrency Scaling além do papel para o qual ele foi pensado.
O Concurrency Scaling foi projetado para adicionar capacidade ao Redshift quando a demanda por consultas sobe e remover essa capacidade quando a demanda cai. Ele é útil para rajadas. Mas, quando fica ativo por longos períodos, passa a se comportar menos como capacidade de overflow e mais como compute base. E isso muda o perfil de custo do workload.
Este post mostra uma investigação no Redshift, baseada em um caso real, em que o aumento de gastos parecia, à primeira vista, crescimento normal do workload. Uma análise mais detida dos dados de billing, da configuração do cluster e das métricas do CloudWatch revelou outro padrão: workloads mistos dividiam o mesmo cluster, gerando pressão sustentada de CPU e disparando o Concurrency Scaling durante a maior parte do dia.
Vamos percorrer a investigação, as métricas que importaram, as escolhas de configuração que amplificaram o custo e o plano de remediação.
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
O que você vai tirar deste artigo
Ao final, você deve sair com um fluxo de trabalho prático para:
- Identificar qual cluster do Redshift está puxando o custo
- Separar pressão de CPU de pressão de fila
- Perceber quando o Concurrency Scaling está sendo usado como capacidade base
- Detectar problemas de roteamento no WLM que amplificam o custo
- Montar um plano de remediação em fases
Passo 1: confirme o que está puxando o custo antes de mexer em qualquer coisa
Quando os custos do Redshift sobem do nada, a tentação é partir direto para tuning de consultas ou redimensionamento do cluster. Isso é arriscado. Tuning pode ajudar e redimensionar pode até ser necessário em algum momento, mas nenhum dos dois deveria ser o primeiro passo.
A primeira pergunta é mais simples:
Qual recurso do Redshift é, de fato, o responsável pelo aumento?
Nesta investigação, o ambiente tinha dois clusters Redshift provisionados:
| Cluster | Função | Comportamento de custo |
|---|---|---|
analytics-production-cluster |
Workloads principais de analytics, BI, aplicação, batch e ML | Custo alto e alta variabilidade |
batch-processing-cluster |
Workload dedicado de batch / propósito único | Estável e previsível |
Os dados de billing mostraram que quase todo o gasto e toda a variabilidade vinham do cluster de analytics de uso misto. O cluster menor, voltado a batch, tinha custo estável, pouca atividade de conexão e nenhum uso de Concurrency Scaling.
Essa distinção fez diferença. Restringiu o escopo da investigação rapidamente e evitou perda de tempo com um cluster que não contribuía de forma relevante para o problema.
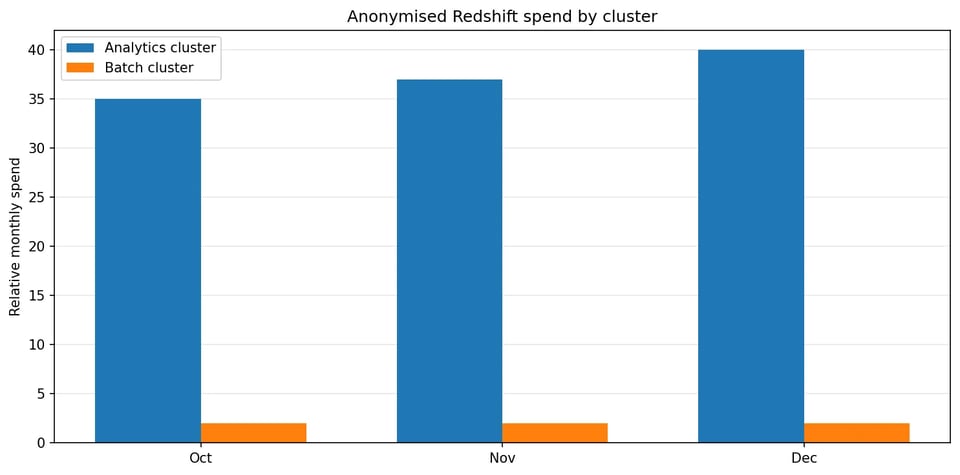
Quase toda a variabilidade de gasto vinha de um único cluster de analytics de uso misto.
Os dados de custo também mostraram que as maiores oscilações estavam ligadas ao comportamento de compute e scaling, e não ao crescimento de storage. Isso direcionou o foco para o comportamento em runtime, a pressão de CPU e a atividade de scaling.
A hipótese de trabalho era simples: o cluster de analytics estava dependendo de capacidade adicional de compute por períodos mais longos do que o esperado.
Passo 2: comece pela postura do cluster
Depois de identificar o cluster que estava puxando o custo, o próximo passo foi revisar sua postura.
O cluster usava nós RA3, managed storage, Workload Management e Concurrency Scaling. No nível de configuração, nada parecia obviamente quebrado. Vale uma pausa aqui. Um cluster Redshift pode parecer razoável em uma visão estática de configuração e, ainda assim, estar mal alinhado com a forma como os workloads realmente o utilizam.
A pergunta útil não era o cluster está configurado corretamente?. Era a configuração do cluster está alinhada com o padrão do workload?. Isso tirou a investigação da revisão estática de configuração e a colocou no comportamento em runtime.
O cluster atendia a vários tipos de workload:
- Dashboards de BI
- Analytics orientado a aplicações
- Pipelines de batch e transformação
- Processamento de ML ou ligado a campanhas
- Jobs agendados de data engineering
Esse padrão de uso misto é comum, mas exige isolamento cuidadoso de workloads. O Workload Management (WLM) do Redshift define filas de consultas e roteia o trabalho para essas filas em runtime. A AWS descreve o WLM como o mecanismo para gerenciar filas de consultas, prioridades e roteamento de workloads.
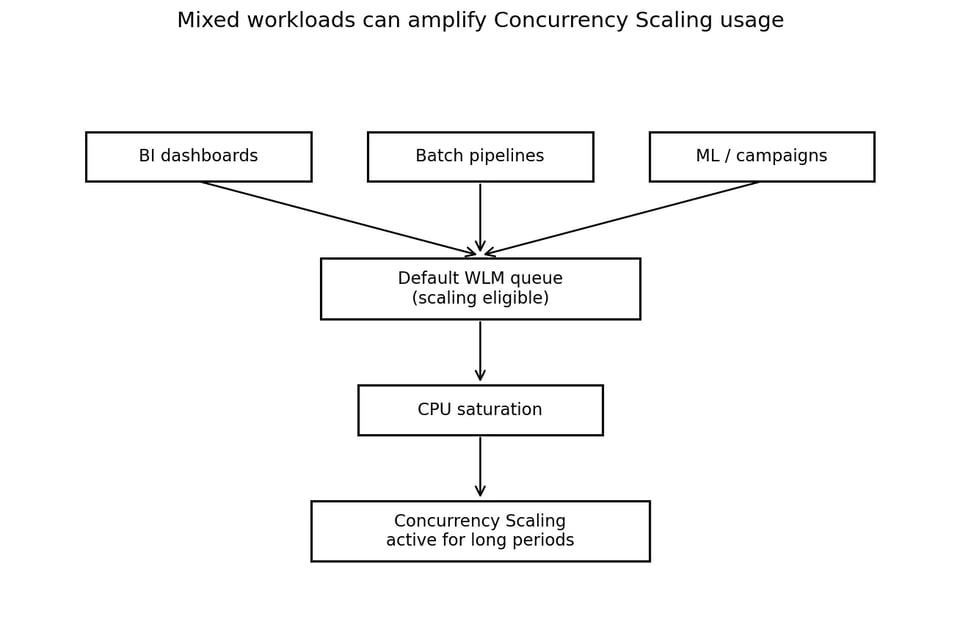
Quando vários tipos de workload dividem uma única fila elegível para scaling, o Concurrency Scaling deixa de ser capacidade de burst.
Passo 3: deixe o CloudWatch contar a história
O próximo passo foi revisar um conjunto enxuto de métricas do CloudWatch para o Redshift.
O objetivo era responder a uma pergunta: este cluster estava enfrentando rajadas curtas ou pressão sustentada?
As métricas mais úteis foram:
CPUUtilizationConcurrencyScalingActiveClustersConcurrencyScalingSecondsDatabaseConnections- Utilização de disco
O padrão ficou claro rapidamente.
Janela de pico: 00:00 às 09:00 UTC
Esse período mostrou os sinais mais fortes de pressão: maior utilização de CPU, maior número de conexões ao banco, maior atividade sustentada de Concurrency Scaling e múltiplos workloads se sobrepondo. Isso sugeria que workloads de batch, dashboards e aplicação estavam colidindo na mesma janela de tempo.
Janela de horário comercial: 09:00 às 17:00 UTC
A atividade se manteve elevada, embora normalmente abaixo da janela anterior. Provavelmente puxada por BI, uso de dashboards e analytics interativo.
Janela de baixa atividade: 17:00 às 23:00 UTC
Esse período mostrou mais folga disponível: menor utilização de CPU, menos atividade de scaling, menor pressão de conexões. Um candidato natural para reagendar workloads de batch ou transformação de menor prioridade.
Passo 4: o Concurrency Scaling não estava se comportando como capacidade de burst
A maior descoberta foi o padrão de uso do Concurrency Scaling. O cluster não estava usando o Concurrency Scaling só em picos curtos. Estava usando durante a maior parte do dia, muitas vezes com vários clusters de scaling ativos ao mesmo tempo. No período observado, o Concurrency Scaling ficou ativo por cerca de 18 a 20 horas por dia.
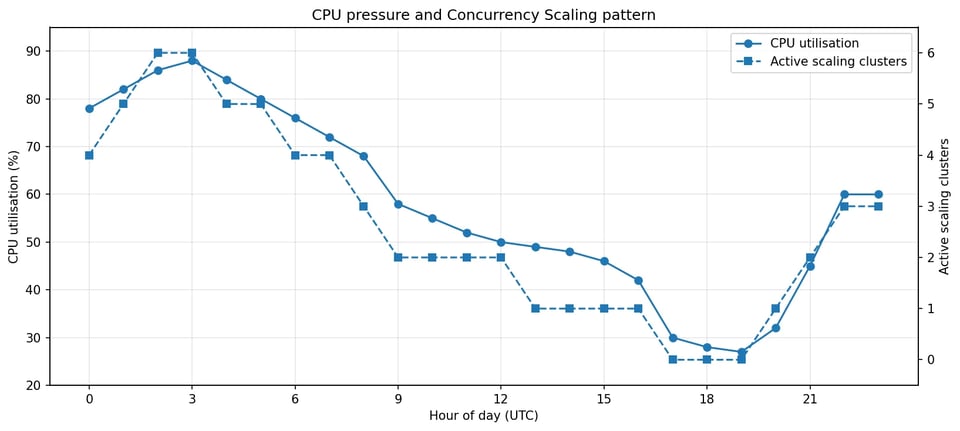
O Concurrency Scaling acompanhou a pressão de CPU durante a maior parte do dia, e não apenas nos picos.
Isso mudou a natureza da investigação. A pergunta já não era por que o Redshift escalou durante um pico?. Era por que esse cluster precisa de capacidade de overflow sustentada?.
O uso prolongado do Concurrency Scaling é um sinal de que o workload pode estar desalinhado com a capacidade base, com o roteamento de workloads ou com o agendamento. Nesse ponto, a investigação saiu de "encontrar o pico" e foi para "entender o formato do workload".
Passo 5: identifique o gargalo
O próximo passo foi descobrir o que estava, de fato, causando a pressão de scaling. Existem várias possibilidades comuns:
- Saturação de CPU
- Tempo de espera em fila
- Pressão de disco
- Pressão de I/O
- Pressão de conexões
- Roteamento ruim de workloads
As métricas apontavam fortemente para CPU. A utilização se mantinha alta, com picos frequentes nas mesmas janelas em que o Concurrency Scaling estava ativo. A utilização de disco continuava saudável. I/O e throughput de rede estavam ativos, mas não pareciam ser o gargalo principal.
Isso importa porque a correção para saturação de CPU é diferente da correção para pressão de fila ou de storage. Tempo de espera em fila aponta para a configuração do WLM e a alocação de slots. Pressão de storage aponta para design de tabelas, ciclo de vida dos dados e uso do managed storage. Pressão de CPU aponta para eficiência das consultas, agendamento de workloads, isolamento de filas e capacidade base de compute.
Neste caso, o cluster estava fazendo muito trabalho, por muito tempo, com muitos workloads disputando CPU.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Passo 6: a fila do WLM era o amplificador de custo
A próxima descoberta estava no Workload Management. A configuração tinha várias filas definidas, mas o Concurrency Scaling estava habilitado na fila Default do Auto WLM, e essa fila também funcionava como catch-all para workloads não roteados explicitamente para outro lugar.
Isso criou um padrão simples, porém caro:
Workloads não classificados ou mistos vFila Default do Auto WLM (scaling habilitado) vPressão de CPU vConcurrency Scaling vMaior custo de computeO problema não era o Auto WLM ou o Concurrency Scaling estarem "errados". Os dois são recursos úteis do Redshift. O problema era que workload misto demais estava passando pela única fila com acesso à capacidade de scaling.
O roteamento do WLM pode ser baseado em grupos de usuários, grupos de consultas e regras de classificação relacionadas, o que o torna um ponto-chave de controle para isolamento de workloads. Se dashboards de BI, jobs de batch, workloads de ML e consultas de aplicação caem todos na mesma fila habilitada para scaling, o Concurrency Scaling vira uma válvula de escape ampla, em vez de uma ferramenta direcionada.
É assim que os custos crescem silenciosamente.
Passo 7: conexões não são a mesma coisa que concorrência ativa
Outra observação útil envolveu as conexões ao banco. O cluster apresentava picos regulares no número de conexões, às vezes em níveis altos durante as janelas de pico. À primeira vista, parecia um possível problema de limite de conexões.
Mas conexões ao banco não são a mesma coisa que consultas em execução. Um cluster Redshift pode ter muitas conexões estabelecidas enquanto apenas um subconjunto do trabalho é executado em determinado momento, de acordo com o workload management, memória, CPU e configuração de filas. Um alto número de conexões ainda é um sinal útil, porque costuma indicar atualizações de dashboard, fan-out de aplicação ou rajadas de jobs. Por si só, não é prova de concorrência ativa de consultas.
Nesta investigação, os picos de conexão foram úteis porque coincidiam com a pressão de CPU e o uso do Concurrency Scaling. Isso os tornou parte da história, mas não a causa raiz por si só.
A conclusão melhor: muitos clientes se conectavam e enviavam trabalho em janelas previsíveis, e o cluster não tinha headroom efetivo de compute suficiente para esse mix de workloads.
Passo 8: a visibilidade das consultas depende dos privilégios no banco
Ao investigar o comportamento das consultas, as tabelas e views de sistema do Redshift são essenciais. Um ponto comum de confusão é justamente a visibilidade. Nas views de sistema do Redshift, superusers veem todas as linhas, enquanto usuários comuns geralmente veem apenas seus próprios dados. A AWS registra essa regra de visibilidade para views como SYS_QUERY_HISTORY, STL_WLM_QUERY, STL_QUERY_METRICS e outras views de monitoramento relacionadas.
Para uma análise de workload em todo o cluster, quem executa as consultas precisa ter as permissões corretas no banco.
Algumas perguntas úteis a responder:
- Quais usuários consomem mais tempo de execução?
- Quais consultas rodam durante a janela de pico?
- Quais workloads usam o Concurrency Scaling?
- Quais filas recebem a maior parte do trabalho?
- Quais consultas se repetem com frequência suficiente para valer a pena otimizar?
Quando disponíveis, a AWS recomenda as views de monitoramento mais novas, do tipo SYS, porque são formatadas para serem mais fáceis de usar e entender. As views mais antigas STL e SVL continuam amplamente usadas e úteis para investigações, mas as views SYS são um ponto de partida mais limpo quando cobrem o que você precisa.
Top consultas por tempo de execução
SELECT h.user_id, u.usename AS user_name, h.query_id, h.query_type, h.status, h.start_time, h.end_time, h.elapsed_time / 1000000.0 AS elapsed_seconds, h.execution_time / 1000000.0 AS execution_seconds, h.queue_time / 1000000.0 AS queue_seconds, h.service_class_name, h.compute_type, LEFT(h.query_text, 500) AS query_text_sampleFROM sys_query_history hLEFT JOIN pg_user u ON h.user_id = u.usesysidWHERE h.start_time >= dateadd(day, -7, current_date)ORDER BY h.execution_time DESCLIMIT 50;Top usuários por tempo total de execução
SELECT h.user_id, COALESCE(u.usename, 'unknown') AS user_name, COUNT(*) AS query_count, SUM(h.execution_time) / 1000000.0 AS total_execution_seconds, SUM(h.queue_time) / 1000000.0 AS total_queue_secondsFROM sys_query_history hLEFT JOIN pg_user u ON h.user_id = u.usesysidWHERE h.start_time >= dateadd(day, -7, current_date)GROUP BY h.user_id, u.usenameORDER BY total_execution_seconds DESC;Top consultas por tempo de CPU
A SVL_QUERY_METRICS_SUMMARY é útil aqui porque inclui query_cpu_time, query_blocks_read e métricas relacionadas para consultas concluídas. A AWS descreve query_cpu_time como o tempo de CPU usado pela consulta, em segundos.
SELECT h.user_id, COALESCE(u.usename, 'unknown') AS user_name, h.query_id, h.start_time, h.service_class_name, h.compute_type, m.query_cpu_time, m.query_execution_time, m.query_blocks_read, m.query_temp_blocks_to_disk, LEFT(h.query_text, 500) AS query_text_sampleFROM sys_query_history hJOIN svl_query_metrics_summary m ON h.query_id = m.queryLEFT JOIN pg_user u ON h.user_id = u.usesysidWHERE h.start_time >= dateadd(day, -7, current_date)ORDER BY m.query_cpu_time DESCLIMIT 50;Uso das filas do WLM
SELECT service_class_name, compute_type, COUNT(*) AS query_count, SUM(queue_time) / 1000000.0 AS total_queue_seconds, SUM(execution_time) / 1000000.0 AS total_execution_seconds, AVG(queue_time) / 1000000.0 AS avg_queue_seconds, AVG(execution_time) / 1000000.0 AS avg_execution_secondsFROM sys_query_historyWHERE start_time >= dateadd(day, -7, current_date)GROUP BY service_class_name, compute_typeORDER BY total_execution_seconds DESC;Consultas que rodaram em Concurrency Scaling
Na SYS_QUERY_HISTORY, a coluna compute_type identifica se uma consulta rodou no cluster principal ou em um cluster de Concurrency Scaling, para clusters Redshift provisionados. A AWS descreve primary-scale como o compute type de uma consulta que roda em um cluster de concorrência.
SELECT h.user_id, COALESCE(u.usename, 'unknown') AS user_name, h.query_id, h.start_time, h.end_time, h.execution_time / 1000000.0 AS execution_seconds, h.service_class_name, h.compute_type, LEFT(h.query_text, 500) AS query_text_sampleFROM sys_query_history hLEFT JOIN pg_user u ON h.user_id = u.usesysidWHERE h.start_time >= dateadd(day, -7, current_date) AND h.compute_type = 'primary-scale'ORDER BY h.start_time DESCLIMIT 100;Essas consultas não são o fim da otimização. São o início da priorização. A ideia é parar de chutar e identificar quais workloads devem ser isolados, reagendados, ajustados ou autorizados a usar scaling.
Passo 9: plano de remediação recomendado
Com o padrão claro, o plano de remediação ficou direto. O objetivo não era desligar o Concurrency Scaling às cegas. Isso provavelmente reduziria custo, mas também poderia aumentar o tempo em fila e atrasar workloads importantes.
Uma abordagem mais segura é em fases, começando por mudanças de roteamento de baixo risco e avançando para decisões cujo custo de reversão é maior.
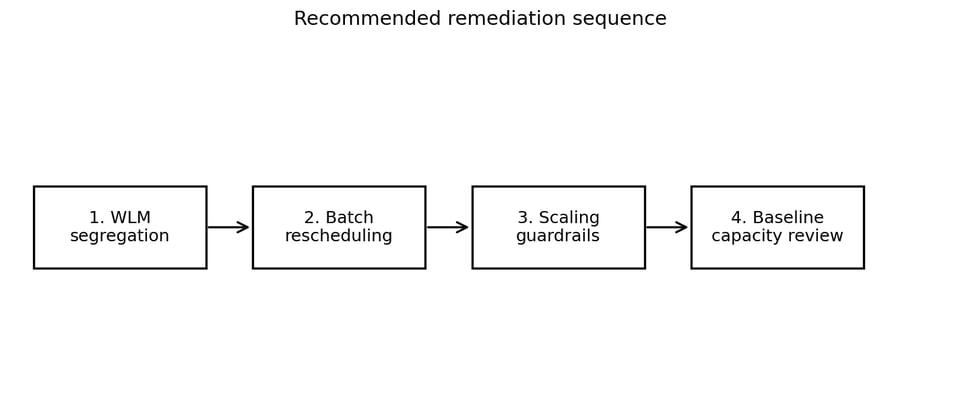
Uma ordem em fases mantém os primeiros passos baratos e reversíveis.
1. Segregue workloads com o WLM
O WLM deve refletir a prioridade dos workloads. Por exemplo:
| Tipo de workload | Tratamento possível |
|---|---|
| Dashboards de BI | Maior prioridade, acesso limitado a scaling |
| Consultas críticas de aplicação | Maior prioridade, fila protegida |
| Jobs de batch | Fila dedicada, geralmente sem scaling |
| Workloads de ML ou transformação | Fila dedicada, agendados sempre que possível |
| Análise ad hoc | Menor prioridade ou scaling restrito |
Isso evita que jobs de batch de menor prioridade consumam o mesmo pool de scaling usado por consultas interativas ou críticas para o negócio. É uma mudança de roteamento, então pode ser revertida rapidamente se algum limite de fila estiver errado.
2. Mova jobs de batch para janelas de baixa atividade
As métricas mostraram uma janela clara de baixa atividade no fim do dia, o que cria uma alavanca operacional imediata.
Nem todo job de batch precisa rodar no horário mais movimentado. Mover jobs de transformação, ML ou reporting de menor prioridade para janelas mais calmas pode reduzir a pressão de CPU nos picos sem mexer no tamanho do cluster. Essa costuma ser uma das alavancas de custo mais práticas, porque muda o timing, não a arquitetura.
3. Coloque guardrails no Concurrency Scaling
Com os workloads bem roteados e com o timing ajustado, o próximo passo é limitar o próprio Concurrency Scaling. Se ele puder escalar de forma ampla demais, protege a performance, mas cria custo imprevisível.
Um primeiro passo razoável é reduzir o número máximo de clusters de scaling permitidos a um nível controlado e, então, observar o impacto. Isso ajuda a responder:
- Quais workloads começam a esperar?
- Quais jobs são realmente sensíveis a latência?
- Quais workloads dependiam de capacidade de scaling sem motivo de negócio?
O objetivo não é degradar a performance. É tornar o scaling um recurso intencional, e não um default ilimitado.
4. Revisite a capacidade base
Se o Concurrency Scaling continuar ativo por longos períodos depois das mudanças no WLM e no agendamento, o cluster base pode estar simplesmente subdimensionado para o workload. Nesse caso, adicionar capacidade base pode ser mais barato do que depender continuamente de capacidade de overflow.
É contraintuitivo, mas comum: aumentar a capacidade base pode reduzir o custo total se reduzir significativamente o uso sustentado do Concurrency Scaling.
O ponto-chave é tomar essa decisão depois de melhorar o isolamento e o agendamento dos workloads. Caso contrário, você corre o risco de adicionar nós enquanto ainda permite que um roteamento ineficiente consuma capacidade de scaling.
5. Ajuste consultas com base em evidências
A otimização de consultas deve focar nos workloads que mais importam:
- Tempo total de execução alto
- Alto consumo de CPU
- Execução repetida e frequente
- Execução durante janelas de pico
- Consultas que caem em filas habilitadas para scaling
É aqui que a análise das tabelas de sistema se torna útil. Otimize as consultas que afetam de fato custo e performance, e não as que apenas parecem feias.
Principais aprendizados
Esta investigação reforçou algumas lições práticas sobre o Redshift.
O Concurrency Scaling não deveria virar capacidade base. Se ele fica ativo durante a maior parte do dia, já não se comporta como capacidade de burst. Passou a fazer parte do modelo de compute em regime permanente, e isso é um sinal de custo.
Pressão de CPU e pressão de fila são problemas diferentes. Uso alto do Concurrency Scaling não significa automaticamente que a fila do WLM é a causa raiz. Verifique CPU, tempo de espera em fila, disco, I/O e padrões de conexão em conjunto.
O roteamento default de fila pode sair caro. Uma fila catch-all com Concurrency Scaling habilitado pode silenciosamente se tornar o principal amplificador de custo. O roteamento no WLM precisa refletir a prioridade dos workloads.
O timing dos workloads importa. Quando jobs de batch, dashboards, workloads de ML e analytics de aplicação se sobrepõem, a pressão de scaling aumenta. Mover workloads de batch não críticos para janelas mais calmas pode reduzir custo sem mexer em funcionalidade.
O tuning de consultas deve vir depois da atribuição. Antes de ajustar consultas, identifique quais usuários, workloads e filas estão puxando o consumo de recursos. Chutar costuma ser desperdício de tempo.
Considerações finais
Otimização de custo no Redshift raramente se resume a uma única configuração. Neste caso, o problema não era um cluster quebrado nem uma única consulta ruim. Era uma combinação de workloads mistos, colisões previsíveis de timing, saturação de CPU e acesso amplo ao Concurrency Scaling pelo caminho default do WLM.
A parte mais útil da investigação não foi uma única métrica. Foi conectá-las:
- O relatório de custos identifica o cluster
- O CloudWatch mostra scaling sustentado e pressão de CPU
- A configuração do WLM explica por que o scaling está amplamente disponível
- As tabelas de sistema identificam quais usuários e consultas priorizar
Se a sua conta do Redshift está subindo e o Concurrency Scaling deixou de ser burst para virar capacidade base sem você perceber, saiba que você não está sozinho. Esse é o tipo de investigação de custos que a DoiT faz toda semana com clientes da AWS. Nosso time de mais de 100 especialistas em nuvem pode ajudar você a identificar os fatores que puxam o custo, segregar workloads e devolver o Concurrency Scaling ao papel para o qual ele foi pensado. Fale com a gente.